本次作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
1.安装Linux
(1)新建虚拟电脑

(2)配置虚拟电脑

(3)完成虚拟电脑的配置
(4)添加ubuntu ISO镜像文件进行ubuntu操作系统安装
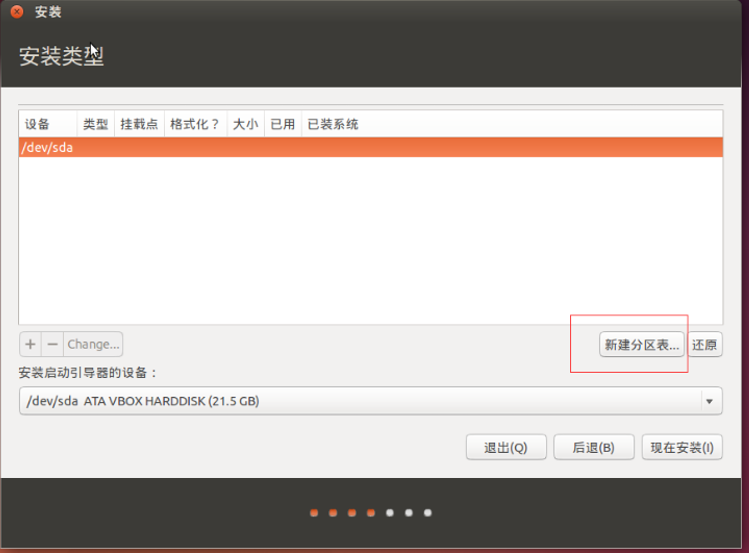
(5)对ubuntu进行分区

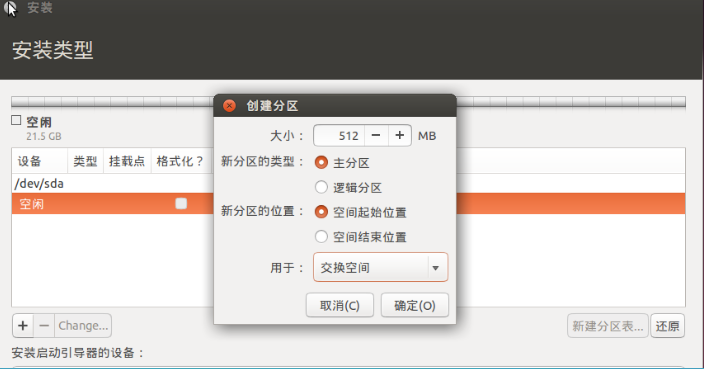

(5)添加用户,至此完成安装,重启登录
2.安装MySql
(1)保证在联网状态下安装

(2)启动与关闭mysql数据库

(3)查看是否启动成功

(4)进入mysql
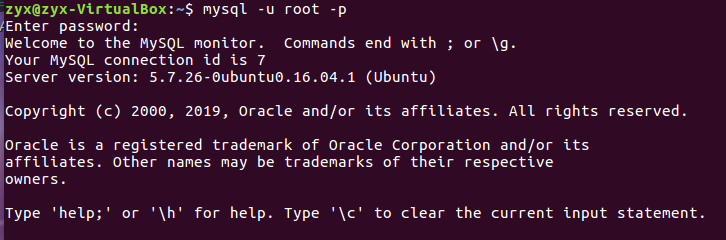
(5)显示数据库
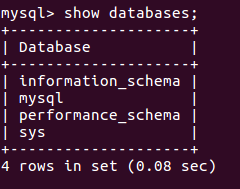
(6)查看数据库中的表

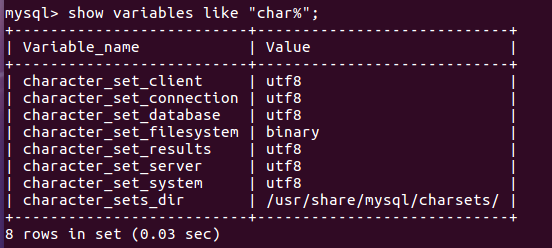
(7)修改并查看数据库的编码
3.windows 与 虚拟机互传文件
详细教程请查看:https://www.cnblogs.com/dong-blog/p/7207831.html
(1)安装VirtualBox增强功能包
(2)在本机系统设置一个共享文件夹,用于与Ubuntu交互的区域空间。

