HashMap在Java8之后就不再用link data bins了,而是转为用Treeify的bins,和之前相比,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。:
* This map usually acts as a binned (bucketed) hash table, but
* when bins get too large, they are transformed into bins of
* TreeNodes, each structured similarly to those in
* java.util.TreeMap. Most methods try to use normal bins, but
* relay to TreeNode methods when applicable (simply by checking
* instanceof a node). Bins of TreeNodes may be traversed and
* used like any others, but additionally support faster lookup
* when overpopulated. However, since the vast majority of bins in
* normal use are not overpopulated, checking for existence of
* tree bins may be delayed in the course of table methods.
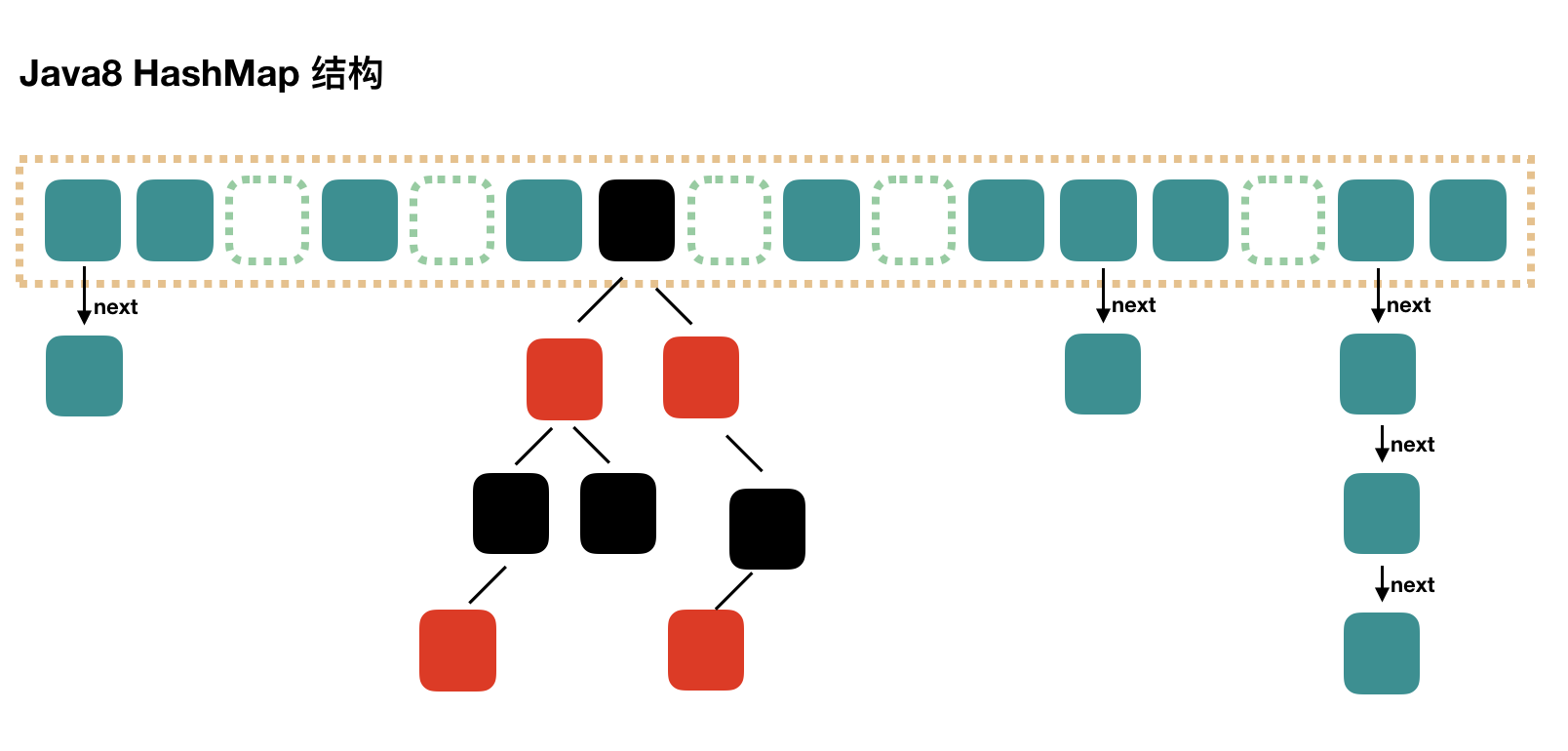
其实很好理解,当Hash冲突过多的时候,树节点肯定比链表更能提升性能,可是绝大多数情况下是不会用到的,首先是用HashMap一般要求是随机的Hash,再者0.7的loadfactor,意味着我们的要求是装不满。可是也并不是所有冲突都是用树节点,而是当冲突数超过6的时候才有可能用到,可见几率比较少。在这里还有注意,树化和链表化是随着节点数互相转换的,分别对应一个threshold,见如下文档解析。
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
先上一段源代码put(),提一下,这个求位置的算法,因为length肯定是2的n倍,所以length-1必然有刚好可以对n区模的1的个数,做与运算,那么就是效率最高的取模运算了。
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } // 第三个参数 onlyIfAbsent 如果是 true,那么只有在不存在该 key 时才会进行 put 操作 // 第四个参数 evict 我们这里不关心 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 第一次 put 值的时候,会触发下面的 resize(),类似 java7 的第一次 put 也要初始化数组长度 // 第一次 resize 和后续的扩容有些不一样,因为这次是数组从 null 初始化到默认的 16 或自定义的初始容量 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 找到具体的数组下标,如果此位置没有值,那么直接初始化一下 Node 并放置在这个位置就可以了 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else {// 数组该位置有数据 Node<K,V> e; K k; // 首先,判断该位置的第一个数据和我们要插入的数据,key 是不是"相等",如果是,取出这个节点 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果该节点是代表红黑树的节点,调用红黑树的插值方法,本文不展开说红黑树 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 到这里,说明数组该位置上是一个链表 for (int binCount = 0; ; ++binCount) { // 插入到链表的最后面(Java7 是插入到链表的最前面) if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // TREEIFY_THRESHOLD 为 8,所以,如果新插入的值是链表中的第 9 个 // 会触发下面的 treeifyBin,也就是将链表转换为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // 如果在该链表中找到了"相等"的 key(== 或 equals) if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) // 此时 break,那么 e 为链表中[与要插入的新值的 key "相等"]的 node break; p = e; } } // e!=null 说明存在旧值的key与要插入的key"相等" // 对于我们分析的put操作,下面这个 if 其实就是进行 "值覆盖",然后返回旧值 if (e != null) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // 如果 HashMap 由于新插入这个值导致 size 已经超过了阈值,需要进行扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
