为了避免意外宕机以后丢失信息,需要做到重启后可以恢复消息队列,消息系统一般都会采用持久化机制。 ActiveMQ的消息持久化机制有JDBC,AMQ,KahaDB和LevelDB,
无论使用哪种持久化方式,消息的存储逻辑都是一致的。也就是说发送者将消息发送出去后,消息中心首先将消息存储到本地数据文件、内存数据库或者远程数据库等,然后试图将消息发送给接收者,发送成功则将消息从存储中删除,失败则继续尝试。消息中心启动以后首先要检查指定的存储位置,如果有未发送成功的消息,则需要把消息发送出去。
1.KahaDB:
1.KahaDB是从ActiveMQ 5.4开始默认的持久化插件,也是我们项目现在使用的持久化方式。
2.KahaDb恢复时间远远小于其前身AMQ并且使用更少的数据文件,所以可以完全代替AMQ。
3.kahaDB的持久化机制同样是基于日志文件,索引和缓存。
(1)KahaDB主要特性:
1、日志形式存储消息;
2、消息索引以B-Tree数据结构存储,可以快速更新;
3、完全支持JMS事务;
4、支持多种恢复机制
配置KahaDB 可以在ActiveMq.xml中配置,配置方式如下图:
<persistenceAdapter>
<kahaDB directory="${activemq.data}/activemq-data" journalMaxFileLength="16mb"/>
</persistenceAdapter>
directory : 指定持久化消息的存储目录
journalMaxFileLength : 指定保存消息的日志文件大小,具体根据你的实际应用配置
KahaDB的结构如下:
消息存储在基于文件的数据日志中。如果消息发送成功,变标记为可删除的。系统会周期性的清除或者归档日志文件。
消息文件的位置索引存储在内存中,这样能快速定位到。定期将内存中的消息索引保存到metadata store中,避免大量消息未发送时,消息索引占用过多内存空间。
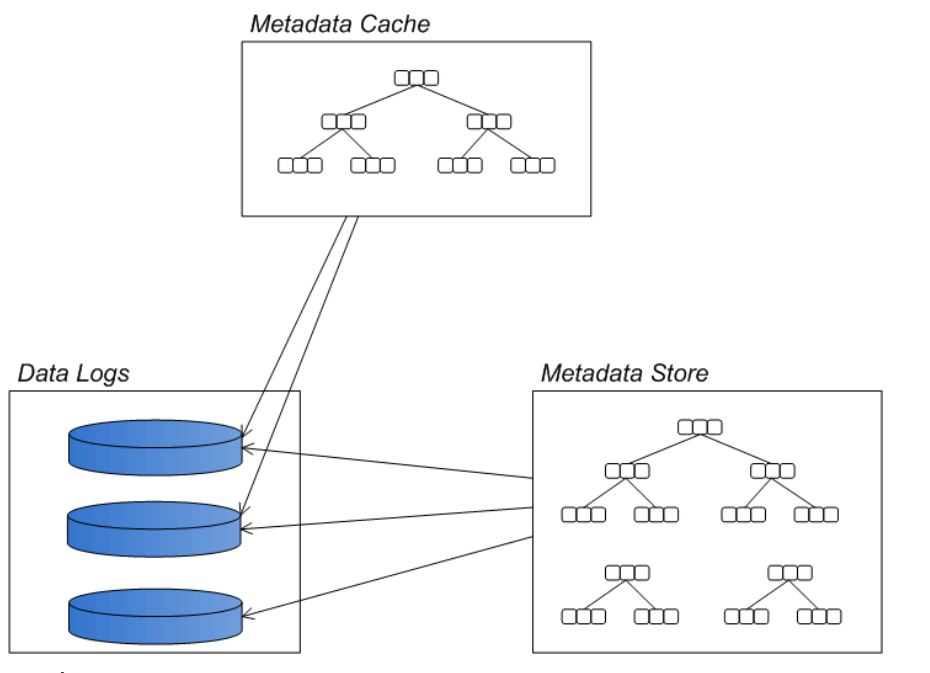
Data logs:
Data logs用于存储消息日志,消息的全部内容都在Data logs中。
同AMQ一样,一个Data logs文件大小超过规定的最大值,会新建一个文件。同样是文件尾部追加,写入性能很快。
每个消息在Data logs中有计数引用,所以当一个文件里所有的消息都不需要了,系统会自动删除文件或放入归档文件夹。
Metadata cache :
缓存用于存放在线消费者的消息。如果消费者已经快速的消费完成,那么这些消息就不需要再写入磁盘了,不放在磁盘,这样也就不用刷磁盘,效率大大提高。
Btree索引会根据MessageID创建索引,用于快速的查找消息。这个索引同样维护持久化订阅者与Destination的关系,以及每个消费者消费消息的指针。
Metadata store
在db.data文件中保存消息日志中消息的元数据,也是以B-Tree结构存储的,定时从Metadata cache更新数据。Metadata store中也会备份一些在消息日志中存在的信息,
这样可以让Broker实例快速启动。
即便metadata store文件被破坏或者误删除了。broker可以读取Data logs恢复过来,只是速度会相对较慢些。
