什么是序列化与反序列化
- 序列化:将对象写入到IO中
- 反序列化:从IO流中恢复对象
为什么序列化
- 使得对象可以脱离程序的运行而独立存在
- 所有可在网络上传输的对象都必须是可序列化的
序列化底层原理
实现方式
- 实现Serializable接口
- 实现Externalizable接口
实现Serializable接口
序列化类别
普通序列化
成员是引用的序列化
同一对象序列化多次的机制
可选的自定义序列化
使用transient关键字
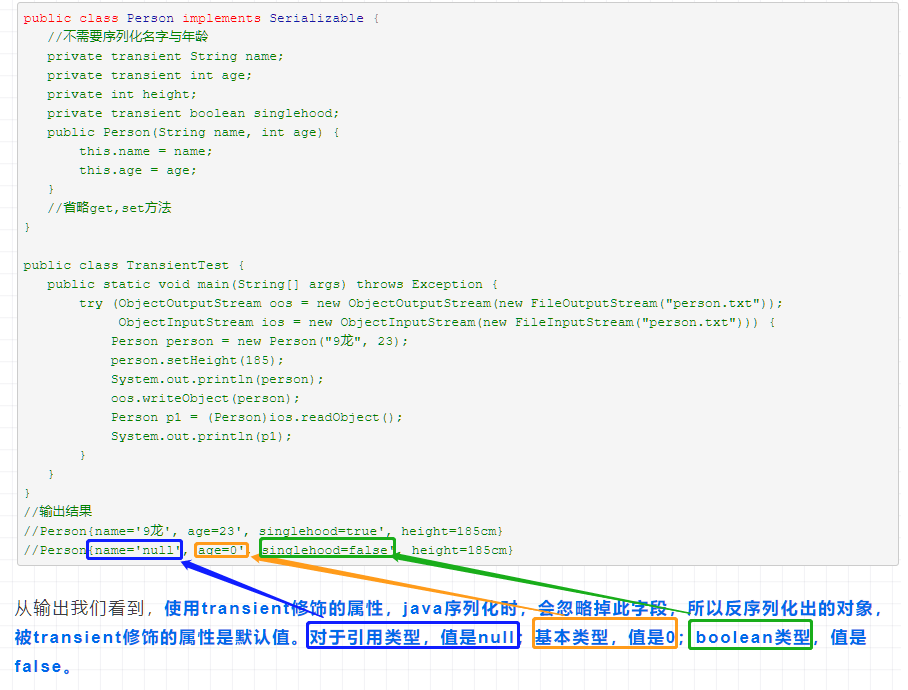
使用transient关键字选择不需要序列化的字段。
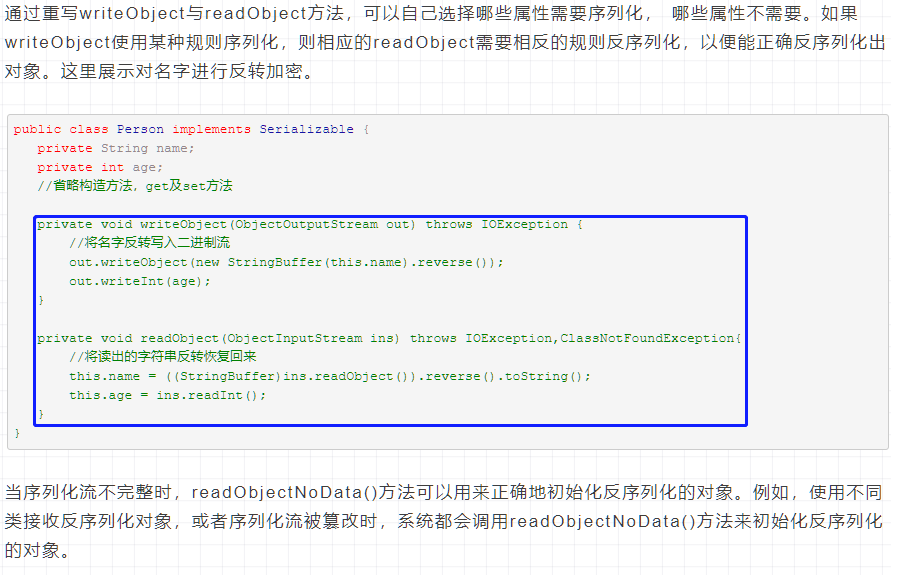
重写writeObject与readObject方法
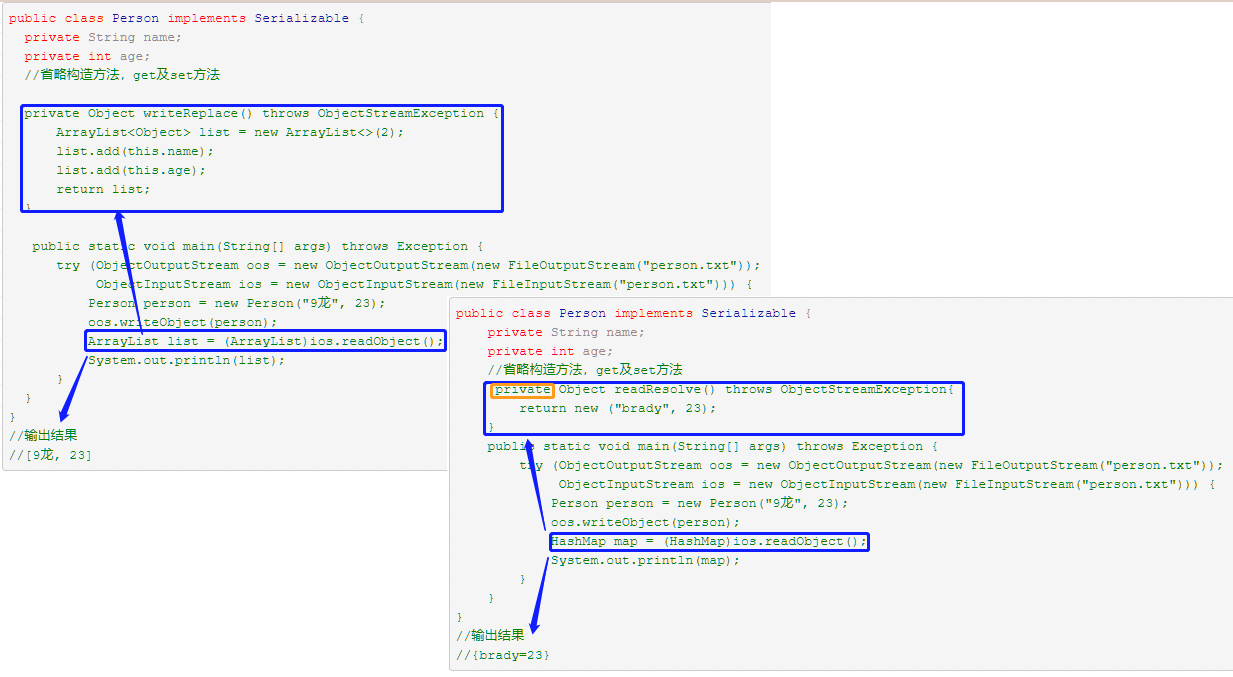
定义writeReplace与readResolve方法
writeReplace:在序列化时,会先调用此方法,再调用writeObject方法。此方法可将任意对象代替目标序列化对象
