Hive 引言
# 简介
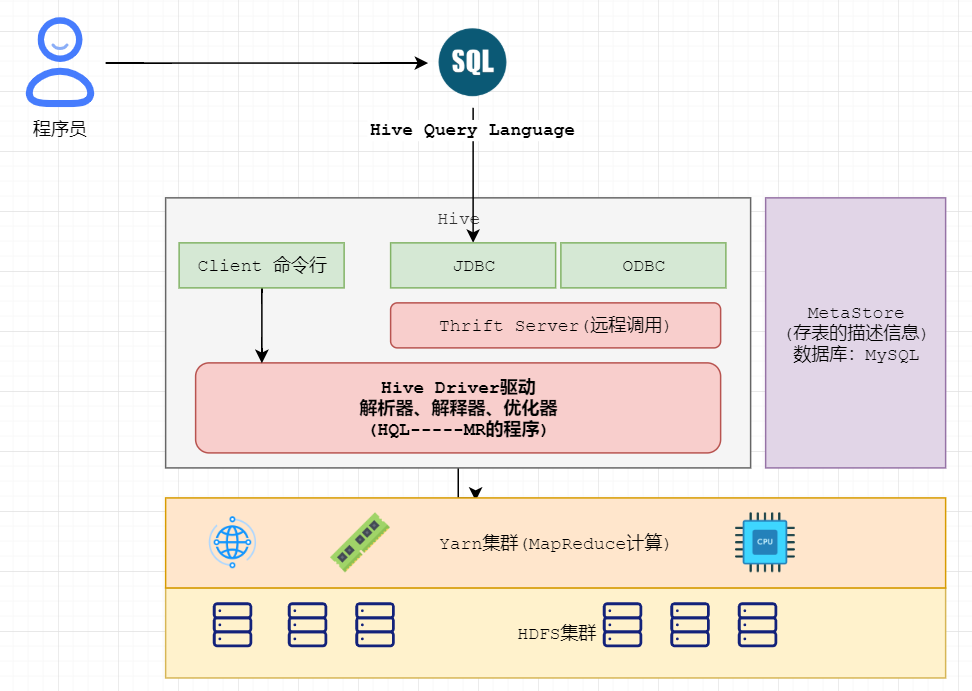
> hive是facebook开源,并捐献给了apache组织,作为apache组织的顶级项目(hive.apache.org)。 hive是一个基于大数据技术的数据仓库(DataWareHouse)技术,主要是通过将用户书写的SQL语句翻译成MapReduce代码,然后发布任务给MR框架执行,完成SQL 到 MapReduce的转换。可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
>
> **总结**
>
> - Hive是一个数据仓库(数据库)
> - Hive构建在HDFS上,可以存储海量数据。
> - Hive允许程序员使用**SQL命令**来完成数据的分布式计算,计算构建在yarn之上。(Hive会将**SQL转化为MR操作**)
>
> 优点:
> 简化程序员的开发难度,写SQL即可,避免了去写mapreduce,减少开发人员的学习成本
> 缺点:
> 延迟较高(MapReduce本身延迟,Hive SQL向MapReduce转化优化提交),适合做大数据的离线处理(TB PB级别的数据,统计结果延迟1天产出)
> Hive不适合场景:
> 1:小数据量, MySQL。
> 2:实时计算:Flink/Spark HBase
- 数据库 DataBase
- 数据量级小,数据价值高
- 数据仓库 DataWareHouse
- 数据体量大,数据价值低
启动hive
# 本地模式启动 【管理员模式】
# 启动hive服务器,同时进入hive的客户端。只能通过本地方式访问。
[root@hadoop10 ~]# hive
Logging initialized using configuration in jar:file:/opt/installs/hive1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive>
# 启动hive的服务器,可以允许远程连接方式访问。
// 前台启动
[root@hadoop10 ~]# hiveserver2
// 后台启动
[root@hadoop10 ~]# hiveserver2 &
# beeline客户端··
# 启动客户端
[root@hadoop10 ~]# beeline
beeline> !connect jdbc:hive2://hadoop10:10000
回车输入mysql用户名
回车输入mysql密码
HQL高级
# 0. 各个数据类型的字段访问(array、map、struct)
# array类型:字段名[index];map类型:字段名[key];struct类型:字段名.属性名
select name,salary,hobbies[1],cards['123456'],addr.city from t_person;
# 1. 条件查询:= != >= <=
select * from t_person where addr.city='郑州';
# 2. and or between and
# array_contains(字段,值):函数,针对array类型的字段,判断数组里面包含指定的值
select * from t_person where salary>5000 and array_contains(hobbies,'抽烟');
# 3. order by[底层会启动mapreduce进行排序]
select * from t_person order by salary desc;
# 4. limit(hive没有起始下标)
select * from t_person sort by salary desc limit 5;
# 5. 去重 distinct
select distinct addr.city from t_person;
select distinct(addr.city) from t_person;
单行函数(show functions) --对一行数据进行操作
#查看所有函数
-- 查看hive系统所有函数
show functions;
--函数的使用:函数名(参数)
1. array_contains(列,值);--判断数组列中是否包含指定的值
select name,hobbies from t_person where array_contains(hobbies,'喝酒');
2. length(列)--获取到长度
select length('123123');
3. concat(列,列)--拼接
select concat('123123','aaaa');
4. to_date('1999-9-9')--字符串转换成日期
select to_date('1999-9-9');
5. year(date)--获取日期类型的年,month(date)--获取日期类型的月份,
6. date_add(date,数字)--日期加多少天
select name,date_add(birthday,-9) from t_person;
炸裂函数(集合函数):由一行数据计算完成之后获得多行数据
-- 查询所有的爱好,explode
select explode(hobbies) as hobby from t_person
常见的函数
# lateral view
-- 为指定表,的边缘拼接一个列。(类似表连接)
-- lateral view:为表的拼接一个列(炸裂结果)
-- 语法:from 表 lateral view explode(数组字段) 别名 as 字段名;
# collect_list(组函数)
作用:对分组后的,每个组的某个列的值进行收集汇总。
语法:select collect_list(列) from 表 group by 分组列;
例: select username,collect_list(video_name) from t_visit_video group by username;
数据:
id username
1 ["a","b"]
