链接:https://zhuanlan.zhihu.com/p/134122356
Apache Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供一种HQL语言进行查询,具有扩展性好、延展性好、高容错等特点,多应用于离线数仓建设。
1. Hive架构
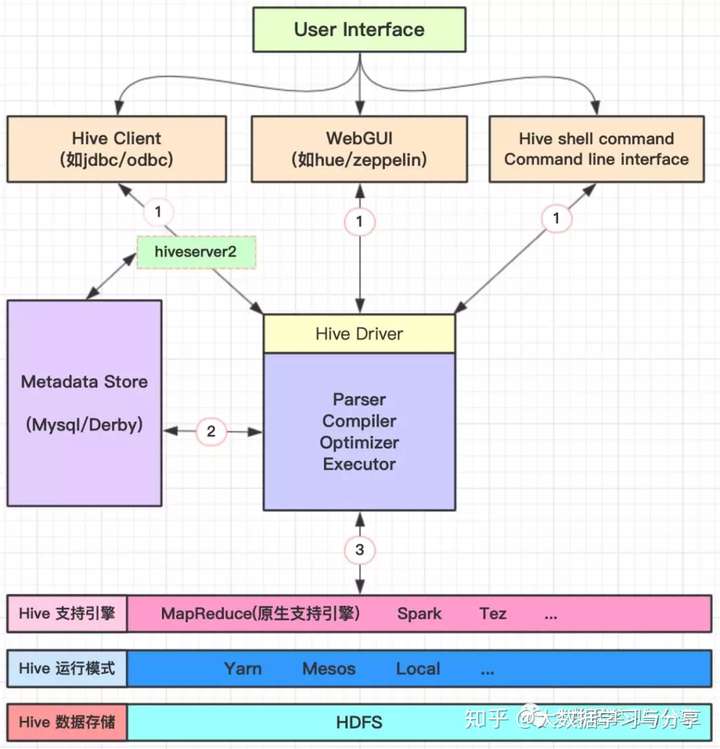
存储:Hive底层存储依赖于hdfs,因此也支持hdfs所支持的数据存储格式,如text、json、parquet等。当我们将一个文件映射为Hive中一张表时,只需在建表时告诉Hive,数据中的列名、列分隔符、行分隔符等,Hive就可以自动解析数据。
支持多种压缩格式:bzip2、gzip、lzo、snappy等。通常采用parquet+snappy格式存储。支持计算引擎:原生支持引擎为MapReduce。但也支持其他计算引擎,如Spark、Tez。
元数据存储:derby是Hive内置的元数据存储库,但是derby并发性能差且目前不支持多会话。实际生产中,更多的是采用mysql为Hive的元数据存储库。
HQL语句执行:解析器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在hdfs中,并在随后转化为MapReduce任务执行。
2.Hive的几种建表方式
1)create [external] table ...
create [external] table [if not exists] table_name
[(col_name data_type[comment col_comment],...)]
[comment table_comment]
[partitioned by (col_name data_type[comment col_comment],...)]
[clustered by (col_name,col_name,...)
[sorted by (col_name[asc|desc],...)] into num_buckets buckets]
[row format row_format]
[stored as file_format]
[location hdfs_path];
create、if not exists等跟传统的关系型数据库含义类似,就不赘述了。笔者这里主要说一下hive建表时的几个特殊关键字:
external:创建外部表时需要指定该关键字,并通过location指定数据存储的路径
partitioned by:创建分区表时,指定分区列。
clustered by和sort by:通常连用,用来创建分桶表,下文会具体阐述。
row format delimited [fields terminated by char] [collection items terminated by char] [map keys terminated by char] [lines terminated by char] serde serde_name [with serdeproperties (property_name=property_value, property_name=property_value, ...)]:指定行、字段、集合类型数据分割符、map类型数据key的分隔符等。用户在建表的时候可以使用Hive自带的serde或者自定义serde,Hive通过serde确定表具体列的数据。
stored as file_format:指定表数据存储格式,如TextFile,SequenceFile,RCFile。默认textfile即文本格式,该方式支持通过load方式加载数据。如果数据需要压缩,则采用sequencefile方式,但这种存储方式不能通过load方式加载数据,必须从一个表中查询出数据再写入到一个表中insert overwrite table t1 select * from t1;
2) create table t_x as select ...即ctas语句,复制数据但不复制表结构,创建的为普通表。如果复制的是分区表则新创建的不是分区表但有分区字段。ctas语句是原子性的,如果select失败,将不再执行create操作。
3) create table t_x like t_y like允许用户复制源表结构,但不复制数据。如,create table t2 like t1;
3.Hive的数据类型
Hive内置数据类型主要分为两类:基础数据类型和复杂数据类型。基础数据类型无外乎就是tinyint、smallint、int、bigint、boolean、float、double、string、timestamp、decimal等,笔者这里主要介绍Hive的复杂数据类型,或者称之为集合类型。
Hive的复杂数据类型主要分三种:map、array、struct,并且支持复杂类型嵌套,利用好这些数据类型,将有效提高数据查询效率。目前为止对于关系型数据库不支持这些复杂类型。
1.首先创建一张表
create table t_complex(id int,
hobby1 map<string,string>,
hobby2 array<string>,
address struct<country:string,city:string>)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':' ;
