问题导读
1、如何理解SQL Core?
2、RDD支持的第三方格式有哪些?
3、SQLContext如何对sql执行解析?

摘要 本文作者整理了对Spark SQL各个模块的实现情况、代码结构、执行流程情况以及分享了对Spark SQL的理解,无论是从源码实现,还是从Spark SQL实际使用角度,这些都很有参考价值。
1、SQL Core
Spark SQL的核心是把已有的RDD,带上Schema信息,然后注册成类似sql里的”Table”,对其进行sql查询。这里面主要分两部分,一是生成SchemaRD,二是执行查询。
2、生成SchemaRDD
如果是spark-hive项目,那么读取metadata信息作为Schema、读取hdfs上数据的过程交给Hive完成,然后根据这俩部分生成SchemaRDD,在HiveContext下进行hql()查询。
对于Spark SQL来说,
数据方面,RDD可以来自任何已有的RDD,也可以来自支持的第三方格式,如json file、parquet file。
SQLContext下会把带case class的RDD隐式转化为SchemaRDD 
ExsitingRdd单例里会反射出case class的attributes,并把RDD的数据转化成Catalyst的GenericRow,最后返回RDD[Row],即一个SchemaRDD。这里的具体转化逻辑可以参考ExsitingRdd的productToRowRdd和convertToCatalyst方法。
之后可以进行SchemaRDD提供的注册table操作、针对Schema复写的部分RDD转化操作、DSL操作、saveAs操作等等。
Row和GenericRow是Catalyst里的行表示模型 Row用Seq[Any]来表示values,GenericRow是Row的子类,用数组表示values。Row支持数据类型包括Int, Long, Double, Float, Boolean, Short, Byte, String。支持按序数(ordinal)读取某一个列的值。读取前需要做isNullAt(i: Int)的判断。
各自都有Mutable类,提供setXXX(i: int, value: Any)修改某序数上的值。
3、层次结构

下图大致对比了Pig,Spark SQL,Shark在实现层次上的区别,仅做参考。 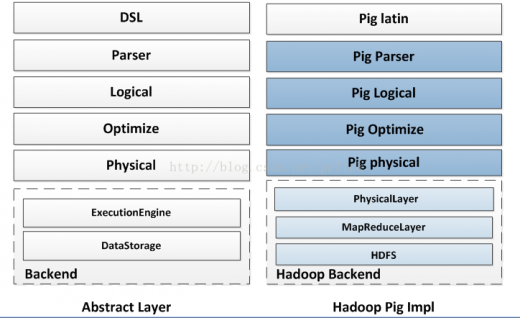
4、查询流程
SQLContext里对sql的一个解析和执行流程:
-
第一步parseSql(sql: String),simple sql parser做词法语法解析,生成LogicalPlan。
-
第二步analyzer(logicalPlan),把做完词法语法解析的执行计划进行初步分析和映射,
目前SQLContext内的Analyzer由Catalyst提供,定义如下:
new Analyzer(catalog, EmptyFunctionRegistry, caseSensitive =true)
catalog为SimpleCatalog,catalog是用来注册table和查询relation的。
而这里的FunctionRegistry不支持lookupFunction方法,所以该analyzer不支持Function注册,即UDF。
Analyzer内定义了几批规则: 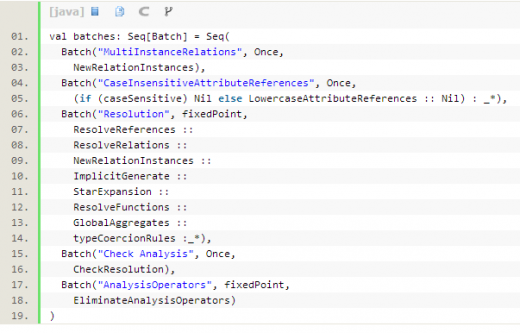
-
从第二步得到的是初步的logicalPlan,接下来第三步是optimizer(plan)。 Optimizer里面也是定义了几批规则,会按序对执行计划进行优化操作。
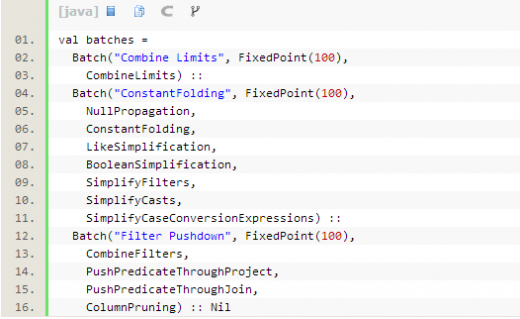
-
优化后的执行计划,还要丢给SparkPlanner处理,里面定义了一些策略,目的是根据逻辑执行计划树生成最后可以执行的物理执行计划树,即得到SparkPlan。
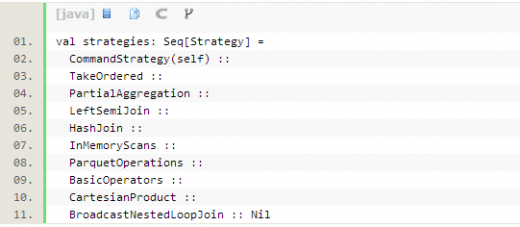
-
在最终真正执行物理执行计划前,最后还要进行两次规则,SQLContext里定义这个过程叫prepareForExecution,这个步骤是额外增加的,直接new RuleExecutor[SparkPlan]进行的。

