一 ActiveMQ实战之二 限时订单
1)轮询数据库会带来什么问题?
轮询数据库在实现限时订单上是可行的,而且实现起来很简单。写个定时器去每隔一段时间扫描数据库,检查到订单过期了,做适当的业务处理。
但是轮询会带来什么问题?
1、轮询大部分时间其实是在做无用功,我们假设一张订单是45分钟过期,每分钟我们扫描一次,对这张订单来说,要扫描45次以后,才会检查到这张订单过期,这就意味着数据库的资源(连接,IO)被白白浪费了;
2、处理上的不及时,一个待支付的电影票订单我们假设是12:00:35过期,但是上次扫描的时间是12:00:30,那么这个订单实际的过期时间是什么时候?12:01:30,和我本来的过期时间差了55秒钟。放在业务上,会带来什么问题?这张电影票,假设是最后一张,有个人12:00:55来买票,买得到吗?当然买不到了。那么这张电影票很有可能就浪费了。如果缩短扫描的时间间隔,第一只能改善不能解决,第二,又会对数据库造成更大的压力。
那么我们能否有种机制,不用定时扫描,当订单到期了,自然通知我们的应用去处理这些到期的订单呢?
-1)来自Java本身的解决方案
java其实已经为我们提供了问题的方法。我们想,要处理限时支付的问题,肯定是要有个地方保存这些限时订单的信息的,意味着我们需要一个容器,于是我们在Java容器中去寻找。Map? List? Queue?
看看java为我们提供的容器,我们是个多线程下的应用,会有多个用户同时下订单,所以所有并发不安全的容器首先被排除,并发安全的容器有哪些?一一排除,很巧,java在阻塞队列里为我们提供了一种叫延迟队列delayQueue的容器,刚好可以为我们解决问题。
DelayQueue: 阻塞队列(先进先出)
1)支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满。2)支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空。
延迟期满时才能从中提取元素(光队列里有元素还不行)。
Delayed接口使对象成为延迟对象,它使存放在DelayQueue类中的对象具有了激活日期。该接口强制实现下列两个方法。
• CompareTo(Delayed o):Delayed接口继承了Comparable接口,因此有了这个方法。让元素按激活日期排队
• getDelay(TimeUnit unit):这个方法返回到激活日期的剩余时间,时间单位由单位参数指定。
2)架构师应该多考虑一点!
架构师在设计和实现系统时需要考虑些什么?
功能,这个没什么好说,实现一个应用,连基本的功能都没实现,要这个应用有何用?简直就是“一顿操作猛如虎,一看战绩零比五”
高性能,能不能尽快的为用户提供服务和能为多少用户同时提供服务,性能这个东西是个很综合性的东西,从前端到后端,从架构(缓存机制、异步机制)到web容器、数据库本身再到虚拟机到算法、java代码、sql语句的编写,全部都对性能有影响。如何提升性能,要建立在充分的性能测试的基础上,然后一个个的去解决性能瓶颈。对我们今天的应用来讲,我们不想去轮询数据库,其实跟性能有非常大的关系。
高可用,应用正确处理业务,服务用户的时间,这个时间当然是越长越好,希望可以7*24小时。而且哪怕服务器出现了升级,宕机等等情况下,能够以最短的时间恢复,为用户继续服务,但是实际过程中没有哪个网站可以说做到100%,不管是Google,FaceBook,阿里,腾讯,一般来说可以做到99.99%的可用性,已经是相当厉害了,这个水平大概就是一个服务在一年可以做到只有50分钟不可用。这个需要技术、资金、技术人员的水平和责任心,还要运气。
高伸缩,伸缩性是指通过不断向集群中加入服务器的手段来缓解不断上升的用户并发访问压力和不断增长的数据存储需求。就像弹簧一样挂东西一样,用户多,伸一点,用户少,,缩一点。衡量架构是否高伸缩性的主要标准就是是否可用多台服务器构建集群,是否容易向集群中添加新的服务器。加入新的服务器后是否可以提供和原来服务器无差别的服务。集群中可容纳的总的服务器数量是否有限制。
高扩展,的主要标准就是在网站增加新的业务产品时,是否可以实现对现有产品透明无影响,不需要任何改动或者很少改动既有业务功能就可以上线新产品。比如购买电影票的应用,用户购买电影票,现在我们要增加一个功能,用户买了票后,随机抽取用户送限量周边。怎么做到不改动用户下订单功能的基础上增加这个功能。熟悉设计模式的同学,应该很眼熟,这是设计模式中的开闭原则(对扩展开放,对修改关闭)在架构层面的一个原则。
3)从系统可用性角度考虑:应用重启了怎么办?
