介绍
本篇博客将会介绍一个Python爬虫,用来爬取各个国家的国旗,主要的目标是为了展示如何在Python的requests模块中使用POST方法来爬取网页内容。
为了知道POST方法所需要传递的HTTP请求头部和请求体,我们可以使用Fiddler来进行抓包,抓取上网过程中HTTP请求中的POST方法。为了验证Fiddler抓取到的POST请求,可以使用Postman进行测试验证。在Postman中完成测试后,我们就可以用Python的request.POST()方法来写我们的爬虫了。
流程
作为上述过程的一个演示,我们使用的网址为: http://country.911cha.com/ , 页面如下:
在表单中输入德国,跳转后的页面如下:
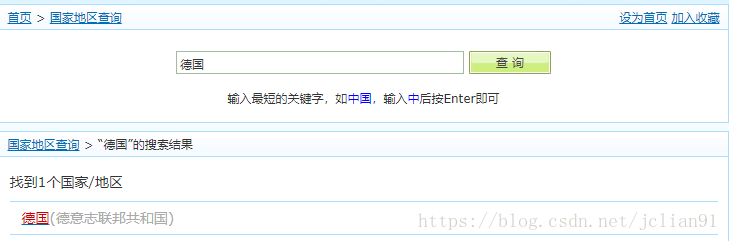
我们可以发现,在搜索的结果中,会出现德国这个搜索结果。点击该搜索结果,跳转后的页面如下:
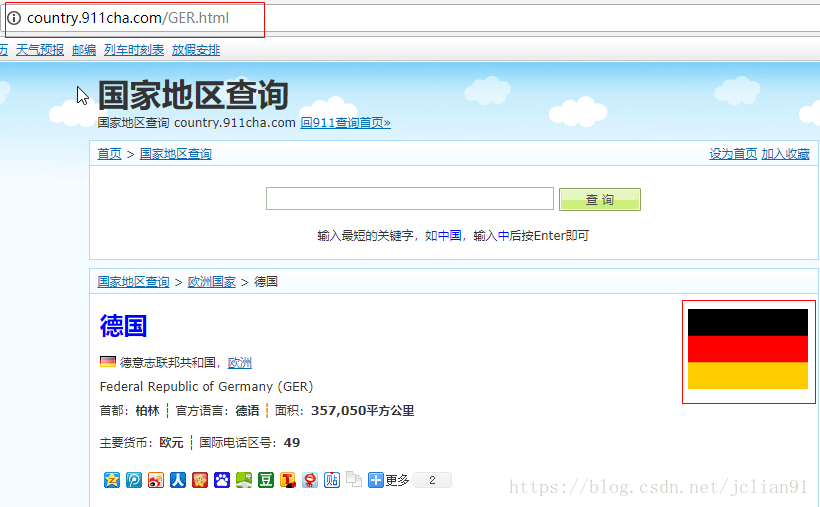
在这个页面中有我们需要的德国的国旗。但是,怎么知道该网页的具体网址呢?换句话说,就是怎样得到http://country.911cha.com/GER.html ?别担心,在刚才出来的德国这个搜索结果中,我们查看其源代码,不难发现,在HTML源代码中,有我们想要的东西:
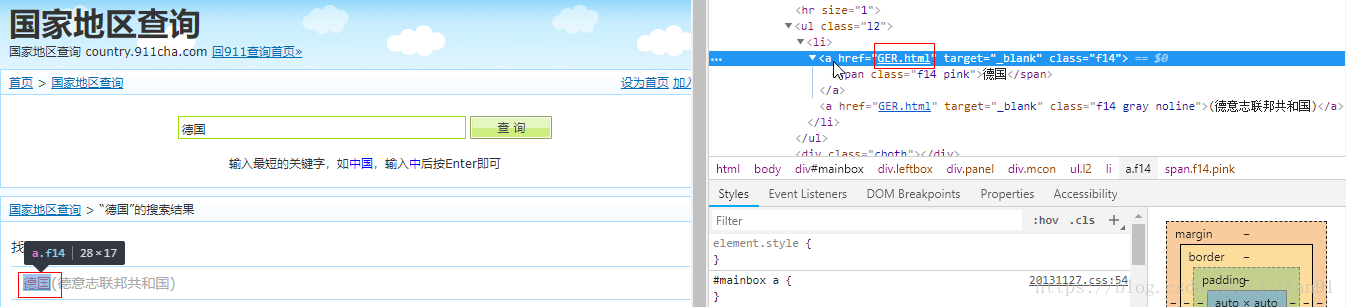
在源代码中我们能看到“GER.html”,这就意味着,只要得到搜索的结果,我们可以分析HTML源码来得到这个搜索结果的连接网址,然后在该连接网址中获取该国的国旗。所以,在这个爬虫中,最困难的地方在于,如何获取搜索结果?即,得到提交表单后的结果,也就是POST方法提交后的响应结果。我们利用Fiddler来抓取该POST方法。
我们打开Fiddler, 同时重复上面的操作,可以得到该过程的HTTP请求,如下图:
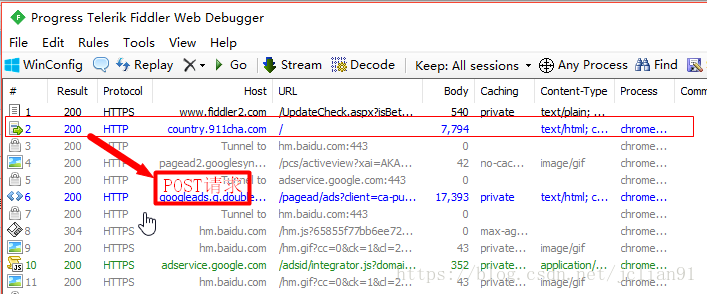
Fiddler帮助我们找到了刚才提交表单过程中的一个POST请求,具体分析该POST请求,其请求头部如下:
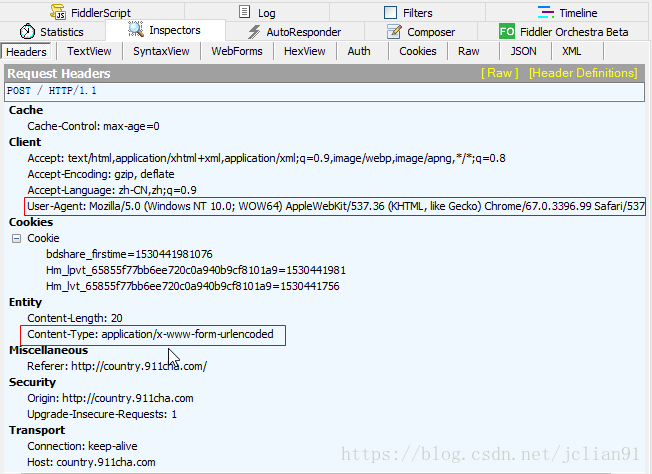
其请求体如下:
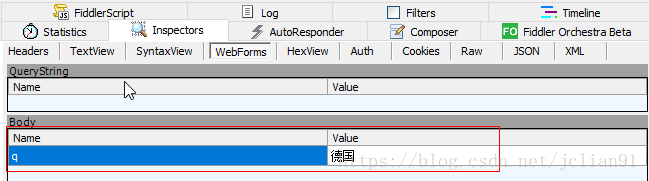
