一:快照模式
默认redis是会以快照的形式将数据持久化到磁盘的(一个二进制文件,dump.rdb,这个文件名字可以指定),在配置文件中的格式是:save N M表示在N秒之内,redis至少发生M次修改则redis抓快照到磁盘。当然我们也可以手动执行save或者bgsave(异步)做快照。
工作原理简单介绍一下:当redis需要做持久化时,redis会fork一个子进程;子进程将数据写到磁盘上一个临时RDB文件中;当子进程完成写临时文件后,将原来的RDB替换掉,这样的好处就是可以copy-on-write
如下图:
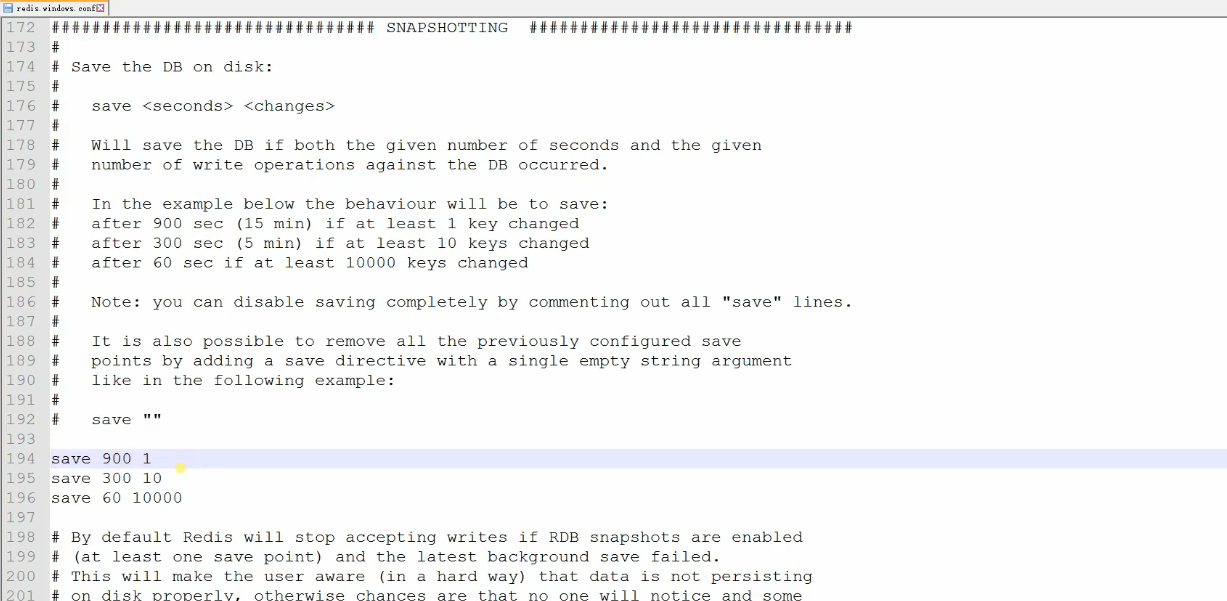
上面三组命令也是非常好理解的,就是说900指的是“秒数”,1指的是“change次数”,接下来如果在“900s“内至少有1次更改,那么就执行save保存,同样
的道理,如果300s内至少有10次change,60s内至少有1w次change,那么也会执行save操作。
以上是redis自身进行的同步操作。
下面是我们可以以手工执行save
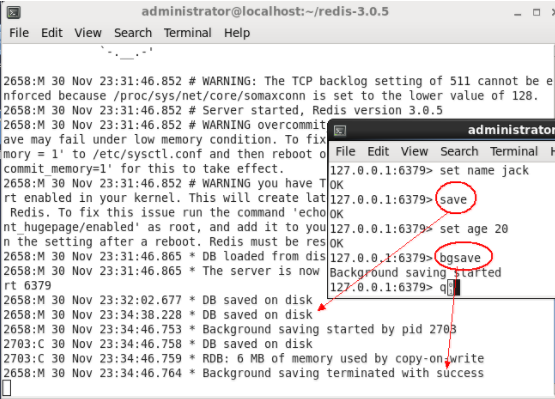
redis提供了两个操作命令:save,bgsave,这两个命令都会强制将数据刷新到硬盘中,如下图:
RDB 的优点:
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。
这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。
RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点:
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。
因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。
在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。
虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
二:AOF(Append-only file)
filesnapshotting方法在redis异常死掉时,最近的数据会丢失(丢失数据的多少视你save策略的配置),所以这是它最大的缺点,当业务量很大时,丢失的数据是很多的。Append-only方法可以做到全部数据不丢失,
