例子实战之训练模型
在处理好数据之后我们就可以训练模型了,以多元逻辑回归为例
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
ss = ShuffleSplit(n_splits = 1,test_size= 0.2) # 按比例拆分数据,80%用作训练
for tr,te in ss.split(data,label):
xr = data[tr]
xe = data[te]
yr = label[tr]
ye = label[te]
clf = LogisticRegression(solver = 'lbfgs',multi_class = 'multinomial')
clf.fit(xr,yr)
predict = clf.predict(xe)
print(classification_report(ye, predict)) 
这里我们的逻辑回归使用OVR多分类方法,
OvR把多元逻辑回归,看做二元逻辑回归。具体做法是,每次选择一类为正例,其余类别为负例,然后做二元逻辑回归,得到第该类的分类模型。最后得出多个二元回归模型。按照各个类别的得分得出分类结果。
模型选择
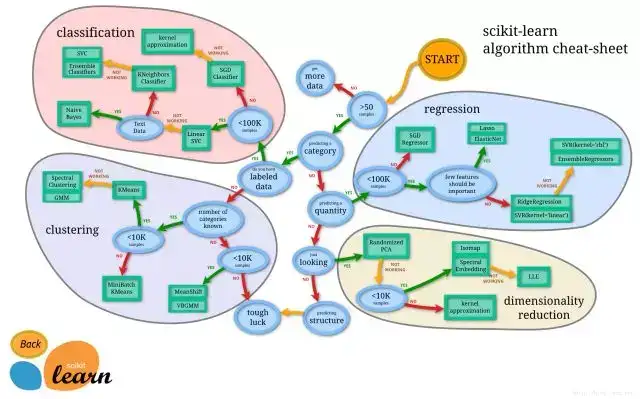
对于一个分类任务,我们可以按照以上的图来选择一个比较合适的解决方法或者模型,但模型的选择并不是绝对的,事实上很多情况下你会去试验很多的模型,才能比较出适合该问题的模型。
转自https://zhuanlan.zhihu.com/p/33420189