对应线程安全的有ConrrentHashMap,先提下7之前的,之前的是利用分段锁,分段称为Segment,初始时16个大小,而且无法拓容量。对每一个Segment的变更操作如put,delete等均要获取锁,获取不到就阻塞直到获取锁,保证了线程安全。而每一个Segment其实可以算一个小型的HashMap,但初始容量是2,拓容也是2倍(和算法相关)。然而Java8之后,该并发工具就取消的分段锁,而是采用的对单个节点进行上锁或者是当tab[]为null是采用Unsafe类的casTabat()保证线程安全。上源码
public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); // 得到 hash 值 int hash = spread(key.hashCode()); // 用于记录相应链表的长度 int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 如果数组"空",进行数组初始化 if (tab == null || (n = tab.length) == 0) // 初始化数组,后面会详细介绍 tab = initTable(); // 找该 hash 值对应的数组下标,得到第一个节点 f else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 如果数组该位置为空, // 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了 // 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } // hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容 else if ((fh = f.hash) == MOVED) // 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了 tab = helpTransfer(tab, f); else { // 到这里就是说,f 是该位置的头结点,而且不为空 V oldVal = null; // 获取数组该位置的头结点的监视器锁 synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表 // 用于累加,记录链表的长度 binCount = 1; // 遍历链表 for (Node<K,V> e = f;; ++binCount) { K ek; // 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了 if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } // 到了链表的最末端,将这个新值放到链表的最后面 Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { // 红黑树 Node<K,V> p; binCount = 2; // 调用红黑树的插值方法插入新节点 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } // binCount != 0 说明上面在做链表操作 if (binCount != 0) { // 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8 if (binCount >= TREEIFY_THRESHOLD) // 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换, // 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树 // 具体源码我们就不看了,扩容部分后面说 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } // addCount(1L, binCount); return null; }
最后我还想提一下,ConcurrentHashMap的initTable方法,因为该方法用到了我从未想过有什么用的Thread.yield()方法,因为初始化的功劳被其他线程抢去了,所以放弃CPU;另外,我们也可以看到在CAS的时候也用到了Double Check Lock,上源码。
private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0) { // 初始化的"功劳"被其他线程"抢去"了 if ((sc = sizeCtl) < 0) Thread.yield(); // lost initialization race; just spin // CAS 一下,将 sizeCtl 设置为 -1,代表抢到了锁 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if ((tab = table) == null || tab.length == 0) { // DEFAULT_CAPACITY 默认初始容量是 16 int n = (sc > 0) ? sc : DEFAULT_CAPACITY; // 初始化数组,长度为 16 或初始化时提供的长度 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; // 将这个数组赋值给 table,table 是 volatile 的 table = tab = nt; // 如果 n 为 16 的话,那么这里 sc = 12 // 其实就是 0.75 * n sc = n - (n >>> 2); } } finally { // 设置 sizeCtl 为 sc,我们就当是 12 吧 sizeCtl = sc; } break; } } return tab; }