淘宝异构数据源数据交换工具 DataX
DataX是什么?
DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换,由淘宝数据平台部门完成。

DataX用来解决什么?
目前成熟的数据导入导出工具比较多,但是一般都只能用于数据导入或者导出,并且只能支持一个或者几个特定类型的数据库。这样带来的一个问题是,如果我们拥有很多不同类型的数据库/文件系统(Mysql/Oracle/Rac/Hive/Other…),并且经常需要在它们之间导入导出数据,那么我们可能 要开发/维护/学习使用一批这样的工具(jdbcdump/dbloader/multithread/getmerge+sqlloader /mysqldumper…)。而且以后每增加一种库类型,我们需要的工具数目将线性增长。(当我们需要将mysql的数据导入oracle的时候,有没 有过想从jdbcdump和dbloader上各掰下来一半拼在一起到冲动?) 这些工具有些使用文件中转数据,有些使用管道,不同程度的为数据中转带来额外开销,效率差别很非常大。很多工具也无法满足ETL任务中常见的需求,比如日 期格式转化,特性字符的转化,编码转换。另外,有些时候,我们希望在一个很短的时间窗口内,将一份数据从一个数据库同时导出到多个不同类型的数据库。 DataX正是为了解决这些问题而生。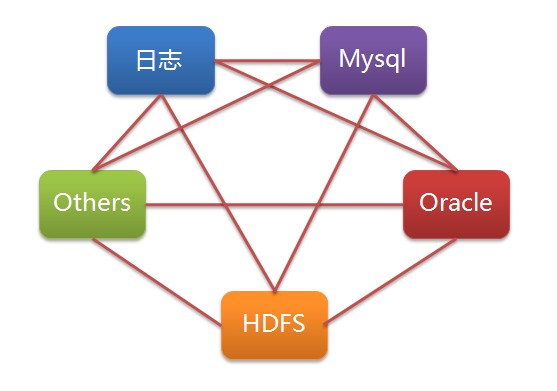
(问题: 新增第n+1个数据源,是不是要新开发n个数据同步工具 ?)

我们只需要针对新增的数据源开发的一套Reader/Writer插件,即可实现任意数据的互导
DataX特点?
- 在异构的数据库/文件系统之间高速交换数据
- 采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问
- 运行模式:stand-alone
- 数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC
- 开放式的框架,开发者可以在极短的时间开发一个新插件以快速支持新的数据库/文件系统。(具体参见《DataX插件开发指南》)
DataX结构模式(框架+插件)

- Job: 一道数据同步作业
- Splitter: 作业切分模块,将一个大任务与分解成多个可以并发的小任务.
- Sub-job: 数据同步作业切分后的小任务
- Reader(Loader): 数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX
- Storage: Reader和Writer通过Storage交换数据
- Writer(Dumper): 数据写出模块,负责将数据从DataX导入至目的数据地
DataX框架内部通过双缓冲队列、线程池封装等技术,集中处理了高速数据交换遇到的问题,提供简单的接口与插件交互,插件分为Reader和 Writer两类,基于框架提供的插件接口,可以十分便捷的开发出需要的插件。比如想要从oracle导出数据到mysql,那么需要做的就是开发出 OracleReader和MysqlWriter插件,装配到框架上即可。并且这样的插件一般情况下在其他数据交换场合是可以通用的。更大的惊喜是我们 已经开发了如下插件:
Reader插件
- hdfsreader : 支持从hdfs文件系统获取数据。
- mysqlreader: 支持从mysql数据库获取数据。
- sqlserverreader: 支持从sqlserver数据库获取数据。
- oraclereader : 支持从oracle数据库获取数据。
- streamreader: 支持从stream流获取数据(常用于测试)
- httpreader : 支持从http URL获取数据。
Writer插件
- hdfswriter:支持向hdbf写入数据。
- mysqlwriter:支持向mysql写入数据。
- oraclewriter:支持向oracle写入数据。
- streamwriter:支持向stream流写入数据。(常用于测试)
您可以按需选择使用或者独立开发您自己的插件 (具体参见《DataX插件开发指南》)
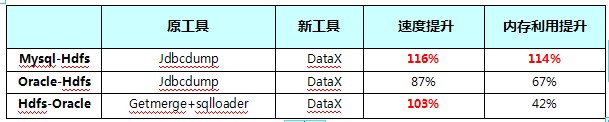
DataX在淘宝的运用