学前思考:

基础
1. MySQL概述
- 数据库
- 有组织存放数据的仓库
- DB
- 数据库管理系统
- 操作和管理数据的大型软件
- DBMS
- SQL
- 结构查询语言
- 操作关系型数据库的编程语言,定义了一套操作关系型数据库的标准
- 通过SQL语句操纵DBMS来操纵DB
1.2 MySQL的使用
启动服务
- services.msc 进入找到MySQL进程(安装时有进程名设置)
- net start 进程名
- net stop 进程名
配置环境变量(cmd命令行启动)
- path
- 加上bin目录地址
启动MySQL
- MySQL的bin文件start界面
- 管理员cmd 输入 mysql [-h hostname主机名] [-p 端口] -u用户名 -p 密码
1.3 关系型数据库
建立在关系模型基础,由多张相互连接的二维表组成(RDBMS)
特点
- 表存储数据,格式统一,便于维护
- 存在标准的SQL操作语言,使用方便
数据模型
数据库里面有表
2. SQL
2.1 SQL通用语法
- SQL可以单行或多行书写,每条SQL语句以分号结尾
- SQL可以支持不限制数量的空格和缩进来增强代码可读性
- SQL不区分大小写,但建议关键字用大写
- 注释
- --注释内容(或#注释内容) mysql独有
- 多行 /**/
2.2分类
DDL:数据定义语言
- Data Definition Language
- 定义数据库和表以及字段
DML:数据操作语言
- Data Manipulation Language
- 对数据库数据进行增删改查
DQL:数据查询语言
- Data Query Language
- 查询数据库数据
DCL:数据控制语言
- Data Control Language
- 创建数据库用户以及访问权限管理
2.3 DDL
2.3.1 数据库
- 查询所有数据库
- show databases;
- 查询当前所处数据库
- select database();
- 创建数据库
- create database [IF NOT EXISTS] 数据库名 [DEFAULT CHARSET 字符集名] [collate 排序规则];
- 删除数据库
- drop database[ IF EXISTS ] 数据库名
- 使用数据库
- use 数据库名
2.3.2 表
- 查询当前数据库表
- show tables;
- 查询表结构
- desc 表名;
- 查询指定表的建表语句
- show create table 表名;
- 表创建

2.3.3 表修改
-
ALTER TABLE 表名 +
--字段操作 --增加字段 add 字段名 字段类型 [comment 注释][约束]; --修改字段类型 modify调整 MODIFY 字段名 新字段类型 [comment 注释][约束]; --修改字段名和类型 change修改 CHANGE 旧字段名 新字段名 新字段类型 [comment 注释][约束]; --删除字段 drop删除 DROP 字段名; --表操作 --修改表名 RENAME TO 新表名;
2.3.4 表删除
-
DROP TABLE 表名;
- 整个包括定义和数据直接删除表
-
TRUNCATE TABLE 表名;
- 删除表之后保留定义重新建一份完全相同的空表,但没有数据
- 不支持回滚
2.4 字段数据类型
数值类型
- tinyint 小整数值
- 对应(Java的byte型)
- 1位字节
- SINGNED带符号[-128,127]
- UNSIGNED不带符号[0,255]
- 大整数值
- smallint 对应short
- 2字节,带符号[-32768,32767] 不带符号[0,65535]
- mediumint 3字节
- int / integer 4字节
- smallint 对应short
- bigint
- 极大整数值 8字节
- float
- 单精度浮点 4字节
- double
- 双精度浮点 8字节
- decimal
- 小数值,由M(精度)和D(标度)决定
- 精度:带小数的数值的整长 3.14156 M = 6 D = 5
- 标度:小数点后位数
UNSIGNED数值类型不带符号使用
- age如果要用tinyint且不带符号
- age TINYINT UNSIGNED,
double限制精度和标度
- Double(4,1)限制精度和标度只能为4和1
- 一般用于分数
字符类型
- char(x)
- 存放性别char(1)
- 定长,指定长度x,当存放的字符不足x位时,会用空格代替
- 性能更高,空间的损耗带来的性能提高
- varchar(x)
- 不定长,指定最大位x,存多少位就是多少位,只会限制最大值
- 二进制数据,以二进制形式存放的文件,图片音频,但使用频率不高
- tinyblob 0-255字节
- blob 0-65535字节
- mediumblob 0-16777215字节
- longblob
- 文本字符串数据
- tinytext 短文本
- text 文本
- mediumtext 中长文本
- longtext 极大文本
时间类型
- date,存放日期,
- 一般用来存放生日等与年份无关的数据
- time,存放当天的时间
- year,年份
- datatime
- timestamp
- 也是混合了日期和时间
- 但是最高只能到2038年

2.5 DML
- Data Manipulation Language 数据操作语言
- 字符串和日期类型用引号包含
- 增加(insert)
- insert into 表名 (字段1,字段2,...) values (值1,值2,...)
