摘要:本文收纳了Python学习者经常使用的库和包,并介绍了Python使用中热门的问题。
01、Python 简介
什么是 Python
- 一种面向对象的高级动态可解释型脚本语言。
- Python 解释器一次读取一行代码,将其解释为低级机器语言 (如字节代码) 并执行它。
- 因此这种语言经常会引发运行错误。
为什么选择 Python (优势)
- Python 是当前最流行的语言,因为它更容易编码且具有很强的可解释性。
- Python 是一种面向对象的编程语言,也可用于编写一些功能代码。
- Python 是能够很好地弥补业务和开发人员之间差距。
- 与其他语言 (如 C#/Java) 相比,Python 程序被推向市场的时间更短。
- Python 自带大量的机器学习和分析包。
- 大量社区和书籍可用于支持 Python 开发人员。
- 从预测分析到UI,几乎所有类型的应用程序都可以用 Python 实现。
- Python 程序无需声明变量类型。 因此,所构建的应用程序能有更快的运行速度。
为什么不选择 Python (劣势)
- 与其他语言 (C++,C#,Java) 相比,Python 程序的运行更慢,这是因为Python 中缺少类似 Just In Time 优化器的支持。
- Python 语法空白约束给新手编码实现带来一些困难。
- Python 不像 R 语言那样提供高级的统计功能。
- Python 不适合进行低级系统和硬件交互。
Python 是如何工作
下图展示了 Python 在机器上的运行机制。这里的关键是解释器,它是负责将高级的 Python 语言编译成低级的机器语言,以便理解。
02、变量——目标类型及范围
- 可在程序中使用的变量存储信息,如保存用户输入,程序的本地状态等。
- Python 中的变量以名字命名。
Python 中变量类型包括数字,字符串,集合,列表,元组和字典,这些都是标准的数据类型。
声明并给变量赋值
如下所示:这里首先分别为变量 myFirstVariable 分配整型数值1,字符串“Hello You”。由于 Python 中的数据类型是动态变化的,因此这种重复赋值操作是可以实现的。

Python 中变量赋值操作又称为绑定 (blinding)。
数值型
如下所示,Python 支持整型,小数,浮点型数据。

此外,也能支持长整型,以 L 为后缀表示,如999999999999L。
字符串
字符串就是字母的序列表示文本信息。
字符串的值用引号括起来,如下所示。

字符串是不可改变的,一旦创建,就不能被修改。如下所示:

当字符串变量被赋予一个新值时,Python 将创建一个新的目标来存储这个变量值。
局部变量和全局变量
局部变量
局部变量,如在一个函数内声明一个变量,则该变量只存在于该函数中。
局部变量在外部是不能被访问的,如下所示。

Python 中 if-else 和 for/while 循环模块是不能创建局部变量,如下所示在 for/while 循环中:
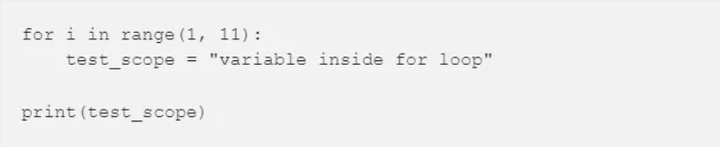
输出为:

在 if-else 模块中:

输出为

全部变量
- 全局变量可以通过任意一个全局函数访问,它们存在于 __main__ 框架中。
- 此外,在函数之外你也可以声明一个全局变量。值得注意得是,当需要为一个全局变量分配新值时,必须使用“global”关键字,如下所示:

当移除“Global TestMode”只能在 some_function() 函数中将变量设置为 False。如果你想在多个模块间共享一个全局变量,那么你需要创建一个共享模块文件。如 configuration.py,并在文件中找到你所需的变量。最后导入共享模块。
查看变量类型
- 通过 type() 函数来查看变脸类型,如下所示。

