摘要:本文是我们对clickhouse做了最简单的支持obs的适配改造。
本文分享自华为云社区《clickhouse存算分离在华为云实践》,作者: he lifu。
clickhouse是一款非常优秀的OLAP数据库系统,2016年刚开源的时候就因为卓越的性能表现得到大家的关注,而近两年国内互联网公司的大规模应用和推广,使得它在业内声名鹊起,且受到了大家一致的认可。
从网络上公开分享的资料和客户使用的案例总结来看,clickhouse主要是应用在实时数仓和离线加速两个场景,其中有些实时业务为了追求极致的性能会上全SSD的配置,考虑到实时数据集的有限规模,这种成本尚能够接受,但是对于离线加速的业务,数据集普遍会很大,这个时候上全SSD配置的成本就会显得昂贵了,有没有办法既能满足较高的性能又能把成本控制的尽量低?我们的想法是弹性伸缩,把数据存储到低廉的对象存储上面,通过动态增加计算资源的方式满足高频时段的高性能需求,通过回收计算资源的方式控制低频时段的成本,所以我们把目标放在了存算分离这个特性上。
一.存算分离现状
clickhouse是存算一体的数据库系统,数据是直接落在本地磁盘上(包括云硬盘),关注社区动态的读者已经知道最新的版本可以支持数据持久化到对象存储和HDFS上了,以下是我们对clickhouse做了最简单的支持obs的适配改造,和原生的支持S3一样:
1.配置S3磁盘
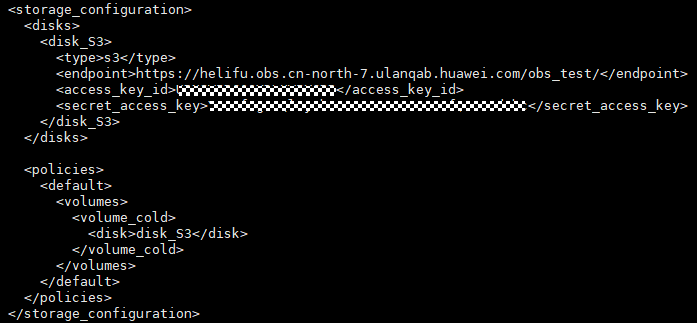
2.创建表并灌入数据

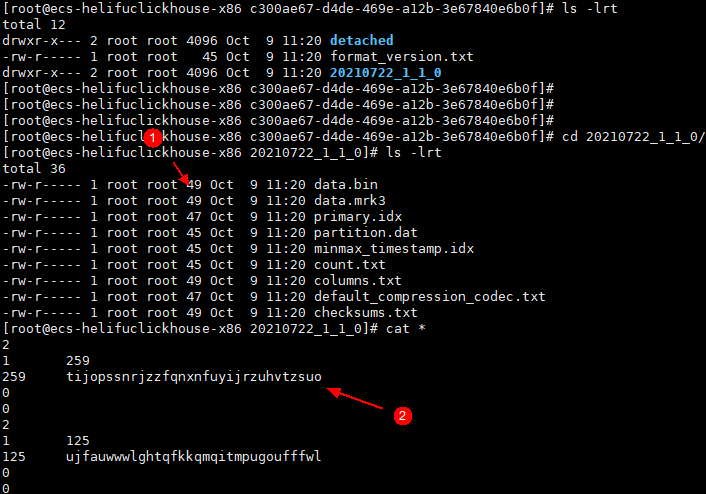
3.检查本地盘数据
4.检查对象存储数据
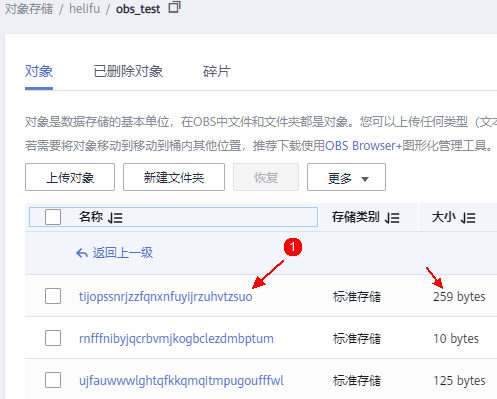
从上面几个图片来看, 可以发现本地磁盘上的数据文件内容记录了obs上的文件名(uuid),也就是说clickhouse和obs对象之间是通过本地数据文件中的“映射”关系关联起来的,注意这个“映射”关系是持久化在本地的,意味着需要冗余以满足可靠性。
然后进一步,我们看到社区也在努力把clickhouse往存算分离的方向推进:
- v21.3版本引入的Add the ability to backup/restore metadata files for DiskS3,允许把本地数据文件到obs对象的映射关系、本地数据的目录结构等属性,放到obs对象的属性里(object的metadata),这样解耦了数据目录必须在本地的限制,也解除了维持映射关系的本地文件可靠性而至少双副本的条件;
- v21.4版本引入的S3 zero copy replication,使得多个副本间可以共享一份远端数据,显著的降低了存算一体引擎多副本存储的开销。
但事实上,通过验证测试可以发现当前阶段存算分离距离可以上生产还有很长路要走,比如:atomic库下的表怎么搬到对象存储上(表定义sql文件中标识唯一性的UUID和数据目录UUID的对应关系)、弹性扩缩容时候如何快速有效均衡数据(拷贝数据会极大拉长操作窗口)、修改本地磁盘文件和远端对象如何保障一致性、节点宕机如何快速恢复等等棘手的问题。
二.我们的实践
在云原生的时代,存算分离是趋势也是我们的工作方向,接下来的讨论将围绕华为公有云对象存储obs来展开。
1.引入文件语义
这里需要重点强调下华为云对象存储obs和其他竞品的最大差异化点:obs支持文件语义,支持文件和文件夹的rename操作。这点对于我们在接下来的系统设计和弹性伸缩实现上非常有价值,所以我们把obs的驱动集成进了clickhouse,然后修改了clickhouse的逻辑,这样数据在obs上长的和本地一模一样了:
Local Disk:

OBS:
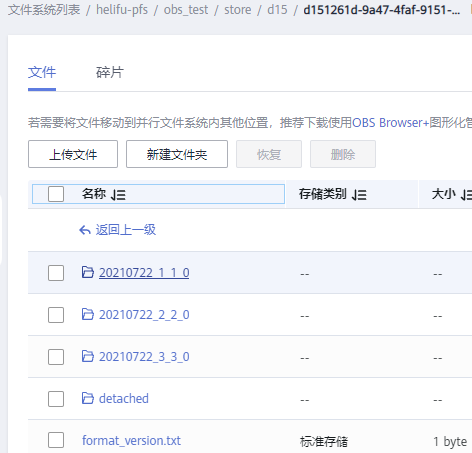
有了完整的数据目录结构后,再支持merge、detach、attach、mutate以及part回收等操作就比较方便了。
2.离线场景
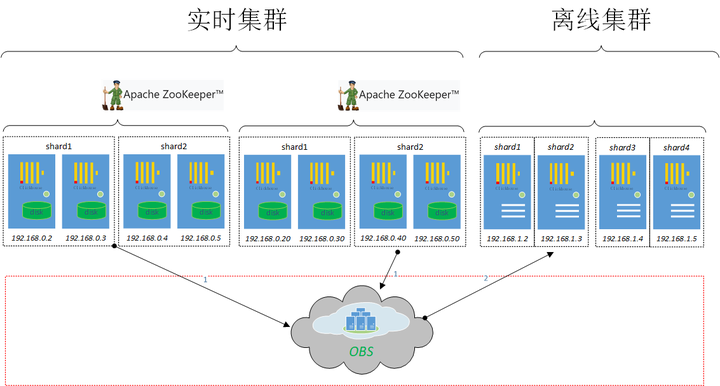
From bottom to top,我们再来看系统结构,离线加速场景中去除了对zookeeper的依赖,每个shard一个replica:

然后是扩缩容节点时候的数据均衡功能,通过obs的rename操作完成对part级别的低成本移动(和clickhouse copier工具的数据重新分发均衡不一样),节点宕机后新节点从对象存储侧构造出本地数据文件目录。
3.融合场景
ok,在上面离线场景的基础上我们继续融入实时场景(下图中的“实时集群”部分),不同业务的clickhouse集群,可以通过冷热分离分层存储的方式(这一功能相对比较成熟,业内普遍采用它来降低存储成本),把冷数据从实时集群里淘汰出来,再通过obs rename操作挂载到“离线集群”中,这样我们可以覆盖数据从实时到离线的完整的生命周期(包括从hive到clickhouse的ETL过程):
三.未来的展望
前面的实践是我们在存算分离方向的第一次尝试,还在不断的改进优化中,从宏观的角度来看仍旧是把obs作为拉远了的磁盘来使用,不过感谢obs的高吞吐,相同计算资源的前提下SSD和obs跑Star Schema Benchmark的性能延迟在5x左右,但是存储成本得到了显著的降低10x。未来,我们会在前面工作的基础上,去除obs作为拉远磁盘的属性,把单个表的数据统一在一个数据目录下,收编clickhouse的元数据,把它做成无状态的计算节点,达到sql on hadoop的效果,类似impala一样的MPP数据库。