- 字段匹配添加
- insert into 表名 values (值1,值2,...)
- 全表添加
- insert into 表名 (字段1,字段2,...) values(值1,值2),(值1,值2)
- 批量增加
- insert into 表名 (字段1,字段2,...) values (值1,值2,...)
- 修改(update)
- update 表名 set 字段1=值1,字段2=值2[where 条件];
- 删除(delete)
- delete from 表名 [where 条件]
- 不能删除单独的字段值,只能通过字段定位某一个元组直接删除
- 可以通过update将某个元组的字段值修改为null。
2.6 DQL
Data Query Language 数据查询语言 SELECT
- SELECT 字段(*) FROM 表名 WHERE 条件 GROUP BY 分组字段 HAVING 分组后过滤条件 ORDER BY 排序字段 LIMIT 分页参数
- 通配符
- *代表查询所有字段
- 设置别名
- SELECT 字段[AS 别名1],字段[AS 别名2] FROM 表;
- 去重
- SELECT DISTINCT 字段 FROM 表名;
条件查询
- BETWEEN...AND...
- 在...与...之间的值,含边界
- IN(...)
- 在列表中的值,多选1
- LIKE
- _ 单个字符占位符 ,模糊匹配
- % 任意个字符占位符
- IS NULL
- 是NULL
- 逻辑运算符
- &&(AND)
- ||(OR)
- NOT(!)
聚合函数查询
纵向比较一列数据,所有null值不进行聚合函数运算,一般与聚合的字段一起参与SQL方便显示
- count 个数
- SELECT gender, COUNT(*) FROM user GROUP BY gender;
- max
- min
- avg
- sum
- 语法
- SELECT 聚合函数(字段) FROM 表名;
分组查询
GROUP BY(字段) HAVING 过滤条件
- where > 聚合 > having
- 分组之后,查询的字段只能为聚合函数和分组的字段,其他字段失去意义
- 分组之后,分组的依据字段有几个值,分组之后就只有几个元组
- 分组之后只会对该字段进行聚合运算的值有意义,其他字段的值会被相同的分组依据缩减
排序查询
ORDER BY 字段1 排序方式1,字段2 排序2;
- ASC 升序
- DESC 降序
分页查询
LIMIT 起始索引,查询个数;
- 从0开始,分页查询中每一页的起始索引为LIMIT(页数-1)* 每页记录数
- 不同数据库有不同实现,MySQL是LIMIT
DQL执行顺序
- FROM --先知道查哪个表
- WHERE --条件筛选
- GROUP BY -- 分组筛选过滤
- HABVING
- SELECT --返回的字段值
- ORDER BY
- LIMIT
2.7 DCL
Data Controller Language 数据控制语言 管理数据库用户和权限
2.7.1 管理用户
-
查看当前数据库的用户
-
USE mysql; select * from user; --MySQL的用户一般存在mysql数据库的user表里
-
-
创建用户
-
CREATE user '用户名'@'主机地址' IDENTIFIED BY '密码'; -- 主机地址可以用通配符%代表全部主机都可以访问
-
-
修改密码
-
--ALTER关键字 IDENTIFIED WITH 加密方式 BY alter user '用户名'@'主机地址' IDENTIFIED WITH mysql_native_password BY '新密码';
-
-
删除用户
-
DROP user '用户名'@'主机地址';
-
2.7.2 权限控制

-
查询权限
-
SHOW GRANTS FOR '用户名'@'主机地址';
-
-
赋予权限
-
-- 通配符*.*可以代表全数据的全表 GRANT 权限名 ON 数据库.表名 TO '用户名'@'主机地址';
-
-
剥夺权限
-
REVOKE 权限名 ON 数据库.表 FROM '用户名'@'主机地址';
-
3. 函数
MySQL内置的可以直接被另一端程序直接调用的程序或代码
3.1 字符串函数
- concat(s1,s2,...) 拼接
- trim(s) 去除s的前后空格
- lower(str) 小写
- upper(str) 大写
- substring(str,start,len)
- 下标从1开始
- 补充字符串达到长度为n
- lpad(str,n,pad) 用pad对str的左边进行填充
- rpad(str,n,pad) 用pad对str的右边进行填充
- 可以用select 函数来显示结果