readResolve:反序列化时替换反序列化出的对象,反序列化出来的对象被立即丢弃。此方法在readeObject后调用。
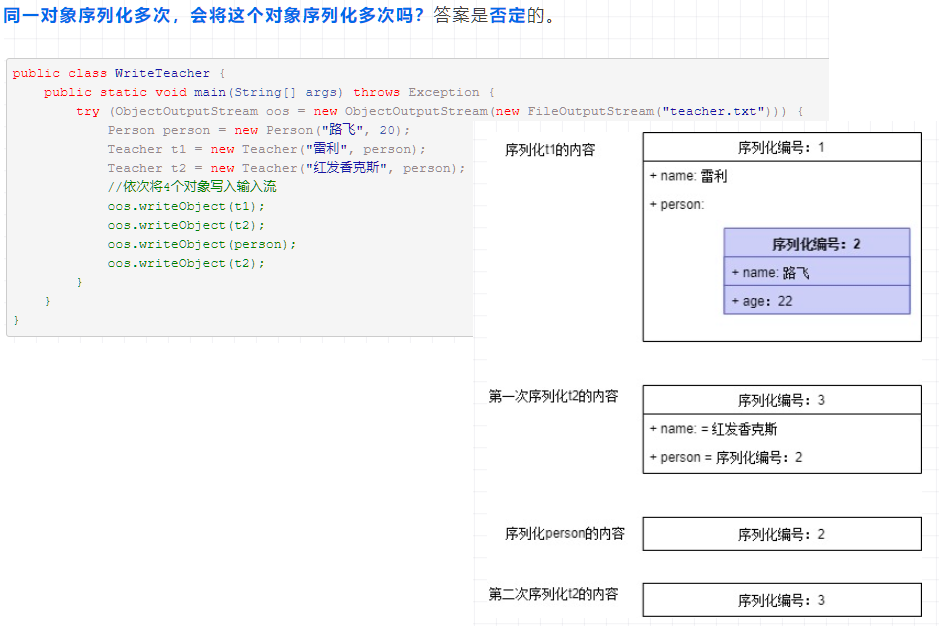
序列化算法
过程
- 所有保存到磁盘的对象都有一个序列化编码号
- 当程序试图序列化一个对象时,会先检查此对象是否已经序列化过,只有此对象从未(在此虚拟机)被序列化过,才会将此对象序列化为字节序列输出。
