
这篇博客主要简单介绍Netty上表中的组件
1. Bootstrap、ServerBootstrap
Bootstrap意思是引导,一个Netty应用通常由一个Bootstrap开始,主要作用是配置整个Netty程序,串联各个组件,Netty中Bootstrap类是客户端程序的启动引导类,ServerBootstrap是服务端启动引导类
常见的方法有
public ServerBootstrap group(EventLoopGroup parentGroup, EventLoopGroup childGroup) #该方法用于服务器端,用来设置两个EventLoopGroup public B group(EventLoopGroup group) #该方法用于客户端,用来设置一个EventLoopGroup public B channel(Class<? extends C> channelClass) #该方法用来设置一个服务器端的通道实现 public <T> B option(ChannelOption<T> option, T value) #用来给ServerChannel添加配置 public <T> ServerBootstrap childOption(ChannelOption<T> childOption, T value) #用来给接收到的通道添加配置 public ServerBootstrap childHandler(ChannelHandler childHandler) #该方法用来设置业务处理Handler(自定义的handler) public ChannelFuture bind(int inetPort) #该方法用于服务器端,用来设置占用的端口号 public ChannelFuture connect(String inetHost, int inetPort) #该方法用于客户端,用来连接服务器端
2. Future,ChannelFuture
Netty 中所有的 IO 操作都是异步的,不能立刻得知消息是否被正确处理。但是可以过一会等它执行完成或者直接注册一个监听,具体的实现就是通Future和ChannelFuture,他们可以注册一个监听,当操作执行成功或失败时监听会自动触发注册的监听事件
常见的方法有
Channel channel() #返回当前正在进行IO操作的通道
ChannelFuture sync() #等待异步操作执行完毕
3. Channel
Netty网络通信的组件,能够用于执行网络I/O操作。通过Channel可获得当前网络连接的通道的状态。通过Channel可获得网络连接的配置参数(例如接收缓冲区大小)。 Channel提供异步的网络I/O操作(如建立连接,读写,绑定端口),异步调用意味着任何 I/O 调用都将立即返回,并且不保证在调用结束时所请求的I/O操作已完成。调用立即返回一个ChannelFuture实例,通过注册监听器到ChannelFuture上,可以I/O操作成功、失败或取消时回调通知调用方。支持关联 I/O操作与对应的处理程序
不同协议、不同的阻塞类型的连接都有不同的 Channel 类型与之对应,常用的 Channel 类型:
NioSocketChannel #异步的客户端TCP Socket连接
NioServerSocketChannel #异步的服务器端TCP Socket连接
NioDatagramChannel #异步的UDP连接
NioSctpChannel #异步的客户端Sctp连接
NioSctpServerChannel #异步的Sctp服务器端连接,这些通道涵盖了UDP和TCP网络IO以及文件IO
4. Selector
Netty基于Selector对象实现I/O多路复用,通过Selector一个线程可以监听多个连接的Channel事件。当向一个Selector中注册Channel后,Selector内部的机制就可以自动不断地查询(Select) 这些注册的Channel是否有已就绪的I/O事件(例如可读,可写,网络连接完成等),这样程序就可以很简单地使用一个线程高效地管理多个Channel
5. ChannelHandler
ChannelHandler是一个接口,处理I/O事件或拦截I/O操作,并将其转发到其ChannelPipeline(业务处理链)中的下一个处理程序。ChannelHandler本身并没有提供很多方法,因为这个接口有许多的方法需要实现,方便使用期间可以继承它的子类
ChannelHandler及其实现类
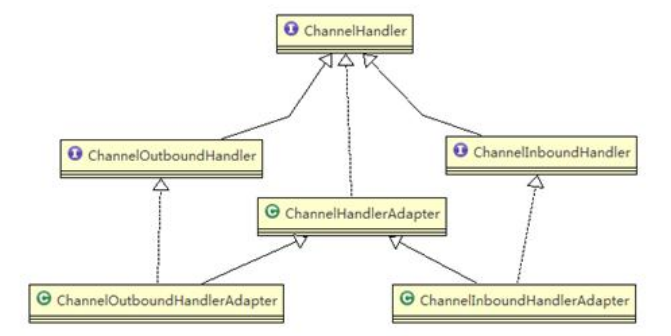
ChannelInboundHandler / ChannelInboundHandlerAdapter- 处理入站I/O事件
ChannelOutboundHandler / ChannelOutboundHandlerAdapter - 处理出站I/O事件
我们经常需要自定义一个Handler类去继承ChannelInboundHandlerAdapter,然后通过重写相应方法实现业务逻辑,可以重写方法如下
// channel注册事件 public void channelRegistered(ChannelHandlerContext ctx) // channel取消注册事件 public void channelUnregistered(ChannelHandlerContext ctx) // channel激活事件 public void channelActive(ChannelHandlerContext ctx) // channel不活跃事件 public void channelInactive(ChannelHandlerContext ctx) // channel读取事件 public void channelRead(ChannelHandlerContext ctx, Object msg) // channel读取完毕事件 public void channelReadComplete(ChannelHandlerContext ctx) // channel用户事件触发事件 public void userEventTriggered(ChannelHandlerContext ctx, Object evt) // channel可写改变事件 public void channelWritabilityChanged(ChannelHandlerContext ctx) // channel捕获到异常 public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