为了验证Fiddler抓取的POST请求,我们需要要Postman来进行测试。在用Postman进行测试前,我们需要问:是否所有请求头部中的数据都需要呢?答案是否定的,实际上,我们只需要User-Agent和Content-Type即可。在Postman中,先输入请求头部,如下:
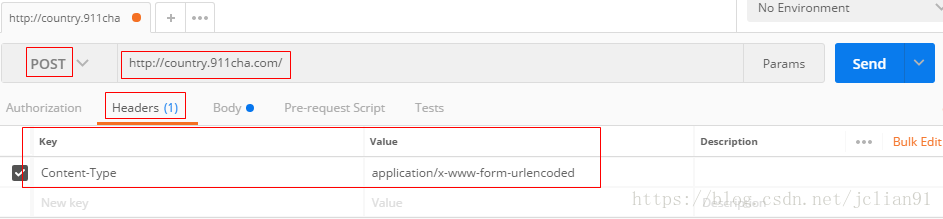
再输入请求体,如下:
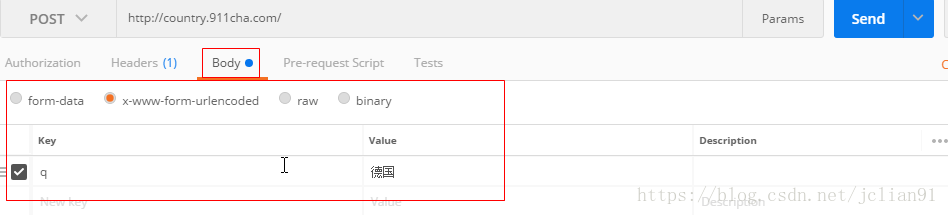
点击"SEND"按钮,得到响应后的结果,如下:
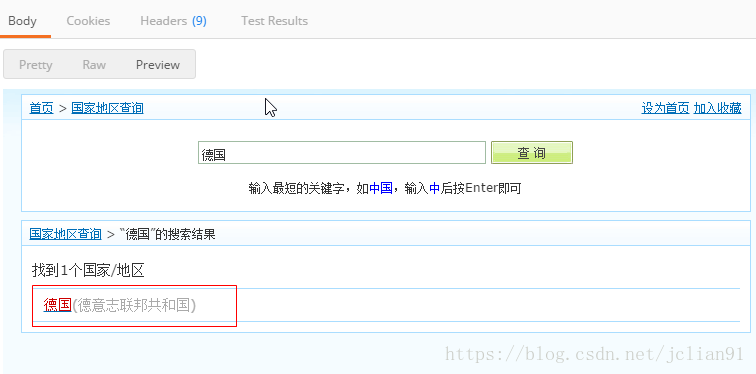
OK,这样我们就完成了Postman的测试。
爬虫
于是,借助这些信息来完成request.post()的提交,同时,借助BeautifulSoup来解析网页,得到国家的国旗下载地址并完成下载。具体的Python代码如下:
# -*- coding: utf-8 -*-
import urllib.request
import requests
from bs4 import BeautifulSoup
# 函数:下载指定国家的国旗
# 参数: country: 国家
def download_flag(country):
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
}
# POST数据
data = {'q': country}
# 网址
url = 'http://country.911cha.com/'
# 提交POST请求
r = requests.post(url=url, data=data, headers=headers)
# 利用BeautifulSoup解析网页
content = BeautifulSoup(r.text, 'lxml')
# 得到搜索结果(国家)所在网页地址
country = content.find_all('div', class_='mcon')[1]('ul')[0]('li')[0]('a')[0]
link = country['href']
#利用GET方法得到搜索国家的网页
r2 = requests.get(url='%s/%s'%(url, link))
# 利用BeautifulSoup解析网页
content = BeautifulSoup(r2.text, 'lxml')