-
最后调用SparkPlan的execute()执行计算。这个execute()在每种SparkPlan的实现里定义,一般都会递归调用children的execute()方法,所以会触发整棵Tree的计算。
5、其他特性
内存列存储 SQLContext下cache/uncache table的时候会调用列存储模块。 该模块借鉴自Shark,目的是当把表数据cache在内存的时候做行转列操作,以便压缩。
实现类 InMemoryColumnarTableScan类是SparkPlan LeafNode的实现,即是一个物理执行计划。传入一个SparkPlan(确认了的物理执行计)和一个属性序列,内部包含一个行转列、触发计算并cache的过程(且是lazy的)。
ColumnBuilder针对不同的数据类型(boolean, byte, double, float, int, long, short, string)由不同的子类把数据写到ByteBuffer里,即包装Row的每个field,生成Columns。与其对应的ColumnAccessor是访问column,将其转回Row。
CompressibleColumnBuilder和CompressibleColumnAccessor是带压缩的行列转换builder,其ByteBuffer内部存储结构如下 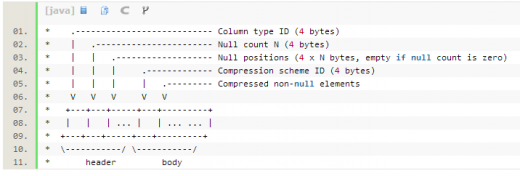
CompressionScheme子类是不同的压缩实现 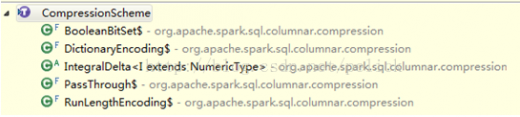 都是scala实现的,未借助第三方库。不同的实现,指定了支持的column data类型。在build()的时候,会比较每种压缩,选择压缩率最小的(若仍大于0.8就不压缩了)。
都是scala实现的,未借助第三方库。不同的实现,指定了支持的column data类型。在build()的时候,会比较每种压缩,选择压缩率最小的(若仍大于0.8就不压缩了)。
这里的估算逻辑,来自子类实现的gatherCompressibilityStats方法。
6、Cache逻辑
cache之前,需要先把本次cache的table的物理执行计划生成出来。
在cache这个过程里,InMemoryColumnarTableScan并没有触发执行,但是生成了以InMemoryColumnarTableScan为物理执行计划的SparkLogicalPlan,并存成table的plan。
其实在cache的时候,首先去catalog里寻找这个table的信息和table的执行计划,然后会进行执行(执行到物理执行计划生成),然后把这个table再放回catalog里维护起来,这个时候的执行计划已经是最终要执行的物理执行计划了。但是此时Columner模块相关的转换等操作都是没有触发的。
真正的触发还是在execute()的时候,同其他SparkPlan的execute()方法触发场景是一样的。
7、Uncache逻辑
UncacheTable的时候,除了删除catalog里的table信息之外,还调用了InMemoryColumnarTableScan的cacheColumnBuffers方法,得到RDD集合,并进行了unpersist()操作。cacheColumnBuffers主要做了把RDD每个partition里的ROW的每个Field存到了ColumnBuilder内。
UDF(暂不支持) 如前面对SQLContext里Analyzer的分析,其FunctionRegistry没有实现lookupFunction。
在spark-hive项目里,HiveContext里是实现了FunctionRegistry这个trait的,其实现为HiveFunctionRegistry,实现逻辑见org.apache.spark.sql.hive.hiveUdfs
8、Parquet支持
9、JSON支持
SQLContext下,增加了jsonFile的读取方法,而且目前看,代码里实现的是hadoop textfile的读取,也就是这份json文件应该是在HDFS上的。具体这份json文件的载入,InputFormat是TextInputFormat,key class是LongWritable,value class是Text,最后得到的是value部分的那段String内容,即RDD[String]。 除了jsonFile,还支持jsonRDD,例子:
读取json文件之后,转换成SchemaRDD。JsonRDD.inferSchema(RDD[String])里有详细的解析json和映射出schema的过程,最后得到该json的LogicalPlan。 Json的解析使用的是FasterXML/jackson-databind库,GitHub地址,wiki 把数据映射成Map[String, Any] Json的支持丰富了Spark SQL数据接入场景。
Jdbc support branchis under going
SQL92 Spark SQL目前的SQL语法支持情况见SqlParser类。目标是支持SQL92??
-
基本应用上,sql server 和oracle都遵循sql 92语法标准。
-
实际应用中大家都会超出以上标准,使用各家数据库厂商都提供的丰富的自定义标准函数库和语法。
-
微软sql server的sql 扩展叫T-SQL(Transcate SQL).
-
Oracle 的sql 扩展叫PL-SQL.
-
-
-
总结 以上整理了对Spark SQL各个模块的实现情况,代码结构,执行流程以及自己对Spark SQL的理解。