- 如果此对象已经序列化过,则直接输出编号即可。
案例
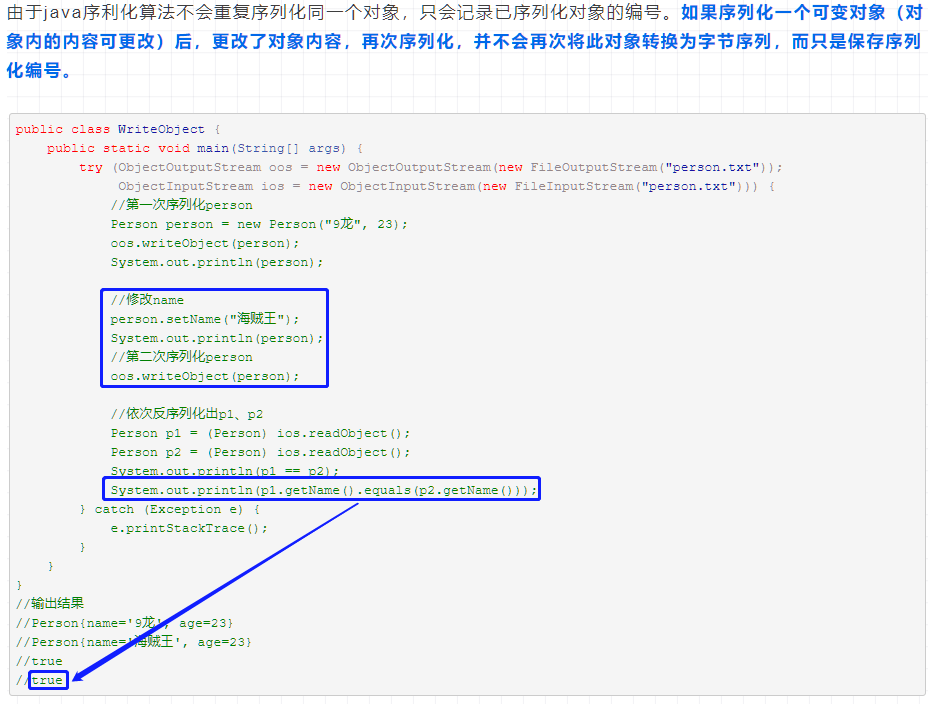
java序列化算法潜在的问题
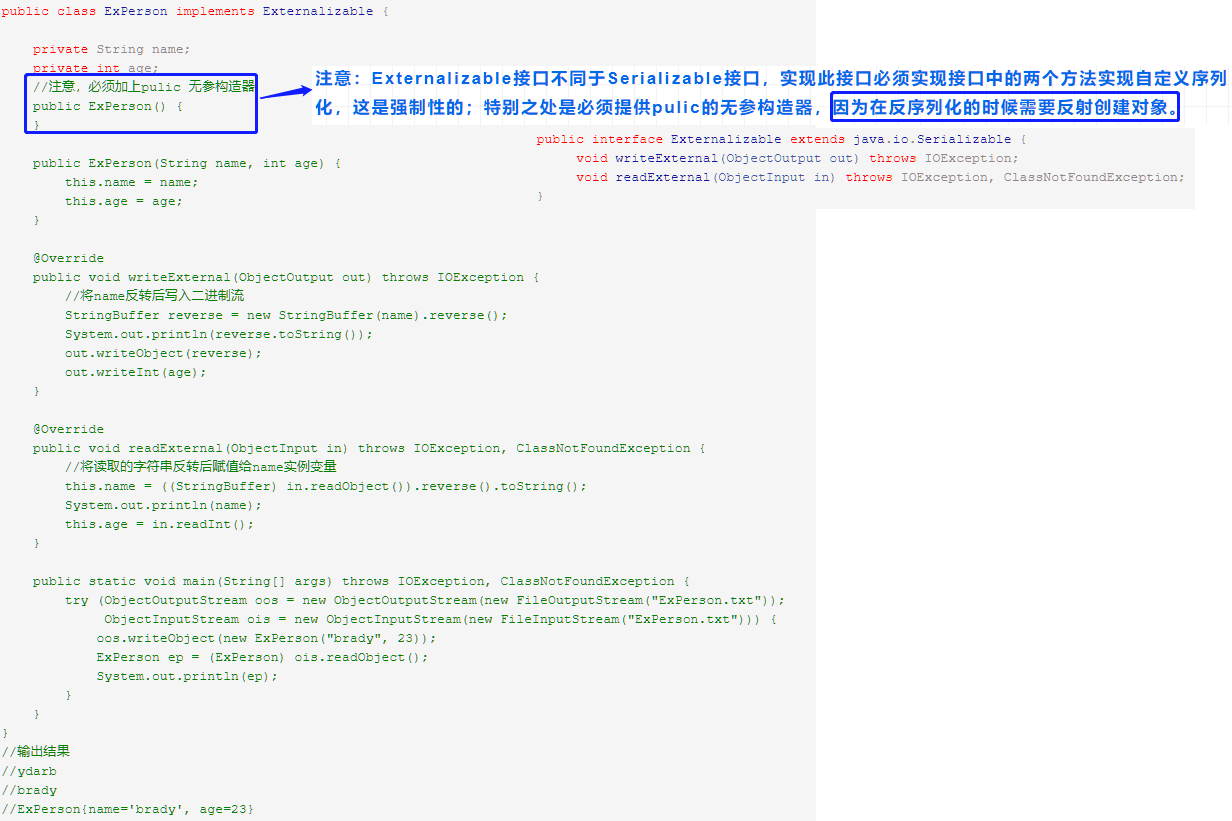
实现Externalizable接口
通过实现Externalizable接口,必须实现writeExternal、readExternal方法。
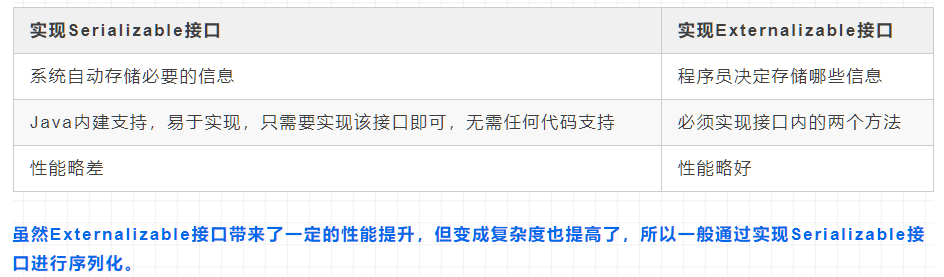