2.准备数据文件
1,唱歌:一般-跳舞:喜欢-游泳:不喜欢,唱歌-跳舞-游泳,USA-New York
2,打游戏:不喜欢-学习:非常喜欢,打游戏-篮球,CHINA-BeiJing
3.将数据文件load到创建的表中load data local inpath '/root/complex.txt' into table t_complex;
4.查询map、array、struct类型数据查询map和array跟java中是类似的,都是通过key查找map的value或者根据索引查找array中的元素,而struct则通过列名.标识来访问元素。
查询map示例:select hobby1['唱歌'] from t_complex;
查询array示例:select hobby2[0], hobby2[1] from t_complex;
查询struct示例:select address.country, address.city from t_complex;
4.内部表和外部表
Hive在创建表时默认创建的是内部表(又称托管表)。当指定external关键字时,则创建的为外部表。并可以通过location指定建表的数据存储的hdfs路径。
Hive创建内部表时,会将数据复制/移动到数据仓库指向的路径;若创建外部表,仅记录数据所在路径,不对数据位置做任何改变。在删除表时,内部表的元数据和表数据都会被删除,而外部表只删除元数据,不删除表数据。
建议在生产中创建Hive表时采用外部表的方式,这样在发生误删表的时,不至于把表数据也删除,利于数据恢复和安全。当然也可以按照下述情况做细分处理:
1)所有数据处理,全部由hive完成,适合用内部表
2)有hive和其他工具共同处理一个数据集即同一数据集有多个应用要处理,适合用外部表
3)从hive中导出数据,供其他应用使用,适合用外部表
4)普遍用法:初始数据集由外部表操作,数据分析中间表使用内部表
5.order/sort/distribute/cluster by
order by:会将所有的数据汇聚到一个reduce上去执行,然后能保证全局有序。但是效率低,因为不能并行执行
sort by:当设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。好处是:执行了局部排序之后可以为接下去的全局排序提高不少的效率(其实就是做一次归并排序就可以做到全局排序。
distribute by:根据指定的字段将数据分到不同的reduce,且分发算法是hash散列。能保证每一个reduce负责的数据范围不重叠了,但是不保证排序的问题。
cluster by:除了具有distribute by的功能外,还会对该字段进行排序。
只有一个reduce时,cluster by效果不明显,可以执行set mapred.reduce.tasks>1来使效果明显。
当字段相同时,cluster by效果等同于distribute by+sort by。
注意:cluster 和 sort 在查询(select)时不能共存,建表时可以共存
6. Hive中的分区、分桶以及数据抽样
对Hive表进行分区、分桶,可以提高查询效率,抽样效率
6.1分区
分区,在hdfs中表现为table目录下的子目录
6.2分桶
对应建表时bucket关键字,在hdfs中表现为同一个表目录下根据hash散列之后的多个文件,会根据不同的文件把数据放到不同的桶中。如果分桶表导入数据没有生成对应数量的文件,可通过如下方式解决:
1.开启自动分桶,设置参数:set hive.enforce.bucketing= true
2.手动设置reduce数量,比如set mapreduce.job.reduces=4。建议对于设计表有分桶需求时,开启自动分桶。因为一旦reduce数量设置错了,规划的分桶数会无效。
注意:要用insert语句或者ctas语句将数据存入分桶表。load语句只是文件的移动或复制。
6.3 抽样(sampling)
6.3.1 按块抽样
1)百分比
select * from some_table tablesample(40 percent);
2)按大小
select * from some_table tablesample(20M);
3)按照行数取样
select * from some_table tablesample(1000 rows);
6.3.2 按桶抽样
其实就是对分桶表进行抽样,效率高。
抽样数据量=总数据量/抽样分桶数。
示例:select count(1) from tableA Tablesample(bucket 2 out of 8 on user_id);即Tablesample(bucket 开始取样的桶 out of 分成多少个桶)。
如果要进行抽样,建议:
1.如果提前分桶了,表分桶数与抽样分桶数一致,那么只会扫描那个指定桶的数据
2.如果预先分桶和抽样分桶数不一致:重新分桶
3.如果没分桶:先分桶,在抽样
7.Hive的严格模式和非严格模式
通过设置参数hive.mapred.mode来设置是否开启严格模式。目前参数值有两个:strict(严格模式)和nostrict(非严格模式,默认)。通过开启严格模式,主要是为了禁止某些查询(这些查询可能造成意想不到的坏的结果),目前主要禁止3种类型的查询:
1)分区表查询在查询一个分区表时,必须在where语句后指定分区字段,否则不允许执行。