3.2 数值函数
- ceil(x)
- 向上取整 ceil(1.1~1.9) = 2
- floor(x)
- 向下 floor(1.1-1.9) = 1
- mod(x,y)
- 取模 =x%y
- round(x,y)
- 四舍五入 x保留y个小数位的值
- rand()
- 0-1的随机数
3.3 日期函数
-
curdate()
- 当前日期
-
curtime()
- 当前时间
-
now()
- 当前时间和日期
-
获得指定date的年份,月份,日期
- year(date)
- month(date)
- day(date)
-
date_add(date,interval_expr type)
-
在date的基础上加一个时间间隔interval_expr之后的时间,后面要规定单位type
-
select date_add('2018-09-16 20:30:15',interval 1291 DAY );
-
-
datediff(date1,date2)
- date1和date2的日期间隔,date1-date2
3.4 流程函数
-
IF(value,T,F)
- 如果value返回的值是真,就输出T的值,反之F。
-
IFNULL(value1,value2)
- 如果value1为null,返回value2,反之返回value1本身。
-
CASE [字段] WHEN [val1] THEN [val1] ELSE [val3]... default[end]
-
val可以是值也可以是表达式
-
如果字段是val1就返回then后面的val2
-
不是就返回else后面的val3
-
end结束
select name, case when status=1 then '好家伙' else '坏家伙' end as '成色' from goods;
-
力扣实例
行转列用CASE WHEN
1.[1873]写出一个SQL 查询语句,计算每个雇员的奖金。如果一个雇员的id是奇数并且他的名字不是以'M'开头,那么他的奖金是他工资的100%,否则奖金为0。
select employee_id,
CASE WHEN MOD(employee_id,2)!=0 AND name NOT LIKE "M%"
THEN salary ELSE 0 END AS bonus
FROM Employees;
2.[627]请你编写一个 SQL 查询来交换所有的 'f' 和 'm' (即,将所有 'f' 变为 'm' ,反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。
注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句
UPDATE Salary SET
sex=
IF(sex = 'm' , 'f','m');
#或
UPDATE Salary SET
sex =
CASE WHEN sex = 'm' THEN 'f' ELSE 'm' END;
3.[196]编写一个SQL查询来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。
DELETE p2 FROM Person p1,Person p2
WHERE p1.email = p2.email and p1.id < p2.id;
4.[1667]编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。
返回按 user_id 排序的结果表
SELECT user_id,
CONCAT(UPPER(SUBSTRING(name,1,1)),LOWER(SUBSTRING(name,2))) AS name
FROM Users
ORDER BY user_id ASC
GROUP_CONCAT 组内拼接函数
5.[1484]编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。
每个日期的销售产品名称应按词典序排列。
返回按 sell_date 排序的结果表
SELECT sell_date,
--去除重复的产品计算个数
COUNT(DISTINCT product) AS num_sold,
--按日期分组后,将每一组拼接在一起,且按字典序排序,每一个后面加,分隔符为''
GROUP_CONCAT(DISTINCT product ORDER BY product,'') AS products
FROM Activities
GROUP BY sell_date
ORDER BY sell_date
6.写一条 SQL 语句,查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。