两者对比
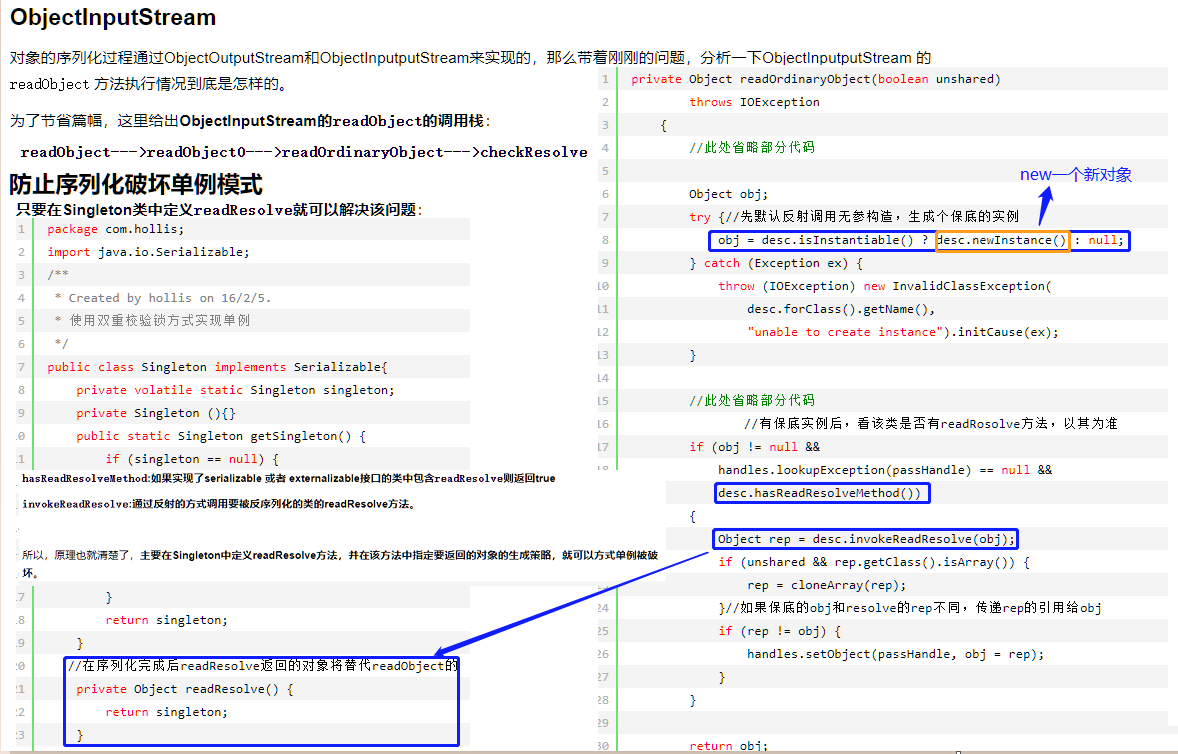
序列化与单例模式
反序列化会通过反射调用无参数的构造方法创建一个新的对象。
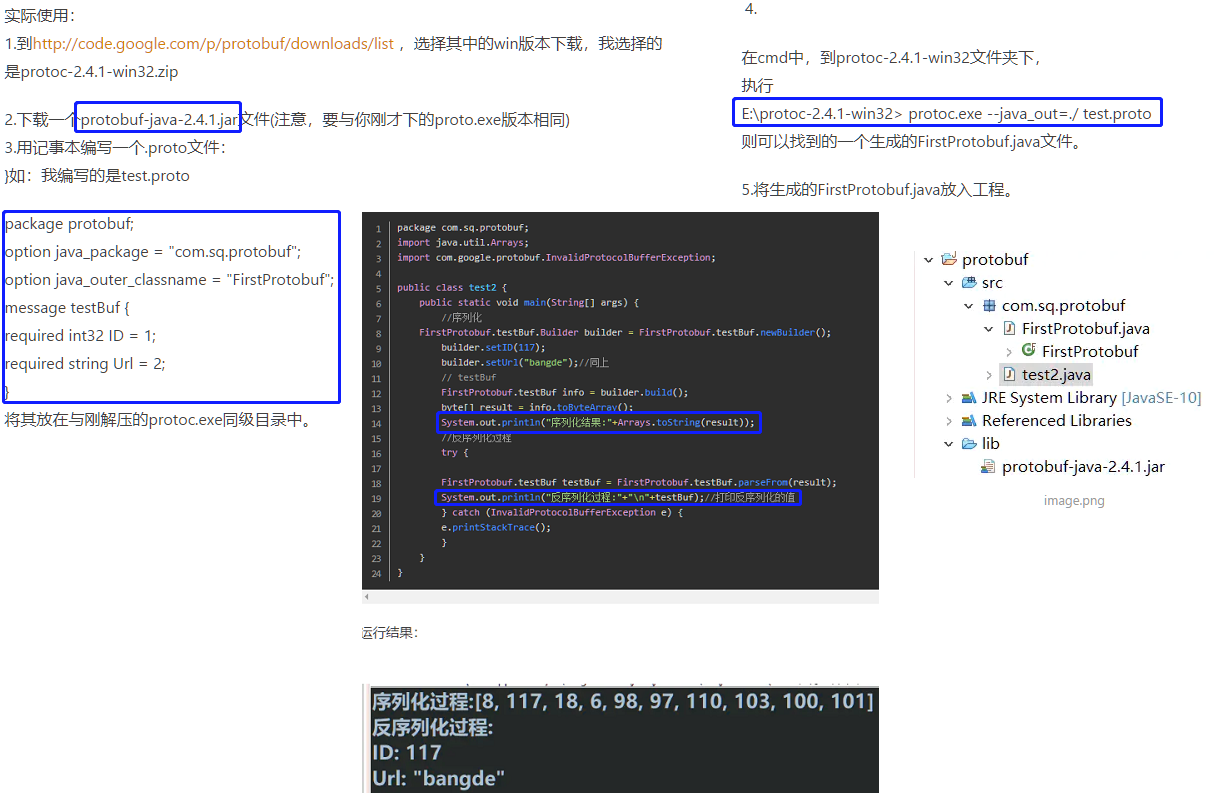
protobuf
protobuf是google团队开发的用于高效存储和读取结构化数据的工具。
为什么说序列化并不安全
主要是:反序列化攻击。