6. ChannelPipeline
ChannelPipeline是一个Handler的集合,它负责处理和拦截inbound或者outbound的事件和操作,相当于一个贯穿Netty的链。(即:ChannelPipeline是保存ChannelHandler的List,用于处理或拦截Channel的入站事件和出站操作)。ChannelPipeline实现了一种高级形式的拦截过滤器模式,使用户可以完全控制事件的处理方式,以及Channel中各个的ChannelHandler如何相互交互。在Netty中每个Channel都有且仅有一个ChannelPipeline与之对应,它们的组成关系如下
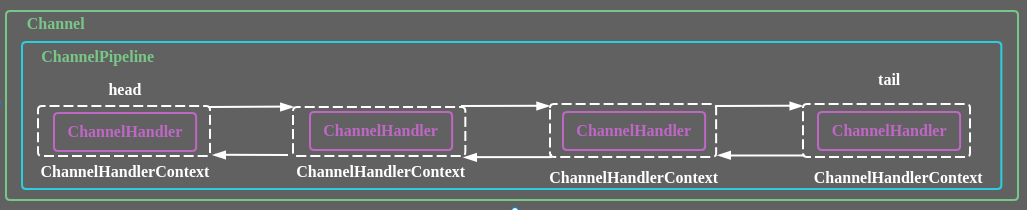
1. 一个Channel包含了一个ChannelPipeline,ChannelPipeline中又维护了一个由ChannelHandlerContext组成的双向链表,并且每个ChannelHandlerContext中又关联着一个ChannelHandler
2. 入站事件和出站事件在一个双向链表中,入站事件会从链表的head向后传递到最后一个入站的handler,出站事件会从tail向前传递到最前一个出站的handler,两张类型的handler互不干扰
7. ChannelHandlerContext
保存Channel相关的所有上下文信息,同时关联一个ChannelHandler对象。即ChannelHandlerContext中包含一个具体的事件处理器ChannelHandler, 同时ChannelHandlerContext中也绑定了对应的pipeline和Channel的信息,方便对ChannelHandler进行调用
ChannelHandlerContext常用方法
Channel channel() #获取通道 : 在ChannelHandlerContext接口中定义的方法
ChannelPipeline pipeline() #获取管道 : 在ChannelHandlerContext接口中定义的方法
ChannelHandler handler() #获取处理器 : 在ChannelHandlerContext接口中定义的方法
ChannelHandlerContext flush() #刷新数据 : 在ChannelHandlerContext接口中定义的方法
ChannelFuture close() #关闭通道 : 在ChannelOutboundInvoker接口中定义的方法
ChannelFuture writeAndFlush(Object msg) #写出数据 : 在ChannelOutboundInvoker接口中定义的方法 , 作用是将数据写出到ChannelPipeline管道中
8. ChannelOption
Netty在创建Channel实例后, 一般都需要设置ChannelOption参数。ChannelOption参数如下:
1、ChannelOption.SO_BACKLOG ChannelOption.SO_BACKLOG对应的是tcp/ip协议listen函数中的backlog参数,函数listen(int socketfd,int backlog)用来初始化服务端可连接队列,
服务端处理客户端连接请求是顺序处理的,所以同一时间只能处理一个客户端连接,多个客户端来的时候,服务端将不能处理的客户端连接请求放在队列中等待处理,
backlog参数指定了队列的大小 2、ChannelOption.SO_REUSEADDR 这个参数表示允许重复使用本地地址和端口,比如,某个服务器进程占用了TCP的80端口进行监听,此时再次监听该端口就会返回错误,使用该参数就可以解决问题,该参数允许共用该端口,
这个在服务器程序中比较常使用,比如某个进程非正常退出,该程序占用的端口可能要被占用一段时间才能允许其他进程使用,而且程序死掉以后,内核一需要一定的时间才能够释放此端口,
不设置SO_REUSEADDR就无法正常使用该端口。 3、ChannelOption.SO_KEEPALIVE 该参数用于设置TCP连接,当设置该选项以后,连接会测试链接的状态,这个选项用于可能长时间没有数据交流的连接。当设置该选项以后,如果在两小时内没有数据的通信时,
TCP会自动发送一个活动探测数据报文。 4、ChannelOption.SO_SNDBUF和ChannelOption.SO_RCVBUF 这两个参数用于操作接收缓冲区和发送缓冲区的大小,接收缓冲区用于保存网络协议站内收到的数据,直到应用程序读取成功,发送缓冲区用于保存发送数据,直到发送成功。 5、ChannelOption.SO_LINGER Linux内核默认的处理方式是当用户调用close()方法的时候,函数返回,在可能的情况下,尽量发送数据,不一定保证会发生剩余的数据,造成了数据的不确定性,
使用SO_LINGER可以阻塞close()的调用时间,直到数据完全发送 6、ChannelOption.TCP_NODELAY 该参数的使用与Nagle算法有关,Nagle算法是将小的数据包组装为更大的帧然后进行发送,而不是输入一次发送一次,因此在数据包不足的时候会等待其他数据的到了,组装成大的数据包进行发送,
虽然该方式有效提高网络的有效负载,但是却造成了延时,而该参数的作用就是禁止使用Nagle算法,使用于小数据即时传输,于TCP_NODELAY相对应的是TCP_CORK,
该选项是需要等到发送的数据量最大的时候,一次性发送数据,适用于文件传输。
9. EventLoopGroup,NioEventLoopGroup