2 ["a","a","b"]
# collect_set(组函数)
作用:对分组后的,每个组的某个列的值进行收集汇总,并去掉重复值。
语法:select collect_set(列) from 表 group by 分组列;
例: select username,collect_set(video_name) from t_visit_video group by username;
数据:
id username
1 ["a","b"]
2 ["a","C","b"]
# concat_ws(单行函数):指定分隔符
作用:如果某个字段是数组,对该值得多个元素使用指定分隔符拼接。
select id,name,concat_ws(',',hobbies) from t_person;
--# 将t_visit_video数据转化为如下效果
--统计每个人,2020-3-21看过的电影。
例: select username,concat_ws(',',collect_set(video_name)) from t_visit_video group by username;
数据:
id username
1 a,b
2 a,C,b
全排序和局部排序
# 全局排序
语法:select * from 表 order by 字段 asc|desc;
# 局部排序(分区排序)
概念:启动多个reduceTask,对数据进行排序(预排序),局部有序。
局部排序关键词 sort by
默认reducetask个数只有1个,所有分区也只有一个。所以默认和全排序效果一样。
语法:select * from 表 distribute by 分区字段 sort by 字段 asc|desc;
外部表和分区表
# 创建表语法 external 代表为外部表
row format delimited 表示自定义分隔符
partitioned by(country string,city string) 表示为分区表
create external table t_personout(
id int,
name string,
salary double,
birthday date,
sex char(1),
hobbies array<string>,
cards map<string,string>,
addr struct<city:string,zipCode:string>
)
#partitioned by(country string,city string)
#row format delimited
fields terminated by ',' --列的分割
collection items terminated by '-'--数组 struct的属性 map的kv和kv之间
map keys terminated by '|'
lines terminated by '
'
location '/file';
# 导入数据命令
# 在hive命令行中执行
-- local 代表本地路径,如果不写,代表读取文件来自于HDFS
-- overwrite 是覆盖的意思,可以省略。
load data [local] inpath ‘/opt/datas/person.txt’ [overwrite] into table t_person;
# 本质上就是将数据上传到hdfs中(数据是受hive的管理)
#可执行的导入数据的命令
load data local inpath '/opt/data/person.txt' into table t_person;
自定义函数 UDF和UDTF
# 0. 导入hive依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
# 1.定义一个类继承UDF
1. 必须继承UDF GenericUDTF
2. 方法名必须是evaluate initialize
-- 创建永久函数与开发好的java class关联
create function base_analizer as 'UDF.FileUdf' # 全类名
using jar 'hdfs://synthesize60:9000/user/hive/jars/aofflineforwarehouse.jar' # hdfs上的路径;
-- 删除永久函数
drop function flat_analizer;
表数据转存导入操作
# 1.将文件数据导入hive表中,
load data local inpath '文件的路径' overwrite into table 表。
# 2.直接将查询结果,放入一个新创建的表中。(执行查询的创建)
create table 表 as select语...
1. 执行select语句
2. 创建一个新的表,将查询结果存入表中。
# 3.将查询结果,导入已经存在表。
insert into 表
select语句...
# 4.将HDFS中已经存在文件,导入新建的hive表中
create table Xxx(
...
)row format delimited
fields terminated by ','
location 'hdfs的表数据对应的目录'
# 将SQL的执行结果插入到另一个表中
create table 表 as select语句
--## 例子:
--统计每个人,2020-3-21看过的电影,将结果存入hive的表:t_video_log_20200321
create table t_video_log_20200321 as select ...;
日期相关
date_add(next_day('2020-10-30','MO'),-7) 周一
date_add(next_day('2020-10-30','MO'),-1) 周末
concat(date_add(next_day('2020-10-30','MO'),-7),'_' ,date_add(next_day('2020-10-30','MO'),-1))) 周一 -~ 周末
date_format('2020-12-14','yyyy-MM') 月