因为在查询分区表时,如果不指定分区查询,会进行全表扫描。而分区表通常有非常大的数据量,全表扫描非常消耗资源。
2)order by 查询order by语句必须带有limit 语句,否则不允许执行。
因为order by会进行全局排序,这个过程会将处理的结果分配到一个reduce中进行处理,处理时间长且影响性能。
3)笛卡尔积查询数据量非常大时,笛卡尔积查询会出现不可控的情况,因此严格模式下也不允许执行。
在开启严格模式下,进行上述三种不符合要求的查询,通常会报类似FAILED: Error in semantic analysis: In strict mode, XXX is not allowed. If you really want to perform the operation,+set hive.mapred.mode=nonstrict+
8.Hive JOIN
写join查询时,需要注意几个关键点:1)只支持等值join,因为非等值连接非常难转化为MapReduce任务
示例:select a.* from a join b on a.id = b.id是正确的,然而:select a.* from a join b on a.id>b.id是错误的。
2)可以join多个表,如果join中多个表的join的列是同一个,则join会被转化为单个MapReduce任务示例:select a.*, b.*, c.* from a join b on a.col= b.col1 join c on c.col= b.col1被转化为单个MapReduce任务,因为join中只使用了b.col1作为join列。
但是如下写法会被转化为2个MapReduce任务。因为 b.col1用于第一次join条件,而 b.col2用于第二次 join
select a.*, b.*, c.* from a join b on a.col= b.col1 join c on c.col= b.col2;
3)join时,转换为MapReduce任务的逻辑
reduce会缓存join序列中除了最后一个表的所有表的记录(具体看启动了几个map/reduce任务),再通过最后一个表将结果序列化到文件系统。这一实现有助于在reduce端减少内存的使用量。实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大量内存)。示例:a.单个map/reduce任务select a.*, b.*, c.* from a join b on a.col= b.col1 join c on c.col= b.col1中所有表都使用同一个join列。reduce端会缓存a表和b表的记录,然后每次取得一个c表的记录就计算一次join结果;b.多个map/reduce任务
select a.*, b.*, c.* from a join b on (a.col= b.col1) join c on (c.col= b.col2)。第一次缓存a表,用b表序列化;第二次缓存第一次MapReduce任务的结果,然后用c表序列化。
4)left semi join
经常用来替换 in和exists。
如,select * from a left semi join b on a.id = b.id; 相当于select * from a where a.id exists(select b.id from b);但这种方式在hive中效率极低。
9.Hive中的3种虚拟列
当Hive产生非预期的数据或null时,可以通过虚拟列进行诊断,判断哪行数据出现问题,主要分3种:
1.INPUT__FILE__NAME
每个map任务输入文件名
2.BLOCK__OFFSET__INSIDE__FILE
map任务处理的数据所对应文件的块内偏移量,当前全局文件的偏移量。对于块压缩文件,就是当前块的文件偏移量,即当前块的第一个字节在文件中的偏移量
3.ROW__OFFSET__INSIDE__BLOCK行偏移量,默认不可用。需要设置hive.exec.rowoffset=true来启用
10.Hive条件判断
Hive中可能会遇到根据判断不同值,产生对应结果的场景,有三种实现方式:if、coalesce、case when。
1.if( condition, true value, false value)只能用来判断单个条件。
示例:select if(col_name='张三',1,0) as x from tab;
2.coalesce( value1,value2,… )获取参数列表中的首个非空值,若均为null,则返回null。
示例select coalesce(null,null,5,null,1,0) as x; 返回5
3.case when
可以与某字段多个比较值的判断,并分别产生不同结果,与其他语言中case语法相似。
select
case col_name
when "张三" then 1
when "李四" then 0
else 2
end as x
from tab;
或:
select
case
when col_name="张三" then 1
when col_name="李四" then 0
else 2
end as x
from tab;
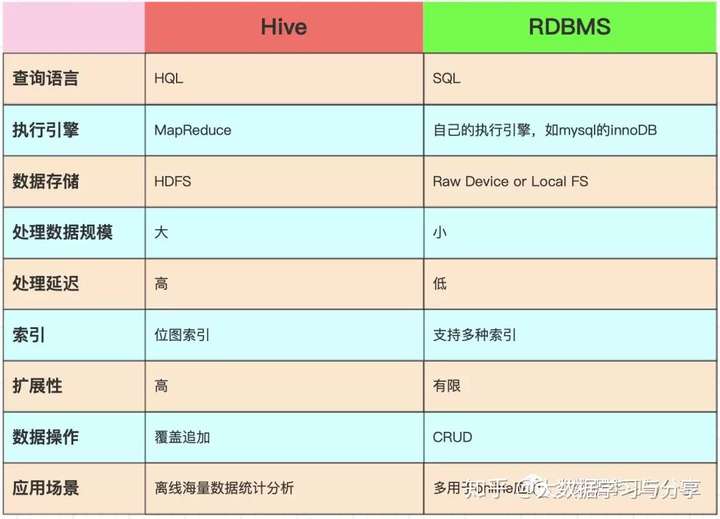
11.Hive与传统的关系型数据库对比