SELECT * FROM Patients
WHERE conditions LIKE 'DIAB1%' OR conditions LIKE '% DIAB1%'
7.写出一个查询语句,找到所有 丢失信息 的雇员id。当满足下面一个条件时,就被认为是雇员的信息丢失:
雇员的 姓名 丢失了,或者
雇员的 薪水信息 丢失了,或者
返回这些雇员的id employee_id , 从小到大排序
SELECT Salaries.employee_id
FROM Salaries LEFT JOIN Employees ON Salaries.employee_id = Employees.employee_id
WHERE Employees.name is null
UNION
SELECT Employees.employee_id
FROM Employees LEFT JOIN Salaries ON Salaries.employee_id = Employees.employee_id
WHERE Salaries.salary is null
ORDER BY employee_id
列转行UNION
8.请你重构 Products 表,查询每个产品在不同商店的价格,使得输出的格式变为(product_id, store, price) 。如果这一产品在商店里没有出售,则不输出这一行
SELECT * FROM
(
SELECT product_id,'store1' as store,store1 as price FROM products
UNION
SELECT product_id,'store2' as store,store2 as price FROM products
UNION
SELECT product_id,'store3' as store,store3 as price FROM products
) t
WHERE price IS NOT NULL
Tree and DISTINCT
9.给定一个表 tree,id 是树节点的编号, p_id 是它父节点的 id树中每个节点属于以下三种类型之一:
- 叶子:如果这个节点没有任何孩子节点。
- 根:如果这个节点是整棵树的根,即没有父节点。
- 内部节点:如果这个节点既不是叶子节点也不是根节点。
写一个查询语句,输出所有节点的编号和节点的类型,并将结果按照节点编号排序。

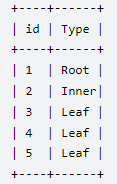
SELECT id,
CASE WHEN p_id IS NULL THEN 'Root'
WHEN id IN (SELECT p_id FROM tree) THEN 'Inner'
ELSE 'Leaf' END
AS type
FROM tree
10.编写一个 SQL 查询,获取并返回 Employee 表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回 null
SELECT
IFNULL(
(SELECT DISTINCT salary FROM Employee ORDER BY salary DESC #降序排列薪水
LIMIT 1,1) ,NULL) #取第二条,如果为空则NULL
AS SecondHighestSalary
4. 约束
作用于表中字段的规则,限制存储在表的数据
4.1 作用
- 保证数据库数据的正确性、有效性、完整性。
- 因为是作用于表字段,所以在DDL定义阶段就添加约束。
- 多个约束之间用空格分开
4.2 分类
- 非空约束
- NOT NULL
- 不为null
- 唯一约束
- UNIQUE
- 不存在重复值
- 主键约束
- PRIMARY KEY
- 一个元组的唯一标识,满足唯一且非空
- 默认约束
- DEFAULT
- 默认值
- 检查约束(8.0.16之后)
- CHECK
- check(条件&&条件)
- 保证字段值满足某一个条件(自定义)
- 外键约束
- FOREIGN KEY
- 在两张表之间建立连接,保证数据的一致性和完整性

4.3 外键约束
4.3.1 主表(父表)和从表(子表)
- 具有外键的为从表或者称为子表
- 外键关联的主键表为父表或主表
4.3.2 添加外键
-
定义阶段
-
[CONSTRAINT][外键名] FOREIGN KEY (外键字段名) REFERENCE 主表(主表列名)
-
-
执行阶段
-
--CONSTRAINT (约束) --ADD CONSRAINT 添加约束 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCE 主表(主表列名);
-
-
删除外键
-
