如图,右面的部分
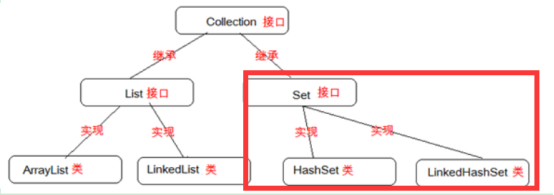
Set接口里面的集合,所存储的元素是不重复的。
没有独有方法,都是继承Collection。
因为是接口,所以要用多态创建对象:
Set<String> set=new HashSet<String>();
1 Set集合特点
1)无索引
2)无序
3)不能存重复元素
例:
import java.util.HashSet;
import java.util.Set;
public class SetTest {
public static void main(String[] args) {
Set<String> set=new HashSet<String>();
set.add("china");
set.add("Hello");
set.add("apple");
set.add("java");
set.add("Hello");
//遍历
for(String s:set){
System.out.println(s);
}
}
}
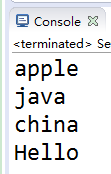
可以看到,打印顺序和存入顺序不一致。而且最后添加的”Hello”因为重复了,不能加进去。
2 Set集合为什么不能存重复元素
HashSet集合,采用哈希表结构存储数据,保证元素唯一性的方式依赖于:hashCode()与equals()方法。
2.1哈希表
哈希表底层,使用的也是数组机制数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把这些对象给数组中存放时,那么会根据这些对象的特有数据结合相应的算法,计算出这个对象在数组中的位置,然后把这个对象存放在数组中。而这样的数组就称为哈希数组,即就是哈希表。是一种链表加数组的形式。
理解:(JDK api上的解释:)

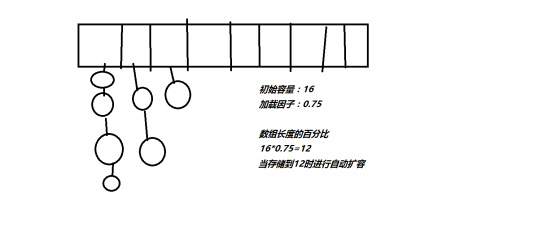
当向哈希表中存放元素时,需要根据元素的特有数据结合相应的算法,这个算法其实就是Object类中的hashCode方法。由于任何对象都是Object类的子类,所以任何对象有拥有这个方法。即就是在给哈希表中存放对象时,会调用对象的hashCode方法(哈希函数),算出对象在表中的存放位置,这里需要注意,如果两个对象hashCode方法算出结果一样,这样现象称为哈希冲突,这时会调用对象的equals方法,比较这两个对象是不是同一个对象,如果equals方法返回的是true,那么就不会把第二个对象存放在哈希表中,如果返回的是false,就会把这个值存放在哈希表中。
2.2所以当set对象调用add方法时,add方法会默认调用对象的hashcode方法,得到哈希值以后去容器中找是否有相同的哈希值,如果没有,直接将元素存入集合。如果有,则再调用该对象的equals方法,比较内容,如果内容相同,则直接扔掉不存入集合,如果不相同,则存入集合,而且存在一条链上。

3 HashSet集合存储元素
3.1 HashSet存储JavaAPI中的类型元素
给HashSet中存储JavaAPI中提供的类型元素时,不需要重写元素的hashCode和equals方法,因为这两个方法,在JavaAPI的每个类中已经重写完毕,如String类、Integer类等。
看一下String类重写的hashCode()方法:
public class Test{
public static void main(String[] args) {
String s1=new String("abc");
String s2=new String("abc");
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
}
}

放在hashCode()方法上,ctrl+点击:

用这个算法,最后算出”abc”的哈希值为96354。
3.2 HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一。
例:(未重写前)
public class Person {
private String name;
private int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}
import java.util.HashSet;
import java.util.Set;
public class SetTest3 {
public static void main(String[] args) {
Set<Person> set=new HashSet<Person>();
set.add(new Person("a",10));
set.add(new Person("b",11));
set.add(new Person("c",9));
set.add(new Person("a",10));
for(Person p:set){
System.out.println(p);
}
}
}
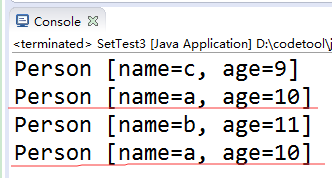
可以看到,存入了重复的值。
进行一下重写:
public class Person2 {
private String name;
private int age;
public Person2() {
super();
}
public Person2(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
return name.hashCode()+age*31;
}
@Override
public boolean equals(Object obj) {
if(obj==null){
return false;
}
if(obj==this){
return true;
}
if(obj instanceof Person){
Person2 p=(Person2)obj;
return p.age==this.age && p.name.equals(this.name);
}
return false;
}
}
再执行SetTest3同样的代码:
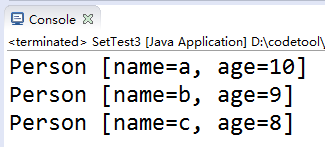
说明:
hashCode()的返回值是int类型,Person类的成员变量有两个,name是String类型,可以直接调用String类重写的hashCode()方法,再加上int类型的age就可以了。乘上一个31(或其他数),就可以避免重复的哈希值(例如”a”,10和”b”,9...)太多(一条链上链的太多)。这个数也不能太大,会过多太多容量。(上面那个“桶”的图)
这个重写在eclipss也可以点出来:
右键--Source--Generate hashCode() and equals()...
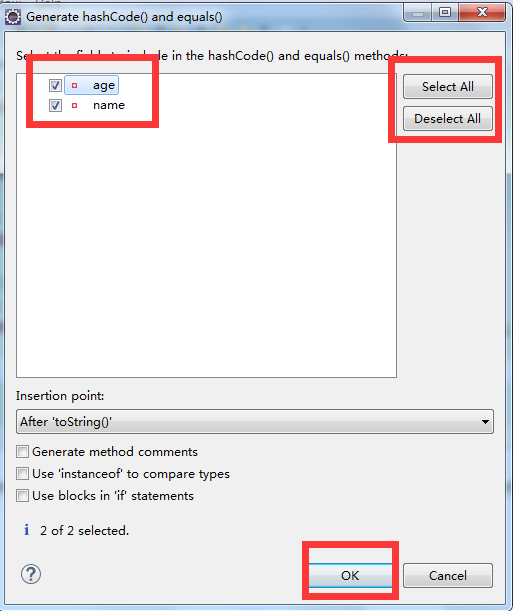
点出来结果是:

这个写法更严谨。
总结:保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
4 LinkedHashSet
HashSet保证元素唯一,可是元素存放进去是没有顺序的。
在HashSet下面有一个子类LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。而且是双向链接,有序。
用LinkedHashSet存自定义类型也需要重写hashCode和equals方法。
例:
import java.util.LinkedHashSet;
public class LinkedHashSetTest {
public static void main(String[] args) {
LinkedHashSet<String> set=new LinkedHashSet<String>();
set.add("china");
set.add("Hello");
set.add("apple");
set.add("java");
//遍历
for(String s:set){
System.out.println(s);
}
}
}
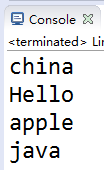
可以看到取出顺序和存入顺序一致。
5判断集合元素唯一的原理
5.1 ArrayList的contains方法判断元素是否重复原理

使用传入的元素的equals方法依次与集合中的元素比较。
所以ArrayList存放自定义类型时,需要重写元素的equals方法。
5.2 HashSet的add/contains等方法判断元素是否重复原理

判断唯一的依据是元素类型的hashCode与equals方法的返回结果。
先判断新元素与集合内已经有的旧元素的HashCode值
如果不同,说明是不同元素,添加到集合。
如果相同,再判断equals比较结果。返回true则相同元素;返回false则不同元素,添加到集合。
所以使用HashSet存储自定义类型,需要重写该元素类的hashcode与equals方法。