应用重启带来的问题:
保存在Queue中的订单会丢失,这些丢失的订单会在什么时候过期,因为队列里已经没有这个订单了,无法检查了,这些订单就得不到处理了。
已过期的订单不会被处理,在应用的重启阶段,可能会有一部分订单过期,这部分过期未支付的订单同样也得不到处理,会一直放在数据库里,过期未支付订单所对应的资源比如电影票所对应的座位,就不能被释放出来,让别的用户来购买。
解决之道 :在系统启动时另行处理
4)从系统伸缩性角度考虑:应用集群化了怎么办?
集群化了会带来什么问题?应用之间会相互抢夺订单,特别是在应用重启的时候,重新启动的那个应用会把不属于自己的订单,也全部加载到自己的队列里去,一是造成内存的浪费,二来会造成订单的重复处理,而且加大了数据库的压力。
解决方案
让应用分区处理
1、 给每台服务器编号,然后在订单表里登记每条订单的服务器编号;2,更简单的,在订单表里登记每台服务器的IP地址,修改相应的sql语句即可。
几个问题:如果有一台服务器挂了怎么办?运维吃干饭的吗?服务器挂了赶紧启动啊。如果是某台服务器下线或者宕机,起不来怎么搞?这个还是还是稍微有点麻烦,需要人工干预一下,手动把库里的每条订单数据的服务器编号改为目前正常的服务器的编号,不过也就是一条sql语句的事,然后想办法让正常的服务器进行处理(重启正常的服务器)。
5)能不能同时解决伸缩性和扩展性问题?
用delayqueue是队列,分布式情况我们何不直接引入消息中间件呢?一举解决我们应用的伸缩性和扩展性问题
ActiveMQ的延迟和定时投递:
修改配置文件(activemq.xml),增加延迟和定时投递支持
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost" dataDirectory="${activemq.data}" schedulerSupport="true">
需要把几个描述消息定时调度方式的参数作为属性添加到消息,broker端的调度器就会按照我们想要的行为去处理消息。
一共有4个属性
1:AMQ_SCHEDULED_DELAY :延迟投递的时间
2:AMQ_SCHEDULED_PERIOD :重复投递的时间间隔
3:AMQ_SCHEDULED_REPEAT:重复投递次数
4:AMQ_SCHEDULED_CRON:Cron表达式
ActiveMQ也提供了一个封装的消息类型:org.apache.activemq.ScheduledMessage,可以使用这个类来辅助设置,使用例子如:延迟60秒
MessageProducer producer = session.createProducer(destination);
TextMessage message = session.createTextMessage("test msg");
long time = 60 * 1000;
message.setLongProperty(ScheduledMessage.AMQ_SCHEDULED_DELAY, time);
producer.send(message);
例子:延迟30秒,投递10次,间隔10秒:
TextMessage message = session.createTextMessage("test msg");
long delay = 30 * 1000;
long period = 10 * 1000;
int repeat = 9;
message.setLongProperty(ScheduledMessage.AMQ_SCHEDULED_DELAY, delay);
message.setLongProperty(ScheduledMessage.AMQ_SCHEDULED_PERIOD, period);
message.setIntProperty(ScheduledMessage.AMQ_SCHEDULED_REPEAT, repeat);
也可使用 CRON 表达式,如message.setStringProperty(ScheduledMessage.AMQ_SCHEDULED_CRON, "0 * * * *");
代码的变化
1、 保存订单SaveOrder.java的时候,作为生产者往消息队列里推入订单,展示和修改MqProducer,这个类当然是要继承IDelayOrder
2、 消息队列会把过期订单发给消费者MqConsume,由它来负责检查订单是否已经支付和过期,来进行下一步处理。
消息队列本身又如何保证可用性和伸缩性?这个就需要ActiveMQ的集群化。
二 构建ActiveMQ集群
ActiveMQ的集群方式综述