整型变量中的逗号
- 逗号可视为是变量序列,如下所示。

03、操作
数值操作
Python 支持基础的加减乘除数值计算,也支持地板除法 (floor division),如下所示。

此外,Python 还支持指数运算 (**),如下所示。
同时,Python 还能进行除法取余操作,如下所示。

字符串操作
字符串拼接

字符串复制

字符串切片

字符串反序

负索引
如果你想得到字符串的最后一个字符,那需要使用负索引值,如下所示。

查看索引值

正则表达式
- split():通过正则表达式将一个字符串分割得到一个列表。
- sub():通过正则表达式取代所要匹配的字符。
- subn():通过正则表达式取代所要匹配的字符并返回所替代字符的个数。
Casting
- str(x):将变量 x 转为字符串类型
- int(x):将变量 x 转为整型
- float(x):将变量 x 转为浮点型
集合操作
- 集合是一种无序的数据集合,定义一个集合变量,如下所示。

集合交集
- 获取两个集合的公共部分,如下所示。
集合差异
- 获取两个集合之间的不同部分,如下所示。

集合并集
- 获取两个集合的并集,如下所示。

三元运算符
- 用于在一行编写条件语句,语法结构为 [If True] if [Expression] Else [If False],如下所示。

04、注释
单行注释

多行注释

05、表达式
可用于布尔运算,如:
- Equality:==
- Not Equality:!=
- Greater:>
- Less:<
- Greater or Equal:>=
- Less or Equal:<=
06、Pickling
将对象转换为字符串并将字符串转储为一个文件的过程称为 pickling,反之则称为 unpickling。
07、函数
- 函数是一种可以在代码中执行的语句序列。如果在你的代码中出现重复的语句,那么可以创建一个可重用的函数并在程序中使用它。
- 函数也可以引用其他函数。
- 函数消除了代码中的重复,这使得代码调试和问题查找变得更容易。
- 函数使得代码更易于理解且易于管理。
- 函数允许将一个大型的应用程序拆分为一些小的模块。
定义一个新的函数

调用一个函数

查看字符串的长度
可以调用函数 len(x),如下所示。

参数
参数可以被添加到一个函数中,使得函数更通用。
通过参数,可以将一个变量传递给方法,如下所示。

可选参数
为参数提供一个默认值来传递一个可选参数,如下所示。

* 参数
如果想让函数使用任意数量的参数,那么需要在参数名前添加 *,如下所示。

** 参数
** 允许传递可变数量的关键字参数给函数,同时也可以传递一个字典值作为关键字参数。
Return
函数能够返回一个值,如下所示。

如果一个函数需要返回多个值的话,那么最好返回一个元组 (以逗号隔开每个值),如下所示。

Lambda 函数
- 是一种单行表达式的匿名函数
- 是一种内联函数
- Lambda 函数没有声明,只是通过一个表达式来实现,如下所示。

函数的语法结构为:variable = lambda arguments: expression
Lambda 函数也可以作为参数传递给其他的函数。
dir() 和 help()
- dir() 用于显示定义的符号
- help() 用于显示帮助文档
08、模块
什么是模块
- Python 语言附带了200多个标准模块。
- 模块是一种将 python 程序中相似功能进行分组的组件。
- 任何 python 代码文件都可以打包为模块,然后再导入。
- 模块允许使用者在自己的代码解决方案中进行组件化设计。
- 模块提供了命名空间的概念,帮助使用者共享数据和服务。
- 模块鼓励代码重用,并减少变量名称冲突。
PYTHONPATH
- 这是 python 的环境变量,表示用于操作模块的 python 解释器所在的位置。PYTHONHOME 是一个用于搜索该路径的模块。
如何导入模块
如果你有一个文件:MyFirstPythonFile 包含很多个函数,变量和对象,然后你可以将这些功能导入到其他类中,如下所示。

Python 内部会将模块文件编译为二进制再运行模块的代码
如果想导入模块中的所有对象,可以这样:

如果模块中包含的函数或对象命名为 my_object,那么你可以将其打印出来,如下所示。

值得注意的是,如果你不想在加载时执行模块的话,那么你需要检查是否有 __name__ == ‘__main__’
From 导入模块
如果你只是想访问模块中的一个对象或某个部分,可以这样:

这种方式导入模块允许使用者在访问模块中的对象,而无需引用模块,如下所示。

可以通过 from * 来导入模块中的所有对象,如下所示。

值得注意的是,模块只能在第一次 import 时导入。如果你想使用 C 模块,那么你可以使用 PyImport_ImportModule。此外,如果你想在两个不同模块中使用定义相同的对象,那么可以将 import 和 from 结合起来导入模块。
09、包 (Packages)
Python 中包是模块的目录。
如果你的 Python 代码中提供了大量功能,这些功能被分组到模块文件中,那么可以从模块中创建一个包,以便更好地分配和管理这些模块。
包能够更好地管理和组织模块,这有助于使用者更轻松地解决问题和查找模块。
可以将第三方软件包导入到代码中,如 pandas/scikit learn 和 tensorflow等等。
包可以包含大量的模块。
如果代码中的某些部分提供相似的功能,那么可以将模块分组到一个包中,如下所示。

上图中 packageroot 是一个根目录 (root folder),packagefolder 是其根目录下面的一个子目录,而 my_module 是在 packagefolder 目录下的一个 python 模块文件。
此外,文件夹名可以作为命名空间,如下所示。

值得注意的是,需要确保所导入的包中每个目录都包含一个 __init__.py 文件。
PIP
- PIP 是 python 的包管理器。
- 可以使用 PIP 来下载包,如下所示。

10、条件语句
条件语句 if else,如下所示。

请注意冒号和缩进在条件语句中的使用。
检查类型

你也可以在 else 部分继续添加条件逻辑语句,这样构成嵌套条件结构,如下所示。

11、循环
While
While 语句提供一个条件,运行循环语句直到满足该条件位置,循环终止,如下所示。

For
循环一定的次数,如下所示。

循环遍历整个字符串的所有字符,如下所示。

单行 for 循环
语法结构为 [Variable] AggregateFunction ([Value] for [item] in [collection])
Yielding
- 假定你的列表中包含一万亿条数据,需要从列表中计算偶数的数量。这时候将整个列表加载到内存中并不是最佳的做法,你可以通过列表来生成每个项。
- 使用 xrange 的循环结构
结合条件 if 的 for 循环
通过带 if 的 for 循环来查找两个单词中的字母,如下所示。

Break
如果你想终止循环,可以这样:

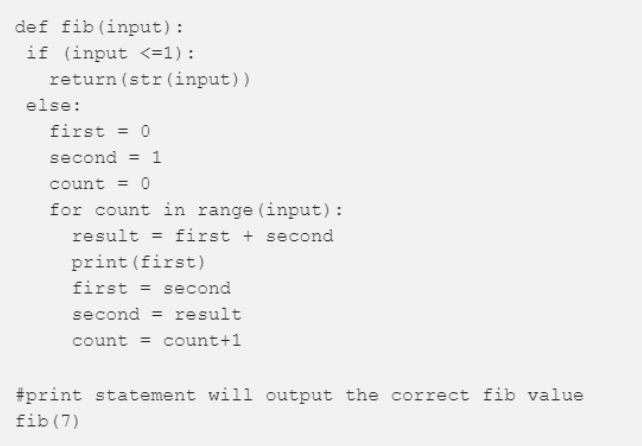
使用 Fibonacci 函数的循环结构,如下所示。
12、递归
函数调用自身的过程称为递归。
下面来演示一个阶乘递归函数:
创建一个阶乘函数,输入为 n
如果输入 n=0,则0! = 1
如果输入 n != 0,则n! = n(n-1)!

