这几天正在看反向传播的原理,最近也经常看到关于反向传播理解的文章,在深度学习的理论中BP也是极其重要的,所以就抽出一段时间认真地研究了一下BP的原理,以下为参考网上的几篇文章总结得出的。
一、望尽天涯路
1974年,Paul Werbos首次给出了如何训练一般网络的学习算法—。这个算法可以高效的计算每一次迭代过程中的梯度,让以上我们的推导得以实现!然而不巧的是,在当时整个人工神经网络社群中无人知晓Paul所提出的学习算法。直到80年代中期,算法才重新被David Rumelhart、Geoffrey Hinton及Ronald Williams、David Parker和Yann LeCun独立发现,并获得了广泛的注意,引起了人工神经网络领域研究的第二次热潮,反向传播正式出现在大众面前。
下面首先来思考:
- 第一个问题 为什么要理解“反向传播”?
计算机视觉领域大牛 Andrej Karpathy(李飞飞的高徒)曾在他的一篇博客中强调了理解“反向传播”算法的必要性,将其归结为一个“”:https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b。换句话说,It is easy to fall into the trap of abstracting away the learning process(人们很容易陷入将学习过程抽象出来的陷阱中)。
也就是说如果只是简单地将任意层叠加在一起,那么将“神奇地使它们对您的数据起作用”,我们也就不求甚解了,所以我们必须要理解反向传播。
- 第二个问题 反向传播算法为什么要“反向”?
在机器学习中,很多算法最后都会转化为优化目标函数——求损失函数()的最小值。这个损失函数往往很复杂,难以求出最值的解析表达式。而梯度下降法可以解决这类问题,直观地说一下这个方法的思想:我们把求解损失函数最小值的过程看做“站在山坡某处去寻找山坡的最低点”。我们并不知道最低点的确切位置,“梯度下降算法”的策略是每次向“下坡路”的方向走一小步,经过长时间的走“下坡路”最后的停留位置也大概率在最低点附近。这个“下坡路的方向”我们选做是梯度方向的负方向,选这个方向是因为每个点的梯度负方向是在该点处函数下坡最陡的方向。在神经网络模型中反向传播算法的作用就是要求出这个梯度值,从而后续用梯度下降去更新模型参数。反向传播算法从模型的输出层开始,利用函数求导的链式法则,逐层从后向前求出模型梯度,那么为什么要从后向前呢?

如上图所示,图中输入向量经过神经网络的输出为,模型的参数为 和 ,在输入值 为 时,将模型的参数看做自变量,于是所谓的求梯度就是求出所有的和。
如何计算这些导数?如果我不知道反向传播算法,我应该会用如下式子的近似求导方法(高等数学中求导数的方法):
即要求某个参数的导数就让这个参数微变一点点,然后求出结果相对于参数变化量的比值。那么为何我们的神经网络算法没有采用这种方法求导呢?
现在假设输入向量经过正向传播后,现在要求出参数 和 的导数,按照上述方法计算时,对 微扰后,需要重新计算红框内的节点;对 微扰后,需要重新计算绿框内的节点。这两次计算中也有大量的“重复单元”即图中的蓝框,实际上神经网络的每一个参数的计算都包含着这样大量的重复单眼,那么神经网络规模一旦变大,这种算法的计算量一定爆炸,没有适用价值。所以选择了从后向前“反向”地计算各层参数的梯度。
为什么这个计算方向能够高效?因为在计算梯度时前面的单元是依赖后面的单元的计算,而“从后向前”的计算顺序正好“解耦”了这种依赖关系,先算后面的单元,并且记住后面单元的梯度值,计算前面单元之就能充分利用已经计算出来的结果,避免了重复计算,这也就是为什么反向传播算法要“反向”。
二、一千个人眼中有一千个哈姆雷特
那么我们要如何理解反向传播算法?别着急,我们慢慢来看,经过这一章,你就肯定是明白了。
1.【知乎高赞回答:如何直观地解释 backpropagation 算法?—— Anonymous】
(反向传播)算法是多层神经网络的训练中举足轻重的算法。简单的理解,它的确就是复合函数的链式法则,但其在实际运算中的意义比链式法则()要大的多。
机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定一些样本点,用合适的曲线揭示这些样本点随着自变量的变化关系。
深度学习同样也是为了这个目的,只不过此时,样本点不再限定为点对,而可以是由向量、矩阵等等组成的广义点对。而此时,之间的关系也变得十分复杂,不太可能用一个简单函数表示。然而,人们发现可以用多层神经网络表示这样的关系,而多层神经网络的本质就是一个多层复合的函数。