但redis的性能就要差些。AOF就可以做到全程持久化,只需要在配置文件中开启(默认是no),appendonly yes开启AOF之后,redis每执行一个修改数据的命令,都会把它添加到aof文件中,当redis重启时,将会读取AOF文件进行“重放”以恢复到redis关闭前的最后时刻。
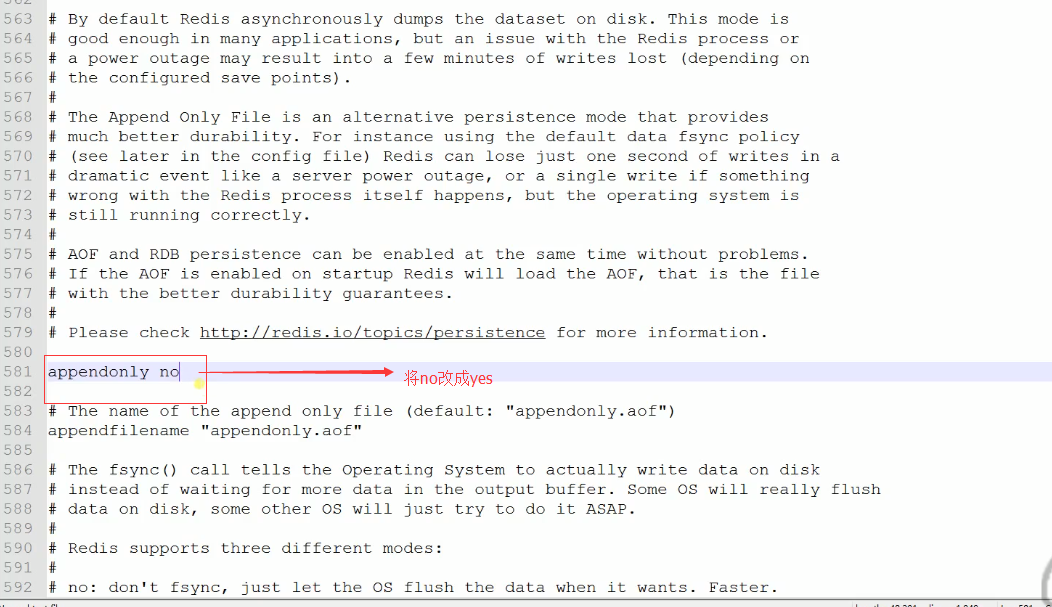

AOF文件刷新的方式,有三种,参考配置参数appendfsync :
appendfsync always每提交一个修改命令都调用fsync刷新到AOF文件,非常非常慢,但也非常安全;
appendfsync everysec每秒钟都调用fsync刷新到AOF文件,很快,但可能会丢失一秒以内的数据;
appendfsync no依靠OS进行刷新,redis不主动刷新AOF,这样最快,但安全性就差。默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾。
AOF 的优点:
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。
AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。
AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。
整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。
导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。
不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。
(举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。
虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
可能由于系统原因导致了AOF损坏,redis无法再加载这个AOF,可以按照下面步骤来修复:首先做一个AOF文件的备份,复制到其他地方;修复原始AOF文件,执行:$ redis-check-aof –fix ;可以通过diff –u命令来查看修复前后文件不一致的地方;重启redis服务。