此外,Fibonacci 递归函数的流程如下所示:
创建一个 Fibonacci 递归函数,输入为 n
创建前两个变量,并为其分别赋值0和1
如果输入 n = 0,则返回0;如果输入 n =1,则返回1;否则,返回 (n-1)+(n-2)

值得注意的是,递归结构需要有一个退出检查,否则函数将进行无限循环。
13、框架 Frames 和栈 Stack 调用
Python 代码被加载到堆栈中的框架。
函数及其参数和变量一起被加载到框架中。
框架以正确的执行顺序被加载到堆栈中。
堆栈描述了函数的执行。在函数外声明的变量被存储在 __main__ 中。
堆栈首先执行最后一个框架。
如果遇到运行错误,可以使用回溯 (traceback) 来查找函数列表。
14、集合 Collections
列表 Lists
列表是一种能够包含任何数据类型的序列数据结构,这种结构是可变的。
列表可以进行整数索引,可以使用中括号来创建一个列表,如下所示。

使用索引值来添加、更新、删除列表中的项,如下所示。

此外,复制和切片同样适用于列表 (可类比字符串中的操作), 列表还支持排序操作,如下所示。

元组 Tuples
在某种程度上元组和列表类似,都是可以存储任意对象序列的数据结构。
元组的运行比列表更快速。
元组可以进行整数索引
元组是不可变的,如下所示。

值得注意的是,如果一个元组中的元素包含一个列表,那么可以对列表进行修改。同样,当为一个对象赋值并将该对象存储到列表中,随后如果对象发生变化的话,相应地,列表中的对象也会进行更新。
字典 Dictionaries
字典是编程语言中最重要的一种数据结构之一,它能够存储键值对 (key/value) 对象。
字典有许多优点,能够轻松地进行数据检索,如下所示。
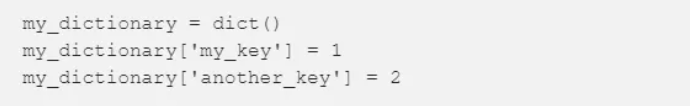
可以通过如下方式创建一个字典。

打印字典中的内容,如下所示。

字典中的值可以是任意类型的数据,包括字符串,数值,布尔型,列表甚至是字典,如下所示。

值得注意的是,如果你想对一个列表进行向量或矩阵操作,可以调用 Numpy 包来实现。
15、编译 (Compilation) 与关联 (Linking)
- 这些特征可用于一些以其他语言编写的文件,例如 C 或 C++ 等。
- 一旦将代码写入文件后,可以将文件放在 Modules 目录中。
- 在 Setup.local 文件中添加一行是非常重要的,这能确保新创建的文件能够被加载。
编译 Compilation
允许无任何错误地进行新扩展的编译过程。
关联 Linking
一旦新的扩展编译完成,他们之间就会被关联。
16、迭代器 Iterators
Iterators
- 允许遍历一个集合
- 所有迭代器都包含 __iter __() 和 __next __() 函数
- 只需在列表,字典,字符串或集合上执行 iter(x) 即可
- 可以执行实例 next(iter),这里 iter = iter(list)
- 如果集合中元素项的数目非常大且无法一次加载内存中的所有文件,此时迭代器很有用
- 有一些通用的迭代器使开发人员能够实现函数式编程,如下:
Filter
- 根据条件过滤掉相应的值
Map
- 对集合中的每个值进行计算,即将值进行映射,如将文本转为整型数值。
Reduce
- 减少集合中的值,即得到一个更小的集合。如集合求和,它本质上是可迭代的。
Zip
- 获取多个集合并返回一个新集合
- 新集合的每个项,包含每个输入集合中的元素
- Zip 允许同时对多个集合进行横向操作,如下所示。

17、面向对象设计——类 Classes
- Python 允许创建自定义类型,将这些用户自定义的类型称为类。这些类具有自定义属性和功能。
- 面向对象的设计允许程序员根据自身所需的属性和功能自定义创建对象。
- 属性也可以引用另一个对象。
- Python 中的类可以引用其他类。
- Python 支持封装 -- 实例函数和变量。
- Python 支持继承,如下所示。

- 类的一个实例称为对象。对象具有可变性,一旦创建对象,相应的属性也将被更新。
__init__
- __init__ 函数在所有类中都存在。当需要进行类实例化时,该函数就将被执行。__init__ 函数可以根据需要设置相应的属性,如下所示。

值得注意的是,self 参数将包含对象的引用,这与 C# 语言中的 this 参数类似。
__str__
当调用 print 时,返回一个对象的字符串结果,如下所示。