ActiveMQ的集群方式主要由两种:Master-Slave和Broker Cluster
Master-Slave
Master-Slave方式中,只能是Master提供服务,Slave是实时地备份Master的数据,以保证消息的可靠性。当Master失效时,Slave会自动升级为Master,客户端会自动连接到Slave上工作。Master-Slave模式分为四类:Pure Master Slave、Shared File System Master Slave和JDBC Master Slave,以及Replicated LevelDB Store方式 。
Master-Slave方式都不支持负载均衡,但可以解决单点故障的问题,以保证消息服务的可靠性。
Broker Cluster
Broker Cluster主要是通过network of Brokers在多个ActiveMQ实例之间进行消息的路由。Broker Cluster模式支持负载均衡,可以提高消息的消费能力,但不能保证消息的可靠性。所以为了支持负载均衡,同时又保证消息的可靠性,我们往往会采用Msater-Slave+Broker Cluster的模式。
注意:
以下的测试均在一台机器上进行,为避免多个ActiveMQ之间在启动时发生端口冲突,需要修改每个ActiveMQ的配置文件中MQ的服务端口。如果实际部署在不同的机器,端口的修改是不必要的。
1)Pure Master Slave方式
ActiveMQ5.8以前支持,自从Activemq5.8开始,Activemq的集群实现方式取消了传统的Pure Master Slave方式,并从Activemq5.9增加了基于zookeeper+leveldb的实现方式。
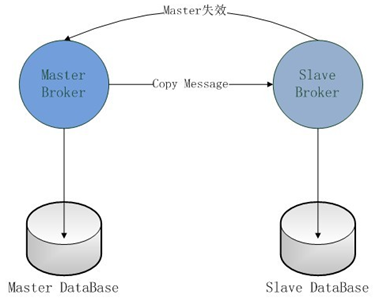
使用两个ActiveMQ服务器,一个作为Master,Master不需要做特殊的配置;另一个作为Slave,配置activemq.xml文件,在<broker>节点中添加连接到Master的URI和设置Master失效后不关闭Slave。具体配置参考页面:http://activemq.apache.org/pure-master-slave.html
2)Shared File System Master Slave方式

就是利用共享文件系统做ActiveMQ集群,是基于ActiveMQ的默认数据库kahaDB完成的,kahaDB的底层是文件系统。这种方式的集群,Slave的个数没有限制,哪个ActiveMQ实例先获取共享文件的锁,那个实例就是Master,其它的ActiveMQ实例就是Slave,当当前的Master失效,其它的Slave就会去竞争共享文件锁,谁竞争到了谁就是Master。这种模式的好处就是当Master失效时不用手动去配置,只要有足够多的Slave。
如果各个ActiveMQ实例需要运行在不同的机器,就需要用到分布式文件系统了。
3)Shared JDBC Master Slave
JDBC Master Slave模式和Shared File Sysytem Master Slave模式的原理是一样的,只是把共享文件系统换成了共享数据库。我们只需在所有的ActiveMQ的主配置文件中activemq.xml添加数据源,所有的数据源都指向同一个数据库。
然后修改持久化适配器。这种方式的集群相对Shared File System Master Slave更加简单,更加容易地进行分布式部署,但是如果数据库失效,那么所有的ActiveMQ实例都将失效。
配置修改清单
1、开启网络监控功能(useJmx="true")
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost" dataDirectory="${activemq.data}" useJmx="true">
2、数据库持久化配置,注释掉之前kahadb消息存储器
<persistenceAdapter>
<jdbcPersistenceAdapter dataDirectory="${activemq.data}" dataSource="#mysql-ds" createTablesOnStartup="false" useDatabaseLock="true"/>
</persistenceAdapter>
3、增加数据源mysql-ds
4、修改客户端上连接url为类似于failover:(tcp://0.0.0.0:61616,tcp://0.0.0.0:61617,tcp://0.0.0.0:61618)?randomize=false