说到神经网络,这个图片应该并不陌生,通过这张图可以比较直观地描绘一下这种复合关系。这是一个典型的三层神经网络,基本构成:是输入层,是隐含层,是输出层,其对应的表达式如下:

上面式中的 就是相邻两层神经元之间的权值,它们就是深度学习需要学习的参数,也就相当于直线拟合 中的待求参数和。
和直线拟合一样,深度学习的训练也有一个目标函数,这个目标函数定义了什么样的参数才算一组“好参数”,不过在机器学习中,一般是采用成本函数(),然后,训练目标就是通过调整每一个权值 来使得 达到最小。 函数也可以看成是由所有待求权值 为自变量的复合函数,而且基本上是非凸的,即含有许多局部最小值。但实际中发现,采用我们常用的梯度下降法就可以有效的求解最小化函数的问题。
梯度下降法需要给定一个初始点,并求出该点的梯度向量,然后以负梯度方向为搜索方向,以一定的步长进行搜索,从而确定下一个迭代点,再计算该新的梯度方向,如此重复直到 cost 收敛。那么如何计算梯度呢?
假设我们把 cost 函数表示为,那么它的梯度向量就等于,其中 eij 表示正交单位向量。为此,我们需求出 cost 函数H对每一个权值 Wij 的偏导数。而BP算法正是用来求解这种多层复合函数的所有变量的偏导数的利器。
我们以求的偏导为例。它的复合关系画出图可以表示如下:

在图中,引入了中间变量,。
为了求出时,e的梯度,我们可以先利用偏导数的定义求出不同层之间相邻节点的偏导关系,如下图所示。

利用链式法则我们知道:
链式法则在上图中的意义是什么呢?其实不难发现,的值等于从到的路径上的偏导值的乘积,而的值等于从到的路径上的偏导值的乘积加上路径上的偏导值的乘积。也就是说,对于上层节点和下层节点,要求得,需要找到从节点到节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到的值。
大家也许已经注意到,这样做是十分冗余的,因为很多路径被重复访问了。比如上图中,和就都走了路径。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。
同样是利用链式法则,算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。
正如反向传播()算法的名字说的那样,算法是反向(自上往下)来寻找路径的。
从最上层的节点开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等所在的层按照这样传播完毕后,第二层的每一个节点都“堆放"些值,然后我们针对每个节点,把它里面所有“堆放”的值求和,就得到了顶点对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点对它们的偏导值,以"层"为单位重复上述传播过程,即可求出顶点对每一层节点的偏导数。
以上图为例,节点接受发送的1 * 2并堆放起来,节点接受发送的1 * 3并堆放起来,至此第二层完毕,求出各节点总堆放量并继续向下一层发送。节点向发送2 * 1并对堆放起来,节点向发送2 * 1并堆放起来,节点向发送3 * 1并堆放起来,至此第三层完毕,节点堆放起来的量为2,节点堆放起来的量为2 * 1+3 * 1=5, 即顶点对的偏导数为5。
总结来说:通过高等数学的链式法则来理解反向传播,是比较直接的方式,但是不够清晰。最简单的方式就是进行一次带入数值演示的反向传播的过程,就能有一个深刻的认知:
2.【博客园博客:一文弄懂神经网络中的反向传播法—BackPropagation——Charlotte77】
假设,你有这样一个网络层:

通过对所有参数:输入数据,输出数据,初始权重,进行赋值。
输入数据:i1=0.05,i2=0.10;
输出数据:o1=0.01,o2=0.99;
第一层的初始权重:w1=0.15,w2=0.20,w3=0.25,w4=0.30;
第二层的初始权重:w5=0.40,w6=0.45,w7=0.50,w8=0.55;
初始偏置:b1=0.35,b2=0.60;
目标:给出输入数据,(0.05和0.10),使输出尽可能与原始输出,(0.01和0.99)接近。
先进行前向传播,然后反向传播进而更新参数。
反向传播时计算总误差():
有两个输出,所以分别计算和的误差,总误差为两者之和:
以和为例:

计算总误差对的偏导时,是从,但是在隐含层之间的权值更新时,是,而会接受和两个地方传来的误差,所以这个地方两个都要计算。
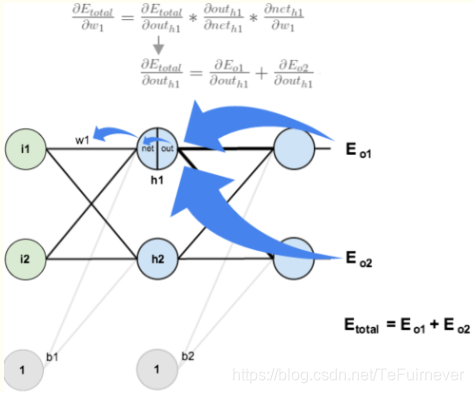
这样一次误差的反向传播法就完成了,最后我们再把更新的权值重新计算,然后不停地迭代这个过程。
代码:
import random
import math
# 参数解释:
# "pd_" :偏导的前缀
# "d_" :导数的前缀
# "w_ho" :隐含层到输出层的权重系数索引
# "w_ih" :输入层到隐含层的权重系数的索引
class NeuralNetwork:
LEARNING_RATE = 0.5
def __init__(self, num_inputs, num_hidden, num_outputs, hidden_layer_weights = None, hidden_layer_bias = None, output_layer_weights = None, output_layer_bias = None):
self.num_inputs = num_inputs
self.hidden_layer = NeuronLayer(num_hidden, hidden_layer_bias)
self.output_layer = NeuronLayer(num_outputs, output_layer_bias)
self.init_weights_from_inputs_to_hidden_layer_neurons(hidden_layer_weights)
self.init_weights_from_hidden_layer_neurons_to_output_layer_neurons(output_layer_weights)
def init_weights_from_inputs_to_hidden_layer_neurons(self, hidden_layer_weights):
weight_num = 0
for h in range(len(self.hidden_layer.neurons)):
for i in range(self.num_inputs):
if not hidden_layer_weights:
self.hidden_layer.neurons[h].weights.append(random.random())
else:
self.hidden_layer.neurons[h].weights.append(hidden_layer_weights[weight_num])
weight_num += 1
def init_weights_from_hidden_layer_neurons_to_output_layer_neurons(self, output_layer_weights):
weight_num = 0
for o in range(len(self.output_layer.neurons)):
for h in range(len(self.hidden_layer.neurons)):
if not output_layer_weights:
self.output_layer.neurons[o].weights.append(random.random())
else:
self.output_layer.neurons[o].weights.append(output_layer_weights[weight_num])
weight_num += 1
def inspect(self):
print('------')
print('* Inputs: {}'.format(self.num_inputs))
print('------')
print('Hidden Layer')
self.hidden_layer.inspect()
print('------')
print('* Output Layer')
self.output_layer.inspect()
print('------')
def feed_forward(self, inputs):
hidden_layer_outputs = self.hidden_layer.feed_forward(inputs)
return self.output_layer.feed_forward(hidden_layer_outputs)
def train(self, training_inputs, training_outputs):
self.feed_forward(training_inputs)
# 1. 输出神经元的值
pd_errors_wrt_output_neuron_total_net_input = [0] * len(self.output_layer.neurons)
for o in range(len(self.output_layer.neurons)):
# ∂E/∂zⱼ
pd_errors_wrt_output_neuron_total_net_input[o] = self.output_layer.neurons[o].calculate_pd_error_wrt_total_net_input(training_outputs[o])
# 2. 隐含层神经元的值
pd_errors_wrt_hidden_neuron_total_net_input = [0] * len(self.hidden_layer.neurons)
for h in range(len(self.hidden_layer.neurons)):
# dE/dyⱼ = Σ ∂E/∂zⱼ * ∂z/∂yⱼ = Σ ∂E/∂zⱼ * wᵢⱼ
d_error_wrt_hidden_neuron_output = 0
for o in range(len(self.output_layer.neurons)):
d_error_wrt_hidden_neuron_output += pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].weights[h]
# ∂E/∂zⱼ = dE/dyⱼ * ∂zⱼ/∂
pd_errors_wrt_hidden_neuron_total_net_input[h] = d_error_wrt_hidden_neuron_output * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_input()
# 3. 更新输出层权重系数
for o in range(len(self.output_layer.neurons)):
for w_ho in range(len(self.output_layer.neurons[o].weights)):
# ∂Eⱼ/∂wᵢⱼ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢⱼ
pd_error_wrt_weight = pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].calculate_pd_total_net_input_wrt_weight(w_ho)
# Δw = α * ∂Eⱼ/∂wᵢ
self.output_layer.neurons[o].weights[w_ho] -= self.LEARNING_RATE * pd_error_wrt_weight