因此,当执行 print 语句时,__str__ 将会被执行。
__cmp__
如果想要提供自定义逻辑来比较同一实例的两个对象,可以使用__cmp__ 实例函数。
__cmp__ 函数返回1 (更大), - 1 (更低) 和0 (相等),以指示两个对象的大小。
可以将 __cmp__ 想象成其他编程语言中的 Equals() 方法。
Overloading
通过将更多参数作为实例,来重载一个对象。
还可以通过为 __add__ 来实现想要的运算符,如 +。
对象的浅拷贝 (Shallow Copy) 和深拷贝 (Deep Copy)
等效对象 – 包含相同的值
相同对象 – 引用相同的对象 – 内存中指向相同的地址
如果要复制整个对象,可以使用复制模块 (copy module),如下所示。

这将导致浅拷贝,因为属性的引用指针将会被复制。
如果对象的一个属性是对象引用,那么它将简单地指向与原始对象相同的引用地址。
更新源对象中的属性将导致目标对象中的属性也会更新。
浅拷贝是复制引用指针。
这种情况下可以利用深拷贝,如下所示。

如果 MyClass 包含引用 MyOtherClass 对象的属性,则属性的内容将通过 deepcopy 复制到新创建的对象中。
深拷贝将对对象进行新的引用。
18、面向对象设计——继承
Python支持对象的继承,即对象可以继承其父类的功能和属性。
继承的类可以在其函数中包含不同的逻辑。
如果一个父类 ParentClass 有两个子类 SubClass1 和 SubClass2,那么你可以使用Python来创建类,如下所示。

上例中两个子类都将包含 my_function() 函数
类的继承属性鼓励代码的重用性和可维护性。
此外,python 中支持多类继承,这与 C# 语言不同。
多类继承 multi-Inheritance

如果你想调用父类函数,可以这样:

19、垃圾收集——内存管理
Python 中的所有对象都存储在一个堆积空间 (heap space),而 Python 解释器可以访问此空间。
Python 有一个内置的垃圾收集机制。
这意味着 Python 可以自动为程序进行分配和取消内存,这与 C++ 或 C# 等其他语言类似。
垃圾收集机制主要是清除程序中未引用/使用的那些对象的内存空间。
由于多个对象可以共享内存引用,因此 python 使用两种机制:
- 引用计数:计算引用对象的数目。如果对象的计数为0,则取消对象的空间分配。
- 循环引用:这种机制关注的是循环引用:当取消分配 (deallocation) 的数目大于阈值时,仅取消对象所在的内存空间分配。
在 Python 中新创建的对象,可以通过如下方式进行检查:

此外,也可以通过及时或者基于事件机制来进行手动的垃圾收集。
20、 I/O
From Keyboard
使用 raw_input() 函数,如下所示。

文件 Files
使用with/as语句来打开并读取文件,这与 C# 中读取文件的操作一致。
此外,with 语句还可以处理关闭连接和其他清理操作。
打开一个文件,如下所示。
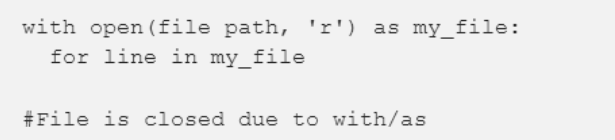
需要注意的是,readline() 可用于读取文件中的每一行。
打开两个文件,如下所示。

文件写入,如下所示。

Python 中对文件的操作通常涉及 os 和 shutil 模块。rw 表示读写模式,a代表可添加模式。
SQL
打开一个连接,如下所示。

执行一个 SQL 声明,如下所示。

网络服务 (Web Services)
查询一个闲置服务,如下所示:

序列化和反序列化 JSON 文件
反序列化 JSON,如下所示:

序列化 JSON,如下所示:

21、异常处理
抛出异常
如果你想抛出异常,那么可以使用 raise 关键字,如下所示。

捕获异常
可以通过如下方式捕获异常信息:

如果想捕获特定的异常,可以这样:

如果想使用 try/catch/finally 结构捕获异常信息,可以这样:

值得注意的是,无论 finally 部分的代码是否触发,你都可以使用 finally 来关闭数据库/文件的连接。
Try/Except/Else

如果想为异常信息分配一个变量,可以这样:

如果想定义用于自定义的限制,可以通过 assert 关键字实现,如下所示:

值得注意的是,python 中的异常同样具有继承性。
此外,你也可以创建自己的异常类,如下所示:
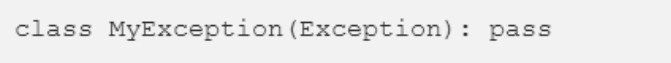
22、多线程和 GIL
- GIL 表示 Global Interpreter Lock。
- GIL 确保线程可以在任何时间执行,并允许 CPU 选择要执行的所需线程。
- GIL 能够传递当前正在执行的线程。
- Python 支持多线程。
此外,GIL 会增加代码执行的计算开销。因此,运行多线程时需谨慎。
23、装饰器 Decorators
- 装饰器可以为代码添加功能,其本质上是一种调用其他对象/函数的函数。 它是可调用函数,因此在调用装饰器函数时将返回随后需要调用的对象。
- 通过封装包/装一个类/函数,然后在调用函数时执行特定的代码。
- 此外,还可以通过实现通用逻辑来记录,进行安全检查等,然后使用 property 标记方法的属性。
24、Python 中的单元测试
Python 中有许多单元测试和模拟库
下面以 unittest 为例
假定你的函数每次将输入值减少1,如下所示:

可以通过如下方式来进行单元测试:

同样地,也可以使用 doctest 来测试 docstrings 中所编写的代码。
25、一些与 Python 有关的热门话题
为什么要使用 Python
- 编码简单,易于学习
- 面向对象编程语言
- 强大的分析功能和机器学习包
- 更快速地开发并将解决方案推向市场
- 提供内置的内存管理功能
- 提供巨大的社区支持和应用程序
- 无需编译,因为它本身是一种可解释的语言
- 动态输入,即无需声明变量
如何让 Python 运行得更快
- Python 是一种高级语言,不适合在系统程序或硬件层面访问。
- Python 不适用于跨平台的应用程序。
- Python 是一种动态类型的解释语言。与低级语言相比,它的优化和运行速度较慢。
- 实现基于 C 语言的扩展。
- 可以使用 Spark 或 Hadoop 创建多进程
- 可以利用 Cython,Numba 和 PyPy 来加速 Python 代码或用 C 语言编写它并在 Python 中公开。
Python 爱好者都是用哪些 IDEs?
- 包括 Spyder,Pycharm 等。此外,还会使用各种的 notebooks,如 Jupyter。
Python 中热门的框架和包有哪些
- Python 中必须掌握的包有很多,包括 PyUnit (单元测试), PyDoc (文档), SciPy (代数和数值计算), Pandas (数据管理), Sci-Kit learn (机器学习和数据科学), Tensorflow (人工智能), Numpy (数组和数值计算), BeautifulSoap (网页爬取), Flask (微服务框架), Pyramid (企业应用), Django (UI MVVM), urllib (网页爬取), Tkinter (GUI), mock (模拟库), PyChecker (bug 检测器), Pylint (模块代码分析) 等。
如何托管 Python 包
对于 Unix 系统:制作脚本文件,模式为可执行且文件第一行必须是:

可以使用命令行工具并执行它。也可以通过 PyPRI 和 PyPI 服务。
Python 和 R 语言能合并吗
R 语言中有着大量丰富的统计库,可以使用 Rpy2 python 包或在 Juputer 中使用 beaker 笔记本或 IR 内核,在 Python 中执行 R 代码。
在运行 Python 前有没有办法能够捕获异常?
在运行代码之前,可以使用 PyChecker 和 PyLink 来捕获异常信息。
总结
本文概述了 Python 最重要的25个概念,这些知识对初学者来说足以编写自己的 Python 包或使用现有的 Python 包,希望能帮助大家更好地学习 Python。
本文分享自华为云社区《Python从入门到精通25个关键技术点》,原文作者:简单坚持。