一、Hash算法(或者叫Hash取模算法):
Hash算法可以理解为:
假设有3台服务器(0,1,2)数量:N=3,
缓存项(例如:图片):test.jpg
结果取模:R = hash(test.jpg)%3
R 的结果在0,1,2中
R = 0 则缓存在第1台服务器,R = 1缓存在第2台服务器,R = 2缓存在第3台服务器。
同理,查询后者缓存命中也是如此。

优点:对比不用Hsah算法,假如有3台缓存服务器,之前有一张图片test.jpg已经被缓存到3台服务器中的一台,但是需要命中缓存;如果不用试Hash算法就得去每个服务器遍历!当服务器数量多的时候呢?效率很低,这与HashMap中put或者get值时候需要查找该key是否存在的原理是一样的。
使用Hash算法可以定位到某一台服务器(HashMap则通过对key进行Hash取值找到数组的下标位置,然后再通过对象的equals来最终判断)而不用去遍历其他的缓存服务器了。效率值高了。
缺点:模块的数N=3表示服务器数目,是一个变量。所以会存在缓存雪崩的情况。因为服务器数量不是一层不变的,可能会增加数量后者宕机的情况。所以此些情况出现时N会发生变化,则缓存全部都不会命中。
二、一致性Hash算法
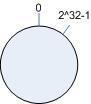
一致性Hash算法有个Hash环的概念。整个环就是2^32个整数,从0~2^32 -1 。类似一个时钟一样。
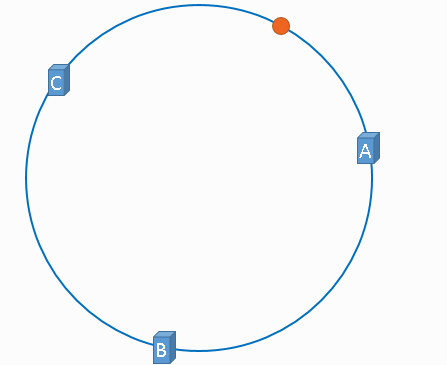
服务器位置和缓存项的位置都是通过取模后确认在Hash环上的某一个具体位置。然后缓存项的位置会缓存到顺时针Hash环到最近的一个上的服务器。
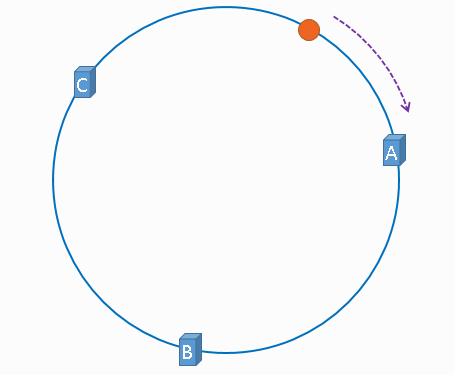
相同点:算法都需要进行取模运算
不同点:
1.取模的数不一样,Hash算法取模的数是服务器数量N,是变量;一致性Hash算法取模数则是常量N=2^32
2.Hash算法取模运算只做一次,一致性Hash运算运算会做2次【首先根据Hash(服务器ip)%2^32确定服务器再Hash环上的位置,然后通过Hash(缓存项)%2^32确定缓存项再Hash环上的位置】
运用一致性Hash算法时,当服务器数量发生变化,同样也会导致缓存不能命中,只是其中的一部分。即从发生变化的服务器的位置到它上个服务器位置(逆时针Hash环到最近的一个服务器位置)之前的缓存项会收到影响的。但是当服务器数量较多时,收到的影响也比较小。
当然确定服务器再Hash环上的位置时,不可能是理想状态(服务器再环上的分布均匀的);
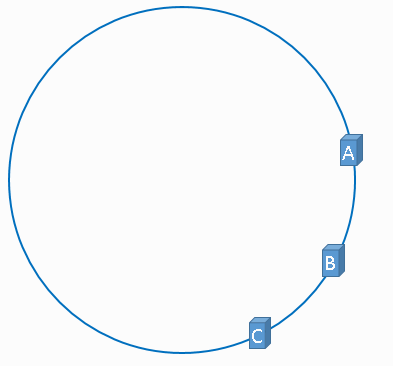
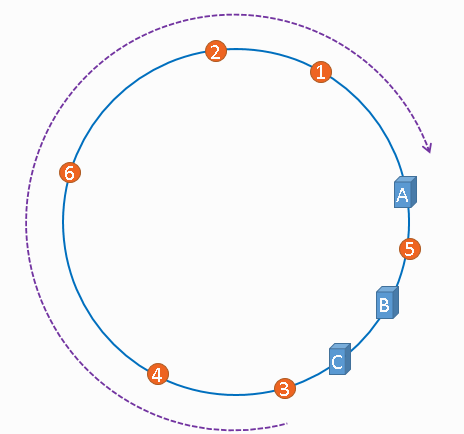
Hash(服务器ip)%2^32坑出现例如服务器1在0,服务器2在1,那么这种极端情况同样会产生雪崩。所以引入虚拟节点!当每个真实服务器的虚拟节点较多时,就可以看成是均匀分布的了、

memcache的一致性hash算法