哈夫曼树介绍
1.定义:给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
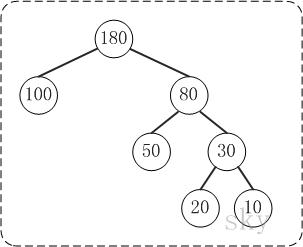
2.术语
(01) 路径和路径长度
定义:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
例子:100和80的路径长度是1,50和30的路径长度是2,20和10的路径长度是3。
(02) 结点的权及带权路径长度
定义:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
例子:节点20的路径长度是3,它的带权路径长度= 路径长度 * 权 = 3 * 20 = 60。
(03) 树的带权路径长度
定义:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
例子:示例中,树的WPL= 1100 + 280 + 320 + 310 = 100 + 160 + 60 + 30 = 350。
3.构造
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
哈夫曼树设计构造
HuffmanTreeNode设计
- 一个哈夫曼树结点应包括父结点、左右孩子结点,权值,还有元素(元素是在进行哈夫曼编码解码时才想到并使用的)
还有实现Comparable接口,用结点权值来决定大小。getter和setter方法不再描述。
public class HuffmanTreeNode implements Comparable<HuffmanTreeNode>
{
private int weight;
private HuffmanTreeNode parent,left,right;
private char element;
public HuffmanTreeNode(int weight, char element ,HuffmanTreeNode parent, HuffmanTreeNode left, HuffmanTreeNode right) {
this.weight = weight;
this.element = element;
this.parent = parent;
this.left = left;
this.right = right;
}
@Override
public int compareTo(HuffmanTreeNode huffmanTreeNode) {
return this.weight - huffmanTreeNode.getWeight();
}
构造哈夫曼树
1.定义一个根节点
private HuffmanTreeNode mRoot; // 根结点
2.构造函数
这里将会使用一个最小堆,用来每次取出权值最小的两个哈夫曼树结点来构造成一个新的哈夫曼树结点,并添加到最小堆中去。直到所有元素构造成一个哈夫曼树结点,设为根节点。
public HuffmanTree(HuffmanTreeNode[] array) {
HuffmanTreeNode parent = null;
ArrayHeap<HuffmanTreeNode> heap = new ArrayHeap();
for (int i=0;i<array.length;i++)
{
heap.addElement(array[i]);
}
for(int i=0; i<array.length-1; i++) {
HuffmanTreeNode left = heap.removeMin();
HuffmanTreeNode right = heap.removeMin();
parent = new HuffmanTreeNode(left.getWeight()+right.getWeight(),' ',null,left,right);
left.setParent(parent);
right.setParent(parent);
heap.addElement(parent);
}
mRoot = parent;
}
哈夫曼树编码与解码
哈夫曼树编码
编码的方法写在了哈夫曼树的构造中。
采用了中序遍历把所有叶子结点都添加到一个数组中来,然后对这些叶子结点逐个进行编码,从下往上,若为左孩子,则为0,反之为1,放入栈中,直至根节点,再将栈中元素全部取出,得到该结点的编码。
public String[] getEncoding() {
ArrayList<HuffmanTreeNode> arrayList = new ArrayList();
inOrder(mRoot,arrayList);
for (int i=0;i<arrayList.size();i++)
{
HuffmanTreeNode node = arrayList.get(i);
String result ="";
int x = node.getElement()-'a';
Stack stack = new Stack();
while (node!=mRoot)
{
if (node==node.getParent().getLeft())
stack.push(0);
if (node==node.getParent().getRight())
stack.push(1);
node=node.getParent();
}
while (!stack.isEmpty())
{
result +=stack.pop();
}
codes[x] = result;
}
return codes;
}
protected void inOrder( HuffmanTreeNode node,
ArrayList<HuffmanTreeNode> tempList)
{
if (node != null)
{
inOrder(node.getLeft(), tempList);
if (node.getElement()!=' ')
tempList.add(node);
inOrder(node.getRight(), tempList);
}
}
哈夫曼树解码
解码这里一开始的思路是从编码结果中取出若干元素,对比各个字符编码结果,得到解码结果,没有去做,感觉太麻烦,而且没有规律性,很难做。
参看了这篇博客:哈夫曼树及解码
自己才理清思路,开始编写,
这个思路是:从编码结果逐个读取,若为0,则指向结点左孩子,反之为其右孩子,如果其没有左右孩子,便为我们所找的叶子结点,将其对应元素添加进来,并重新从根结点开始,直至读取完毕。
//进行解码
String result2 = "";
for (int i = 0; i < s1.length(); i++) {
if (s1.charAt(i) == '0') {
if (huffmanTreeNode.getLeft() != null) {
huffmanTreeNode = huffmanTreeNode.getLeft();
}
} else {
if (s1.charAt(i) == '1') {
if (huffmanTreeNode.getRight() != null) {
huffmanTreeNode = huffmanTreeNode.getRight();
}
}
}
if (huffmanTreeNode.getLeft() == null && huffmanTreeNode.getRight() == null) {
result2 += huffmanTreeNode.getElement();
huffmanTreeNode = huffmanTree.getmRoot();
}
}
码云链接
感悟
- 哈夫曼树的编码解码也比较有意思,编码的思路自己一开始理清了,解码其实就是一个逆过程,但自己没有想到,直到参看资料才有了思路。