ALTER TABLE 表名 DROP CONSTRAINT FOREIGN KEY 外键名称;
-
4.3.3 外键删除更新行为
- NO ACTION(默认)
- RESTRICT
- noaction和restrict 一致,主表在进行删除更新记录时,如果发现有对应外键连接的自身的主键,就无法删除更新
- CASCADE
- 级联
- 如果有对应外键,当主表进行删除更新时,所有从表的外键记录会更新
- SET NULL
- 当主表删除更新,从表的外键值允许空值,就将对应的外键设为null
- SET DEFAULT
- 从表的外键设为默认值,Innodb不支持

修改更新级联策略
--级联
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCE 主表(主表列名) ON UPDATE CASCADE ON DELETE CASCADE;
-- set null
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCE 主表(主表列名) ON UPDATE set null ON DELETE set null;
5. 多表查询
5.1 多表关系
- 一对一
- 主表拆分一对一
- 在任意一方加入一个唯一unique的外键(与一对多的区别)
- 一对多
- 部门-员工
- 多的一方建立外键指向一的主键
- 多对多
- 学生-课程
- 建立第三张中间表,包含两个外键关联双方主键
5.2 多表查询
- 笛卡尔积
- select * from emp ,dept
- 两张表所有值的所有组合情况,元组数相乘,属性数相加
- 从表的每一行会与主表的每一行都组合一次,没有对应关系,比如每一个员工会和每一个部门都结合一次
- 多表查询
- 通过条件消除无效的笛卡尔积,留下员工对应的部门
5.2.1 多表查询分类
- 连接查询
- 内连接
- 查询A与B的交集部分数据
- 外连接
- 左外连
- 查询左表的全部数据和交集数据
- 右外连
- 查询右表的全部数据和交集数据
- 左外连
- 自连接
- 当前表与自身连接,用到别名区分
- 内连接
- 子查询
5.2.2 内连接
查询A与B的交集部分数据
- 隐式内连接
select * from A,B where A.bid = B.id;
- 显式内连接(效率更高)
select * from A [INNER] JOIN B where A.bid = B.id;
5.2.3 外连接
--左外连接,包含左表所有数据,与内连接相比可以保留左边的null值
select * from A LEFT [OUTER] JOIN B ON A.bid = B.id;
--右外连接,包含右表所有数据,与内连接相比可以保留右边的null值
select * from A RIGHT [OUTER] JOIN B ON A.bid = B.id;
5.2.4 自连接
- 可以是内连接也可以是外连接
- 一定要用别名来区分该表的含义
select 字段 FROM A 别名1 JOIN A 别名2 ON 条件;
- 外键对应的自身的主键--员工的领导
- 领导也是员工,所以领导id=员工id
5.2.5 联合查询
多次查询结果合并,形成新的查询结果集 列转行思路
- union
- 去重联合
- union all
- 直接联合
select * from A where xxx
union
select * from A where xxx
--select 的字段列要保持一致
5.2.6 子查询
嵌套查询,在SQL语句中嵌套使用SELECT,用查询的结果作为查询的对象
--子查询的外部可以是INSERT/UPDATE/DELETE/SELECT
select * from (select * from A where xxx);
分类:
根据子查询结果(主查询语句的对象)不同
- 标量子查询:子查询结果为单个值
- 常用操作符:>,<,>=,<=,<>
- 列子查询:子查询结果为单列
- 常用操作符:IN,NOT IN,ANY,SOME,ALL
- IN,NOT IN:是否存在子查询结果中
- ANY,SOME : 子查询结果中满足任意一个即可
- ALL:查询条件全部满足子查询结果
- 常用操作符:IN,NOT IN,ANY,SOME,ALL
--查询所有研发部的人的工资
(select salary from emp where dept_id = (select id from dept where name = '研发部'));
--查询比研发部的所有人工资高的员工信息
select * from emp where salary > all(select salary from emp where dept_id = (select id from dept where name = '研发部'));