(3)设置共享配置

(4)共享成功

4.安装Hadoop
还不能从windows复制文件的,可在虚拟机里用浏览器下载安装文件:
提取文件:hadoop-2.7.1.tar.gz
链接: https://pan.baidu.com/s/1HIVd9JCZstWm0k7sAbXQCg
提取码: 2thj
(1)创建hadoop用户,设置用户名和密码,最后添加管理员权限

![]()

(2)安装ssh,ssh无密码登录
![]()

(3)复制hadoop-2.7.1.tar.gz到/usr/local中,我的hadoop-2.7.1.tar.gz文件源在/mnt/share/hadoop-2.7.1.tar.gz,解压后把名字改成hadoop,并修改文件权限为hadoop

(4)查看hadoop是否可用

(5)安装OpenJDK的java环境,修改~/.bashrc文件:在文件最前面或最后添加如下单独一行(注意,等号“=”前后不能有空格)

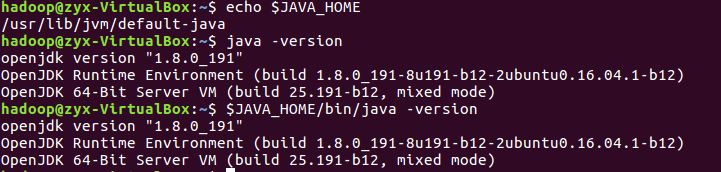
(6)使环境变量生效,并查看设置是否正确
![]()
(7)运行单机版实例,出现一个dfsadmin信息即单机版成功安装

![]()
(8)伪分布式配置:修改配置文件 core-site.xml 和 hdfs-site.xml,并执行 NameNode 的格式化


<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>

(9)启动NameNode”、”DataNode” 和 “SecondaryNameNode”进程,并查看是否成功启动


(10)伪分布式读取的是 HDFS 上的数据,要使用 HDFS。
首先需要在 HDFS 中创建用户目录;创建目录 input,其对应的绝对路径就是 /user/hadoop/input:;将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。

查看文件列表:

(11)运行伪分布式实例,并将结果复制到本地

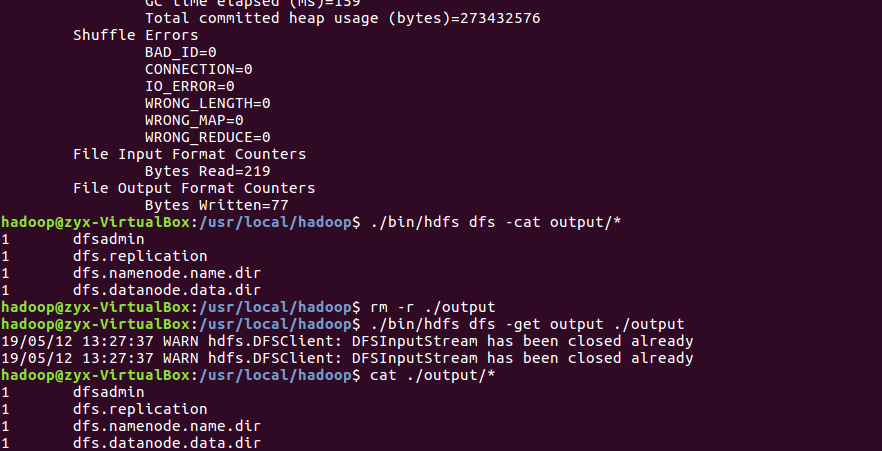
附:问题解决
问题:运行实例时,出现虚拟机内存不够分配的情况
解决方法一:在root用户下用echo 65530 /proc/sys/vm/max_map_count分配足够大的内存


解决方法去二:创建swapfile,将swapfile设置为swap空间,启用交换空间