反序列化是一系列安全问题的根源:攻击者能够将恶意数据序列化并存储到数据库或内存中,当应用进行反序列化时,应用会执行到恶意代码。
怎样规避序列化漏洞:
- 对序列化对象执行完整性检查或加密
- 在创建对象之前强制执行严格的类型约束
- 隔离反序列化的代码,使其在非常低的特权环境中运行
- 记录反序列化的例外情况和失败信息
- 限制或监视来自于容器或服务器传入和传出的反序列化网络连接
- 监视反序列化
小结
- 所有需要网络传输的对象都需要实现序列化接口,通过建议所有的javaBean都实现Serializable接口。
- 对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化。
- 如果想让某个变量不被序列化,使用transient修饰。
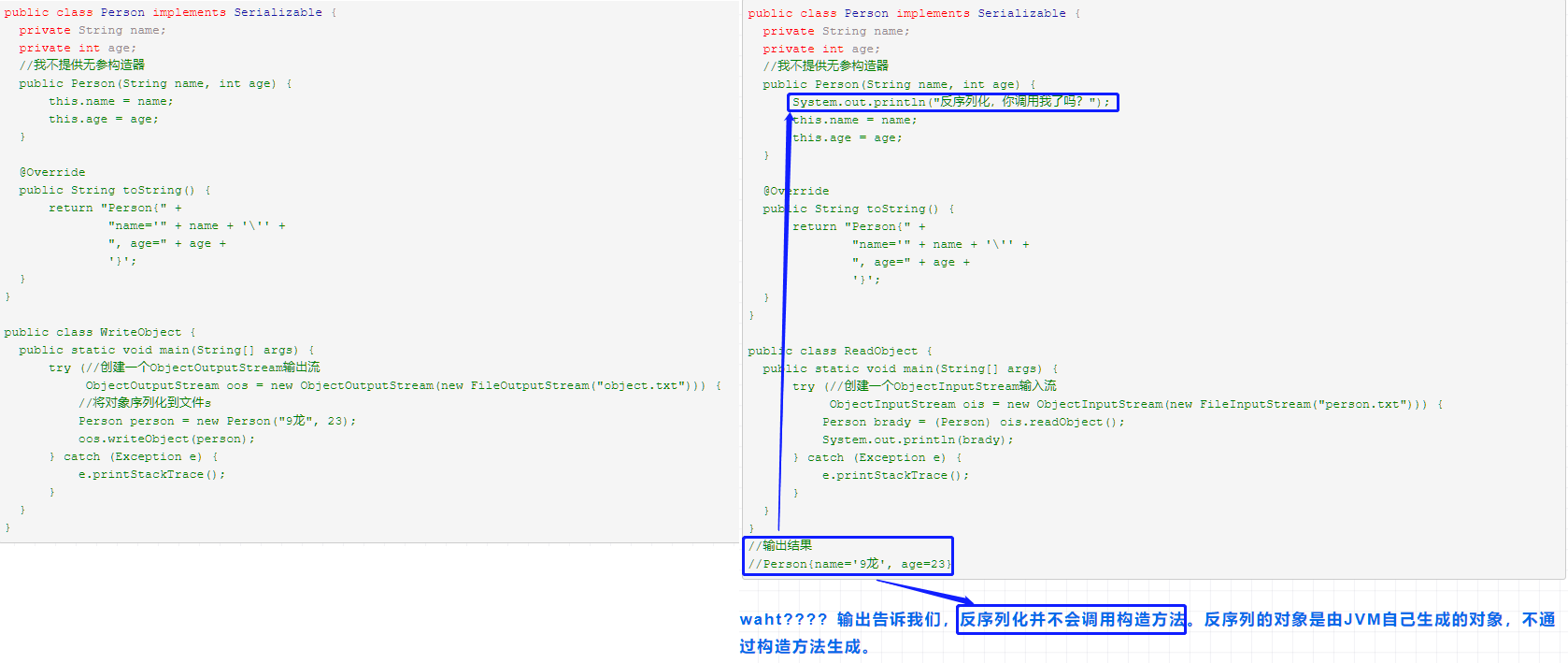
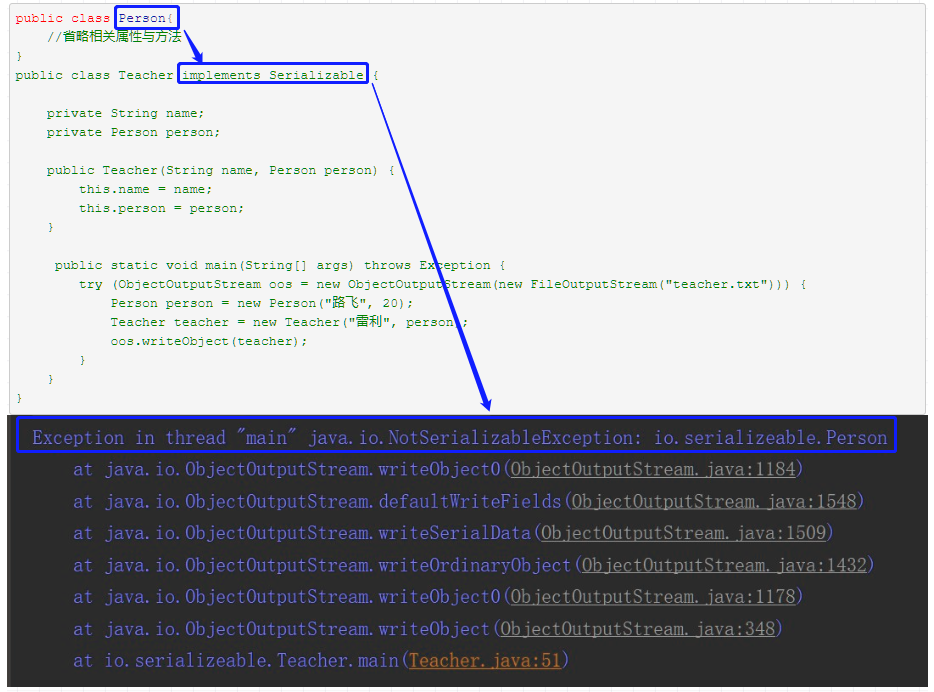
- 序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