对于Netty的使用,都会使用bossGroup和workerGroup的方式,而常说的bossGroup和workerGroup其实是NioEventLoopGroup的实例。在Netty中,EventLoopGroup和NioEventLoopGroup其实就是一个线程池。EventLoopGroup是一组EventLoop的抽象, Netty为了更好的利用多核CPU资源,一般会有多个EventLoop同时工作,每个EventLoop维护着一个Selector实例。EventLoopGroup提供next接口,可以从组里面按照一定规则获取其中一个EventLoop来处理任务。通常一个服务端口即一个ServerSocketChannel对应一个Selector和一个EventLoop线程。 BossEventLoop负责接收客户端的连接并将SocketChannel交给WorkerEventLoopGroup来进行IO处理
10. Unpooled
Netty 提供一个专门用来操作缓冲区(即Netty的数据容器)的工具类
常用方法
public static ByteBuf copiedBuffer(CharSequence string, Charset charset) #通过给定的数据和字符编码返回ByteBuf
通过readerindex和writerIndex和capacity, 将buffer分成三个区域
0---readerindex 已经读取的区域 readerindex---writerIndex 可读的区域 writerIndex -- capacity 可写的区域
样例代码
package com.kawa.io.netty; import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled; import io.netty.util.CharsetUtil; import lombok.extern.slf4j.Slf4j; import org.junit.Test; @Slf4j public class UnpooledTest { @Test public void Unpooled_Test_CopiedBuffer() { ByteBuf byteBuf = Unpooled.copiedBuffer("{'region':'cn'}", CharsetUtil.UTF_8); if (byteBuf.hasArray()) { byte[] bytes = byteBuf.array(); log.info(">>>>>>>>>> byteBuf: {}", byteBuf); log.info(">>>>>>>>>> byteBuf convert to String: {}", new String(bytes, CharsetUtil.UTF_8)); log.info(">>>>>>>>>> byteBuf arrayOffset:{}, readerIndex:{}, writerIndex:{}, capacity:{}", byteBuf.arrayOffset(), byteBuf.readerIndex(), byteBuf.writerIndex(), byteBuf.capacity()); log.info(">>>>>>>>>> byteBuf > getByte: {}", (char) byteBuf.getByte(0)); log.info(">>>>>>>>>> byteBuf > readableBytes: {}", byteBuf.readableBytes()); log.info(">>>>>>>>>> byteBuf arrayOffset:{}, readerIndex:{}, writerIndex:{}, capacity:{}", byteBuf.arrayOffset(), byteBuf.readerIndex(), byteBuf.writerIndex(), byteBuf.capacity()); log.info(">>>>>>>>>> byteBuf > readByte: {}", (char) byteBuf.readByte()); log.info(">>>>>>>>>> byteBuf > readableBytes: {}", byteBuf.readableBytes()); log.info(">>>>>>>>>> byteBuf arrayOffset:{}, readerIndex:{}, writerIndex:{}, capacity:{}", byteBuf.arrayOffset(), byteBuf.readerIndex(), byteBuf.writerIndex(), byteBuf.capacity()); log.info(">>>>>>>>>> byteBuf > readByte: {}", (char) byteBuf.readByte()); log.info(">>>>>>>>>> byteBuf > readableBytes: {}", byteBuf.readableBytes()); log.info(">>>>>>>>>> byteBuf arrayOffset:{}, readerIndex:{}, writerIndex:{}, capacity:{}", byteBuf.arrayOffset(), byteBuf.readerIndex(), byteBuf.writerIndex(), byteBuf.capacity()); log.info(">>>>>>>>>> byteBuf > getCharSequence: {}", byteBuf.getCharSequence(2, 5, CharsetUtil.UTF_8)); log.info(">>>>>>>>>> byteBuf > getCharSequence: {}", byteBuf.getCharSequence(5, 10, CharsetUtil.UTF_8)); } } }