LOG Rewrite的工作原理:同样用到了copy-on-write:首先redis会fork一个子进程;子进程将最新的AOF写入一个临时文件;父进程增量的把内存中的最新执行的修改写入(这时仍写入旧的AOF,rewrite如果失败也是安全的);当子进程完成rewrite临时文件后,父进程会收到一个信号,并把之前内存中增量的修改写入临时文件末尾;这时redis将旧AOF文件重命名,临时文件重命名,开始向新的AOF中写入。
最后,为以防万一(机器坏掉或磁盘坏掉),记得定期把使用 filesnapshotting 或 Append-only 生成的*rdb *.aof文件备份到远程机器上。我是用crontab每半小时SCP一次。我没有使用redis的主从功能 ,因为半小时备份一次应该是可以了,而且我觉得有如果做主从有点浪费机器。这个最终还是看应用来定了。
《Redis官方文档》使用Redis作为LRU缓存
如果你使用redis作为缓存,当添加新数据时,若有内存大小等限制,系统默认会根据一定的规则自动清理旧数据。这种处理方式在开发社区中众所周知,因为它也是非常流行的缓存系统 memcached 的默认处理方式。
LRU(LRU全称是Least Recently Used,即最近最久未使用)实际上只是Redis支持的内存回收策略中的一种,
Redis的 maxmemory 配置选项,该配置选项用来限制 Redis 的内存使用大小,同时深入研究 LRU(确切的说是近似LRU算法) 算法在 Redis 中的应用。
最大内存配置选项
maxmemory 配置选项使用来配置 Redis 的存储数据所能使用的最大内存限制。可以通过在内置文件redis.conf中配置,也可在Redis运行时通过命令CONFIG SET来配置。例如,我们要配置内存上限是100M的Redis缓存,那么我们可以在 redis.conf 配置如下:
maxmemory 100mb
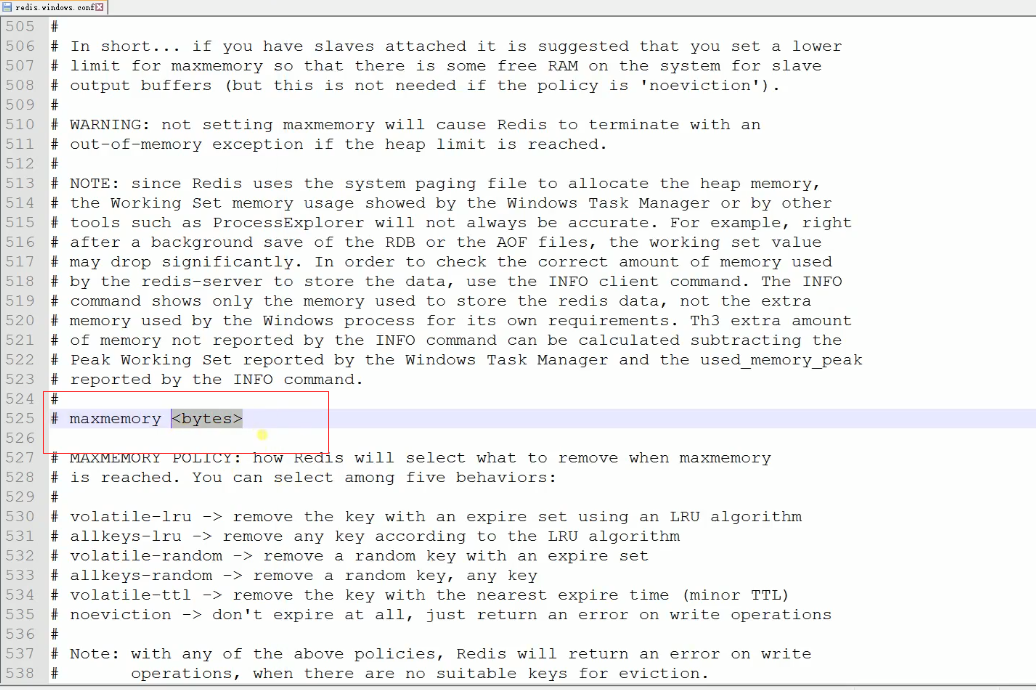
设置 maxmemory 为 0 表示没有内存限制。在 64-bit 系统中,默认是 0 无限制,但是在 32-bit 系统中默认是 3GB。
当存储数据达到限制时,Redis 会根据情形选择不同策略,或者返回errors(这样会导致浪费更多的内存),或者清除一些旧数据回收内存来添加新数据
回收策略
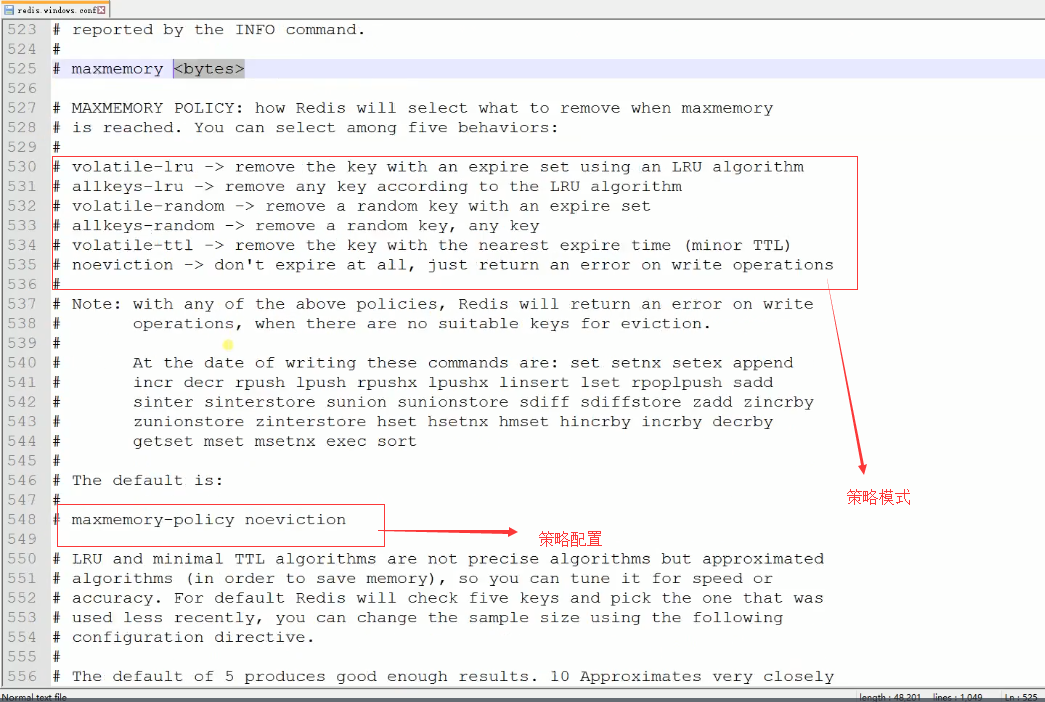
当内存达到限制时,Redis 具体的回收策略是通过 maxmemory-policy 配置项配置的。