注:默认情况下,failover机制从URI列表中随机选择出一个URI进行连接,这可以有效地控制客户端在多个broker上的负载均衡,但是,要使客户端首先连接到主节点,并在主节点不可用时只连接到辅助备份代理,需要设置randomize = false。
5、可以看到只有一台MQ成为Master,其余两台成为slave并会尝试成为Master,并不断重试。且两台slave的管理控制台将无法访问。
测试方法
1. 先启动生产者,发送几条消息
2. 启动消费者,可看到接收到的消息
3. 关闭消费者
4. 生产者继续发送几条消息-消息A
5. 停止broker01(可看到生产者端显示连接到broker02(tcp://0.0.0.0:61617)了,同时运行broker02的Shell也显示其成为了Master)
6. 生产者继续发送几条消息-消息B
7. 启动消费者
8. 消费者接收了消息A和消息B,可见broker02接替了broker01的工作,而且储存了之前生产者经过broker01发送的消息
9. 关闭消费者
10. 生产者继续发送几条消息-消息C
11. 停止broker02(可看到生产者端显示连接到broker03(tcp://0.0.0.0:61618)了,同时运行broker03的Shell也显示其成为了Master)
12. 生产者继续发送几条消息-消息D
13. 启动消费者
14. 消费者接收了消息C和消息D,可见broker03接替了broker02的工作,而且储存了之前生产者经过broker02发送的消息
15. 再次启动broker01,生产者或消费者均未显示连接到broker01(tcp://0.0.0.0:61616),表明broker01此时只是个Slave
4)Replicated LevelDB Store
ActiveMQ5.9以后才新增的特性,使用ZooKeeper协调选择一个node作为master。被选择的master broker node开启并接受客户端连接。 其他node转入slave模式,连接master并同步他们的存储状态。slave不接受客户端连接。所有的存储操作都将被复制到连接至Master的slaves。
如果master死了,得到了最新更新的slave被允许成为master。推荐运行至少3个replica nodes。

配置修改清单
1、 使用性能比较好的LevelDB替换掉默认的KahaDB
<persistenceAdapter>
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62623"
zkAddress="127.0.0.1:2181"
hostname="localhost"
zkPath="/activemq/leveldb-stores"/>
</persistenceAdapter>
配置项说明:
- directory:持久化数据存放地址
- replicas:集群中节点的个数
- bind:集群通信端口
- zkAddress:ZooKeeper集群地址
- hostname:当前服务器的IP地址,如果集群启动的时候报未知主机名错误,那么就需要配置主机名到IP地址的映射关系。
- zkPath:ZooKeeper数据挂载点
2、修改客户端上连接url为failover:(tcp://0.0.0.0:61616,tcp://0.0.0.0:61617,tcp://0.0.0.0:61618)?randomize=false
3、可以看到只有一台MQ成为Master,其余两台成为slave。且两台slave的管理控制台将无法访问。
三 LevelDB解释
Leveldb是一个google实现的非常高效的kv数据库,目前的版本1.2能够支持billion级别的数据量了。 在这个数量级别下还有着非常高的性能,采用单进程的服务,性能非常之高,在一台4核Q6600的CPU机器上,每秒钟写数据超过40w,而随机读的性能每秒钟超过10w。由此可以看出,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,也就是说,LevelDB很适合应用在查询较少,而写很多的场景。LevelDB应用了LSM (Log Structured Merge) 策略,通过一种类似于归并排序的方式高效地将更新迁移到磁盘,降低索引插入开销。
限制:1、非关系型数据模型(NoSQL),不支持sql语句,也不支持索引;2、一次只允许一个进程访问一个特定的数据库;3、没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server;