# 4. 更新隐含层的权重系数
for h in range(len(self.hidden_layer.neurons)):
for w_ih in range(len(self.hidden_layer.neurons[h].weights)):
# ∂Eⱼ/∂wᵢ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢ
pd_error_wrt_weight = pd_errors_wrt_hidden_neuron_total_net_input[h] * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_weight(w_ih)
# Δw = α * ∂Eⱼ/∂wᵢ
self.hidden_layer.neurons[h].weights[w_ih] -= self.LEARNING_RATE * pd_error_wrt_weight
def calculate_total_error(self, training_sets):
total_error = 0
for t in range(len(training_sets)):
training_inputs, training_outputs = training_sets[t]
self.feed_forward(training_inputs)
for o in range(len(training_outputs)):
total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o])
return total_error
class NeuronLayer:
def __init__(self, num_neurons, bias):
# 同一层的神经元共享一个截距项b
self.bias = bias if bias else random.random()
self.neurons = []
for i in range(num_neurons):
self.neurons.append(Neuron(self.bias))
def inspect(self):
print('Neurons:', len(self.neurons))
for n in range(len(self.neurons)):
print(' Neuron', n)
for w in range(len(self.neurons[n].weights)):
print(' Weight:', self.neurons[n].weights[w])
print(' Bias:', self.bias)
def feed_forward(self, inputs):
outputs = []
for neuron in self.neurons:
outputs.append(neuron.calculate_output(inputs))
return outputs
def get_outputs(self):
outputs = []
for neuron in self.neurons:
outputs.append(neuron.output)
return outputs
class Neuron:
def __init__(self, bias):
self.bias = bias
self.weights = []
def calculate_output(self, inputs):
self.inputs = inputs
self.output = self.squash(self.calculate_total_net_input())
return self.output
def calculate_total_net_input(self):
total = 0
for i in range(len(self.inputs)):
total += self.inputs[i] * self.weights[i]
return total + self.bias
# 激活函数sigmoid
def squash(self, total_net_input):
return 1 / (1 + math.exp(-total_net_input))
def calculate_pd_error_wrt_total_net_input(self, target_output):
return self.calculate_pd_error_wrt_output(target_output) * self.calculate_pd_total_net_input_wrt_input();
# 每一个神经元的误差是由平方差公式计算的
def calculate_error(self, target_output):
return 0.5 * (target_output - self.output) ** 2
def calculate_pd_error_wrt_output(self, target_output):
return -(target_output - self.output)
def calculate_pd_total_net_input_wrt_input(self):
return self.output * (1 - self.output)
def calculate_pd_total_net_input_wrt_weight(self, index):
return self.inputs[index]
# 文中的例子:
nn = NeuralNetwork(2, 2, 2, hidden_layer_weights=[0.15, 0.2, 0.25, 0.3], hidden_layer_bias=0.35, output_layer_weights=[0.4, 0.45, 0.5, 0.55], output_layer_bias=0.6)
for i in range(10000):
nn.train([0.05, 0.1], [0.01, 0.09])
print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.09]]]), 9))
#另外一个例子,可以把上面的例子注释掉再运行一下:
# training_sets = [
# [[0, 0], [0]],
# [[0, 1], [1]],
# [[1, 0], [1]],
# [[1, 1], [0]]
# ]
# nn = NeuralNetwork(len(training_sets[0][0]), 5, len(training_sets[0][1]))
# for i in range(10000):
# training_inputs, training_outputs = random.choice(training_sets)
# nn.train(training_inputs, training_outputs)
# print(i, nn.calculate_total_error(training_sets))
总结来说:这个版本的理解是我个人认为最有效果的理解方式,虽然推导过程比较痛苦,但是还是推荐大家跟着推导一遍,就会比较好地理解反向传播。最后最后一组连图:
3.Principles of training multi-layer neural network using backpropagation
假设,使用了一个具有两个输入,两个隐藏层和一个输出的三层神经网络,如下图所示:

每个神经元由两个单元组成。第一单元添加权重系数和输入信号的乘积。第二个单元实现非线性功能,称为神经元激活功能。信号是加法器输出信号,是非线性元件的输出信号。信号也是神经元的输出信号。

为了让神经网络学习,我们需要训练数据集。训练数据集由输入信号(和)组成,而输入信号分配有相应目标(期望的输出)。网络训练是一个迭代过程,在每次迭代中,使用训练数据集中的新数据来修改节点的权重系数。
使用下面描述的算法计算修改:每一个学习步骤都是从训练集中的两个输入信号开始的。在此阶段之后,我们可以确定每个网络层中每个神经元的输出信号值。下面的图片说明了信号如何通过网络传播,符号表示网络输入之间的连接权重和输入层中的神经元。符号表示神经元的输出信号。



通过隐藏层传播信号,符号代表下一层中神经元m的输出和神经元n的输入之间的连接权重


通过输出层传播信号。

在下一个算法步骤中,将网络y的输出信号与在训练数据集中找到的期望输出值(目标)进行比较。差异称为输出层神经元的误差信号。

由于内部神经元的输出值是未知的,直接计算内部神经元的误差信号是不可能的。多年来,训练多层网络的有效方法一直是未知的。直到80年代中期,反向传播算法才被提出。其思想是将误差信号(在单独的教学步骤中计算)传播回所有神经元,输出信号作为讨论神经元的输入。


用于传播误差的权值系数等于计算输出值时使用的权值系数。只改变数据流的方向(信号一个接一个地从输出传播到输入)。此技术适用于所有网络层。如果传播的误差来自少数神经元,则添加误差。下图:



当计算每个神经元的误差信号时,可以修改每个神经元输入节点的权系数。式表示神经元激活函数的导数(修改权值)。






系数影响网络学习速度。有一些技术可以选择这个参数。第一种方法是用较大的参数值开始学习过程。在建立权重系数的同时,参数逐渐减小。第二种方法更为复杂,它以较小的参数值开始学习。在学习过程中,随着学习的推进,参数逐渐增大,在最后阶段又逐渐减小。以较低的参数值开始学习过程,可以确定权重系数符号。
三、天下谁人不识君
随着神经网络的继续发展,到了深度学习大行其道的今天,更新权值的思路其实变得更简单粗暴了。概括一下就是,把原来打包式的做法拆开成了:1)求梯度;2)梯度下降。所以现在我们再提到,一般只是指第一步:求梯度。这就是为什么好多理解中直接说就是个链式法则,因为确实就是链式法则。
相信看到了这里,你一定对反向传播有了一定的理解了,
1)链式法则的直观理解之所以可以链式法则,是因为梯度直观上理解就是一阶近似,所以梯度可以理解成某个变量或某个中间变量对输出影响的敏感度的系数,这种理解在一维情况下的直观帮助可能并不是很大,但是到了高维情况,当链式法则从乘法变成了矩阵乘法的时候,这个理解起来就形象多了。神经网络中的链式法则恰好都几乎是高维的。
2)。其实就是计算代数中的一个最基础办法,从计算机的角度来看还有点动态规划的意思。其优点是表达式给定的情况下对复合函数中所有变量进行快速求导,这正好是神经网络尤其是深度学习的场景。
最后推荐一个从计算图()角度看BP()算法,这也是目前深度学习中用的比较多的。
计算图(computational graph)角度看BP(back propagation)算法
如果想要更多的资源,欢迎关注 @我是管小亮,文字强迫症MAX~
回复【福利】即可获取我为你准备的大礼,包括C++,编程四大件,NLP,深度学习等等的资料。
想看更多文(段)章(子),欢迎关注微信公众号「程序员管小亮」~