- 反序列化时必须有序列化对象的class文件。
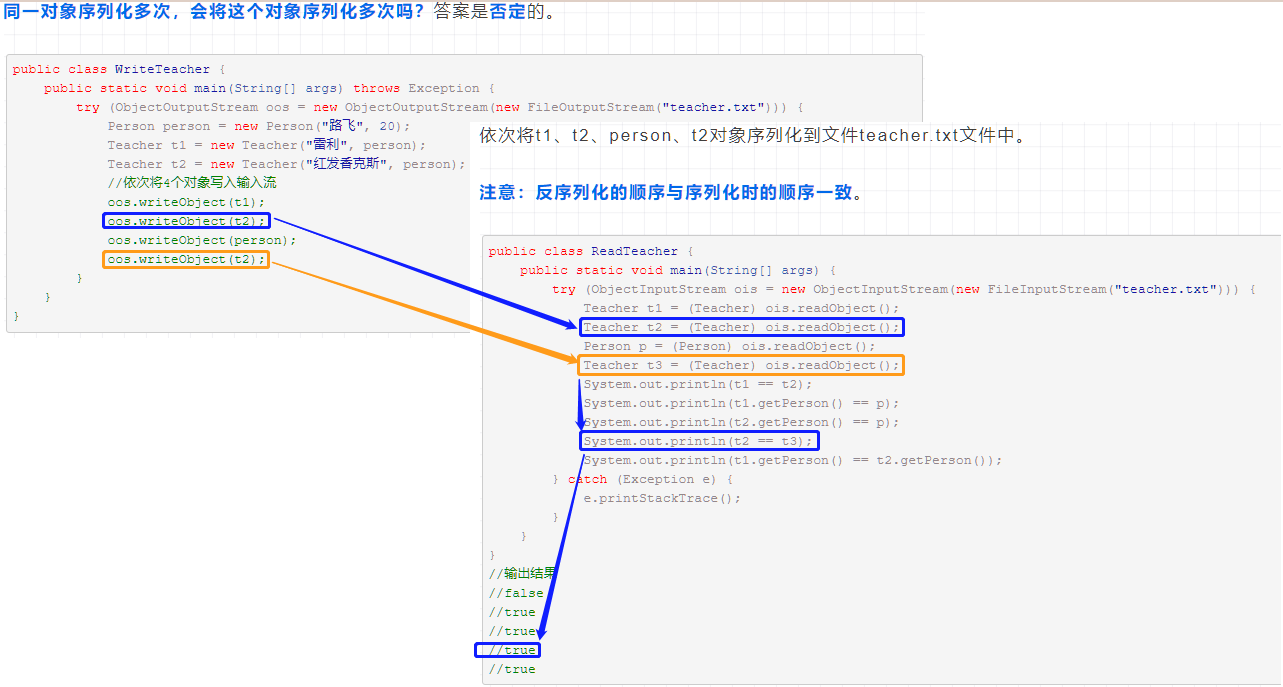
- 当通过文件、网络来读取序列化后的对象时,必须按照实际写入的顺序读取。
- 单例类序列化,需要重写readResolve()方法;否则会破坏单例原则。
- 同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
- 建议所有可序列化的类加上serialVersionUID 版本号,方便项目升级。