以下的策略都是可用的:
- noenviction:不清除数据,只是返回错误,这样会导致浪费掉更多的内存,对大多数写命令(DEL 命令和其他的少数命令例外)
- allkeys-lru:从所有的数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰,以供新数据使用
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰,以供新数据使用
- allkeys-random:从所有数据集(server.db[i].dict)中任意选择数据淘汰,以供新数据使用
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰,以供新数据使用
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰,以供新数据使用
当 cache 中没有符合清除条件的 key 时,回收策略 volatile-lru, volatile-random 和volatile-ttl 将会和 策略 noeviction 一样返回错误。选择正确的回收策略是很重要的,取决于你的应用程序的访问模式。但是,你可以在程序运行时重新配置策略,使用 INFO 输出来监控缓存命中和错过的次数,以调优你的设置。
普适经验规则:
- 如果期望用户请求呈现幂律分布(power-law distribution),也就是,期望一部分子集元素被访问得远比其他元素多时,可以使用allkeys-lru策略。在你不确定时这是一个好的选择。
- 如果期望是循环周期的访问,所有的键被连续扫描,或者期望请求符合平均分布(每个元素以相同的概率被访问),可以使用allkeys-random策略。
- 如果你期望能让 Redis 通过使用你创建缓存对象的时候设置的TTL值,确定哪些对象应该是较好的清除候选项,可以使用volatile-ttl策略。
当你想使用单个Redis实例来实现缓存和持久化一些键,allkeys-lru和volatile-random策略会很有用。但是,通常最好是运行两个Redis实例来解决这个问题。
另外值得注意的是,为键设置过期时间需要消耗内存,所以使用像allkeys-lru这样的策略会更高效,因为在内存压力下没有必要为键的回收设置过期时间。
回收过程
理解回收过程是运作流程非常的重要,回收过程如下:
- 一个客户端运行一个新命令,添加了新数据。
- Redis检查内存使用情况,如果大于maxmemory限制,根据策略来回收键。