--查询比研发部任意一个人工资高的员工信息
select * from emp where
salary > any/some(select salary from emp where dept_id = (select id from dept where name = '研发部'));
- 行子查询:子查询结果为单行
- 操作符:= <> IN NOT IN
--查询和张无忌的领导与薪资相同的员工
--1.查询张无忌的薪资和领导 (薪资,领导)
select salary,manage from emp where name = '张无忌';
--2.查询和张无忌的领导与薪资相同的员工 =
select * from emp where (salary,manage) = (select salary,manage from emp where name = '张无忌');
- 表子查询:子查询结果为多行多列
- 操作符IN
--查询员工入职日期在'2009-01-10'之后的员工以及部门信息
-- 1. 查询员工入职日期在'2009-01-10'之后的员工信息
select * from emp where date > '2009-01-10';
-- 2. 查询部门信息
select emp.*,dept.* from (select * from emp where date > '2009-01-10' left join dept on emp.dept_id = dept.id);
根据子查询位置
- where之后
- from之后
- select之后
6. 事务
事务是一组操作的集合,作为一个不可分割的整体向系统提交或撤销,事务要么一起成功,要麽一起失败
6.1 事务提交方式
- 查看并修改事务提交方式
--查看当前事务提交
SELECT @@autocommit;
-- =1 自动提交,=0 手动提交
SET @@autocommit = 0;
- 提交事务
- COMMIT;
- 回滚事务
- 设置了手动提交,如果发生了异常不能commit的情况我们不能继续update数据回到操作以前,因为一直处于一个当前为提交的事务里,可以通过回滚操作回到事务开始之前。
- ROLLBACK;
6.2 事务的开启
修改提交事务的方式会导致效率降低,我们会对某些特殊的业务提高手动提交的方式,这就需要开启事务操作
--开启事务
START TRANSACTION / BEGIN
--提交和回滚
commit rollback
6.3 事务ACID事务特性
6.3.1 原子性(Atomicity)
- 事务是不可分割的最小单元,要么一起完成,要么一起失败
6.3.2 一致性(Consistency)
- 事务完成后,要保证数据都保持一致状态
6.3.3 隔离性(Isolation)
- 接触DBMS提供的隔离机制,保证事务不受外部并发操作的影响独立完成
6.3.4 持久性(Durability)
- 事务一旦提交或回滚,它对数据库的数据改变是永久改变的
6.4 事务并发影响
6.4.1 脏读
- 一个事务读取到另一个事务还没有提交的
6.4.2 不可重复读
- 一个事务先后两次读取同一个数据却发现不同,两次操作之间有事务提交了修改
6.4.3 幻读
- 当解决了不可重复读的问题之后可以使前后的读取不改变
- 那么当事务查询某条数据发现为空,准备插入新数据时,另一个事务提交了插入,那么当前事务的插入发生了主键冲突
- 但因为先后读取不会改变,所以每次读取都是没有该数据,但插入却不能成功的错觉
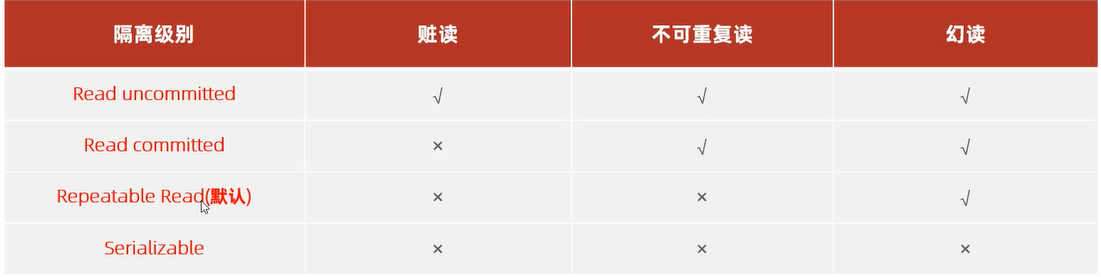
6.5 事务的隔离级别
6.5.0 查看修改隔离级别
-- 查看隔离级别
SELECT @@TRANSACTION_ISOLATION;
/ select @@tx_isolation;
-- 修改隔离级别
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL {READUNCOMMITTED|READ COMMITTED|REPEATABLE|SERIALIZEABLE};
--[SESSION|GLOBAL]:设置当前会话或全局(会话就是当前客户端)
--{READUNCOMMITTED|READ COMMITTED|REPEATABLE|SERIALIZEABLE}四种级别
6.5.1 读未提交 Read
- Read uncommitted 性能最强但数据安全性差
- 脏重复幻都存在
6.5.2 读已提交(Oracle默认)
- Read committed
6.5.3 可重复读(MySQL默认)
- Repeatable Read
6.5.4 串行化
- Serializable,性能最差,安全性最强
- 拒绝并发,加锁