注意一点:ActiveMq默认是打开持久化开关的,发送消息到达Broker后,Broker不会着急把消息发出去,而是先把这个消息持久化,即把消息存储在一个可靠的介质上面后,才会发送消息出去,并且返回ACK,如果消息没持久化成功,就算消息到达Broker后,也不会发送ACK确认给生产者。
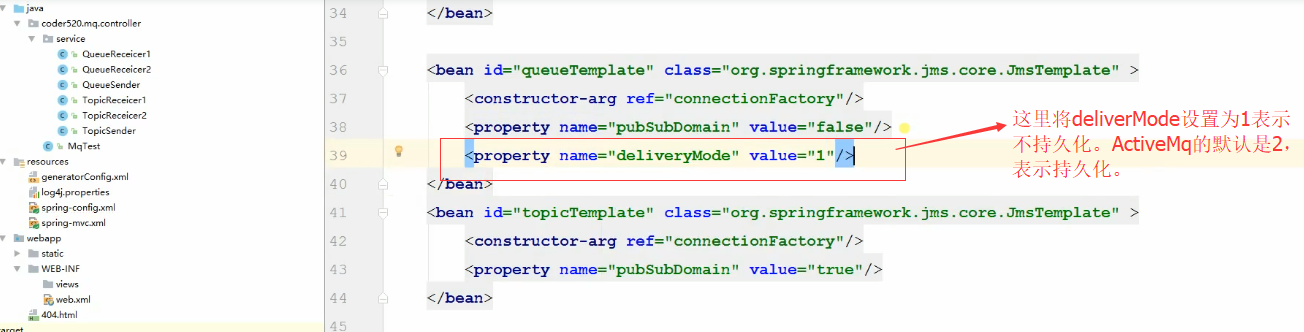
如果我们不想持久化,我们可以进行一些配置如下图:
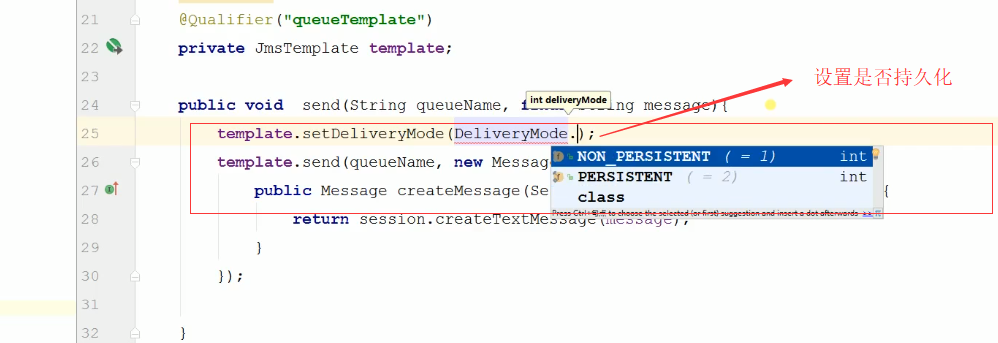
或者在代码中设置,如下图:
现在如果我们将Queue的消费者干掉,看一下AcitveMq的持久化,如下图:
再重启项目,重新发送消息:如下图:

可以看到五条消息入队,没有消息出队。
举个例子,比如有商家搞活动,比如秒杀,瞬间让消息达到峰值,突然CPU撑爆了,消息队列宕机了,当时由于我们设置的消息是持久化的,如果我们重启机器后,这些被持久化
下来的消息还在,然后从介质中把消息拿出来重新发出去。
现在我们重新把消费者配置回来,是否还有消息进队,如下图:
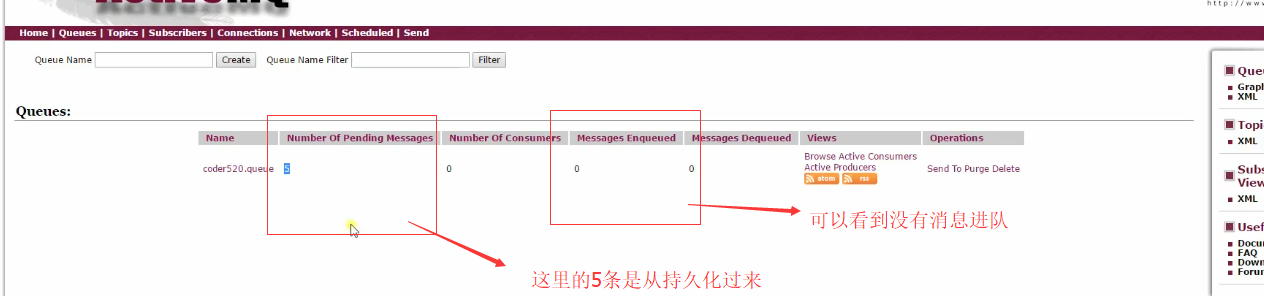
再看一下工程运行情况,如下图:

可以看到消息发出去了,并且被消费者消费了。
Topic持久化也类似,
1.Topic持久化订阅者,就是一直在线,可以随时接受消息。就好比QQ一直在线,别人发消息我随时能接收,并且看到。
Topic持久化订阅如下:

2.Topic非持久化订阅者。生产者发消息,会把消息存在Broker里面,等你上线了再把消息发过去。好比QQ处于离线状态,等我上线了,就立马接收消息。
Topic非持久化订阅如下:

2.JDBC持久化:
使用JDBC持久化方式,数据库会创建3个表:activemq_msgs,activemq_acks和activemq_lock。activemq_msgs用于存储消息,Queue和Topic都存储在这个表中。
(1)配置方式
配置持久化的方式,都是修改安装目录下conf/acticvemq.xml文件,
首先定义一个mysql-ds的MySQL数据源,然后在persistenceAdapter节点中配置jdbcPersistenceAdapter并且引用刚才定义的数据源。
如下代码配置:
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds" createTablesOnStartup="false" />
</persistenceAdapter>
dataSource指定持久化数据库的bean,createTablesOnStartup是否在启动的时候创建数据表,默认值是true,这样每次启动都会去创建数据表了,一般是第一次启动的时候设置为true,之后改成false。
使用MySQL配置JDBC持久化:
<beans>
<broker brokerName="test-broker" persistent="true" xmlns="http://activemq.apache.org/schema/core">
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds" createTablesOnStartup="false"/>
</persistenceAdapter>
</broker>
<bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/activemq?relaxAutoCommit=true"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="maxActive" value="200"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
</beans>
(2)数据库表信息
activemq_msgs用于存储消息,Queue和Topic都存储在这个表中:
ID:自增的数据库主键
CONTAINER:消息的Destination
MSGID_PROD:消息发送者客户端的主键
MSG_SEQ:是发送消息的顺序,MSGID_PROD+MSG_SEQ可以组成JMS的MessageID
EXPIRATION:消息的过期时间,存储的是从1970-01-01到现在的毫秒数
MSG:消息本体的Java序列化对象的二进制数据
PRIORITY:优先级,从0-9,数值越大优先级越高
activemq_acks用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存:
主要的数据库字段如下:
CONTAINER:消息的Destination
SUB_DEST:如果是使用Static集群,这个字段会有集群其他系统的信息
CLIENT_ID:每个订阅者都必须有一个唯一的客户端ID用以区分
SUB_NAME:订阅者名称
SELECTOR:选择器,可以选择只消费满足条件的消息。条件可以用自定义属性实现,可支持多属性AND和OR操作
LAST_ACKED_ID:记录消费过的消息的ID。
表activemq_lock在集群环境中才有用,只有一个Broker可以获得消息,称为Master Broker,
其他的只能作为备份等待Master Broker不可用,才可能成为下一个Master Broker。
这个表用于记录哪个Broker是当前的Master Broker。
3.Activemq方式:性能高于JDBC,写入消息时,会将消息写入日志文件,由于是顺序追加写,性能很高。为了提升性能,创建消息主键索引,并且提供缓存机制,进一步提升性能。每个日志文件的大小都是有限制的(默认32m,可自行配置)。
当超过这个大小,系统会重新建立一个文件。当所有的消息都消费完成,系统会删除这个文件或者归档(取决于配置)。
主要的缺点是AMQ Message会为每一个Destination创建一个索引,如果使用了大量的Queue,索引文件的大小会占用很多磁盘空间。
而且由于索引巨大,一旦Broker崩溃,重建索引的速度会非常慢。
配置如下:
<persistenceAdapter>
<amqPersistenceAdapter directory="${activemq.data}/activemq-data" maxFileLength="32mb"/>
</persistenceAdapter>
虽然AMQ性能略高于上面的Kaha DB方式,但是由于其重建索引时间过长,而且索引文件占用磁盘空间过大,所以已经不推荐使用。
4.LevelDB方式:从ActiveMQ 5.6版本之后,又推出了LevelDB的持久化引擎。
目前默认的持久化方式仍然是KahaDB,不过LevelDB持久化性能高于KahaDB,可能是以后的趋势。
在ActiveMQ 5.9版本提供了基于LevelDB和Zookeeper的数据复制方式,用于Master-slave方式的首选数据复制方案。