- 一个新的命令被执行,如此等等。
我们添加数据时通过检查,然后回收键以返回到限制以下,来连续不断的穿越内存限制的边界。
如果一个命令导致大量的内存被占用(比如一个很大的集合保存到一个新的键),那么内存限制很快就会被这个明显的内存量所超越。
近似LRU算法
Redis的LRU算法不是一个严格的LRU实现。这意味着Redis不能选择最佳候选键来回收,也就是最久未被访问的那些键。相反,Redis 会尝试执行一个近似的LRU算法,通过采样一小部分键,然后在采样键中回收最适合(拥有最久访问时间)的那个。
然而,从Redis3.0开始,算法被改进为维护一个回收候选键池。这改善了算法的性能,使得更接近于真实的LRU算法的行为。Redis的LRU算法有一点很重要,你可以调整算法的精度,通过改变每次回收时检查的采样数量。
这个参数可以通过如下配置指令:
maxmemory-samples 5
Redis没有使用真实的LRU实现的原因,是因为这会消耗更多的内存。然而,近似值对使用Redis的应用来说基本上也是等价的。下面的图形对比,为Redis使用的LRU近似值和真实LRU之间的比较。

用于测试生成了上面图像的Redis服务被填充了指定数量的键。键被从头访问到尾,所以第一个键是LRU算法的最佳候选回收键。然后,再新添加50%的键,强制一般的旧键被回收。
你可以从图中看到三种不同的原点,形成三个不同的带。
- 浅灰色带是被回收的对象
- 灰色带是没有被回收的对象
- 绿色带是被添加的对象
在理论的LRU实现中,我们期望看到的是,在旧键中第一半会过期。而Redis的LRU算法则只是概率性的过期这些旧键。 你可以看到,同样使用5个采样点,Redis 3.0表现得比Redis 2.8要好,Redis 2.8中最近被访问的对象之间的对象仍然被保留。在Redis 3.0中使用10为采样大小,近似值已经非常接近理论性能。
注意,LRU只是一个预测模型用来指定键在未来如何被访问。另外,如果你的数据访问模式非常接近幂律,大多数的访问都将集中在一个集合中,LRU近似算法将能处理得很好。
在模拟实验的过程中,我们发现使用幂律访问模式,真实的LRU算法和Redis的近似算法之间的差异非常小,或者根本就没有。然而,你可以提高采样大小到10,这会消耗额外的CPU,来更加近似于真实的LRU算法,看看这会不会使你的缓存错失率有差异。
使用CONFIG SET maxmemory-samples <count>命令在生产环境上试验各种不同的采样大小值是很简单的。