# 获取网页中的图片
images = content.find_all('img')
# 获取指定国家的国旗名称及下载地址
for image in images:
if 'alt' in image.attrs:
if '国旗' in image['alt']:
name = image['alt'].replace('国旗', '')
link = image['src']
# 下载国旗图片
urllib.request.urlretrieve('%s/%s'%(url, link), 'E://flag/%s.gif'%name)
def main():
# countries.txt储存各个国家的名称
file = 'E://flag/countries.txt'
with open(file, 'r') as f:
counties = [_.strip() for _ in f.readlines()]
# 遍历各个国家,下载国旗
for country in counties:
try:
download_flag(country)
print('%s国旗下载成功!'%country)
except:
print('%s国旗下载失败~'%country)
main()
其中countries.txt的部分内容如下:

运行上述Python代码,我们发现在E盘的flag文件夹下,已经下载了各个国家的国旗,如下:

这样我们就完成了本次爬虫的任务!
总结
本次爬虫利用Python的requests模块的POST方法,来模拟网页中的表单提交。为了得到表单提交过程中的HTTP请求,即请求头部和请求体,我们利用了抓包工具Fiddler,而Postman的作用是为了帮助我们验证Fiddler抓取的POST请求是否正是我们需要的POST请求,同时也能验证请求头部及请求体。
虽然整个爬虫的过程写的不免麻烦,但是操作的思路应该是清晰的,再说,熟能生巧,多用几次,也就能熟悉整个流程了。本次爬虫只是作为整个流程的一个简单展示,读者可以在此基础上,去实现更为复杂的爬虫,希望本次的分享能够帮助到读者。谢谢大家能读到这儿,也欢迎大家交流~~
注意:本人现已开通两个微信公众号: 因为Python(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~