作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2684
1.字符串操作:
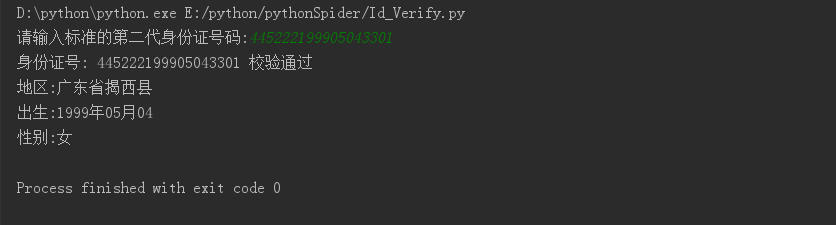
解析身份证号:生日、性别、出生地等
import requests import chardet from bs4 import BeautifulSoup from fake_useragent import UserAgent def get_ID_Info(Id): url = "http://blog.sina.com.cn/s/blog_55a319c701015pjt.html" ua = UserAgent() headers = {'User_Agent':ua.random} html = requests.get(url,headers=headers) charset = chardet.detect(html.content) html.encoding = charset['encoding'] soup = BeautifulSoup(html.text,'lxml') areaInfo = soup.select('#sina_keyword_ad_area2')[0].get_text(' ','<br/>').replace("u3000",' ') areaInfo = ' '.join(areaInfo.split()).split(' ') for areaVerify in areaInfo: if Id[0:6] == areaVerify: i = areaInfo.index(areaVerify)+1 print(u"地区:{}".format(areaInfo[i])) print(u"出生:%s" % (Id[6:10] + '年' + Id[10:12] + '月' + Id[12:14])) if (int(Id[-2])%2) == 0: sex = "女" else: sex = "男" print(u"性别:%s" % sex) def check_ID_Number(Id): str_to_int = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9, 'X': 10} check_dict = {0: '1', 1: '0', 2: 'X', 3: '9', 4: '8', 5: '7', 6: '6', 7: '5', 8: '4', 9: '3', 10: '2'} if len(Id) != 18: raise TypeError(u'请输入标准的第二代身份证号码') check_num = 0 for index, num in enumerate(Id): if index == 17: right_code = check_dict.get(check_num % 11) if num == right_code: print(u"身份证号: %s 校验通过" % Id) return True else: print(u"身份证号: %s 校验不通过, 正确尾号应该为:%s" % (Id, right_code)) return False check_num += str_to_int.get(num) * (2 ** (17 - index) % 11) if __name__ == '__main__': Id = input(u'请输入标准的第二代身份证号码:') Id = str(Id) if check_ID_Number(Id): get_ID_Info(Id)
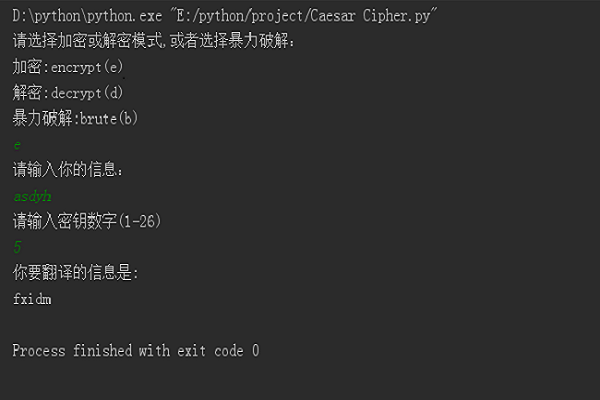
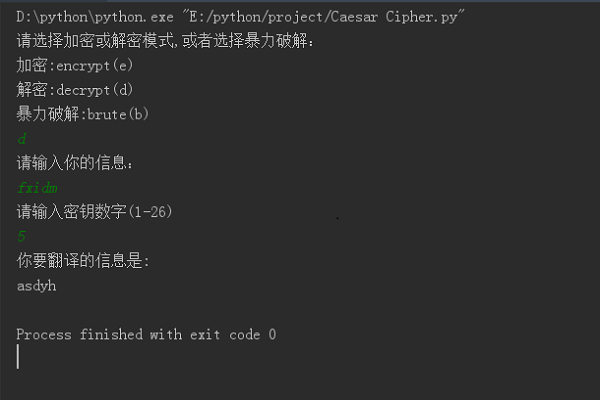
凯撒密码编码与解码
MAX_KEY_SIZE = 26 def getMode(): while True: print('请选择加密或解密模式,或者选择暴力破解:') print('加密:encrypt(e)') print('解密:decrypt(d)') print('暴力破解:brute(b)') mode = input().lower() if mode in 'encrypt e decrypt d brute b'.split(): return mode else: print('请输入"encrypt"或"e"或"decrypt"或"d"或"brute"或"b"!') def getMessage(): print('请输入你的信息:') return input() def getKey(): key = 0 while True: print('请输入密钥数字(1-%s)' % (MAX_KEY_SIZE)) key = int(input()) if (key >=1 and key <= MAX_KEY_SIZE): return key def getTranslatedMessage(mode, message, key): if mode[0] == 'd': key = -key translated = '' for symbol in message: if symbol.isalpha(): num = ord(symbol) num += key if symbol.isupper(): if num > ord('Z'): num -= 26 elif num < ord('A'): num += 26 elif symbol.islower(): if num > ord('z'): num -= 26 elif num < ord('a'): num += 26 translated += chr(num) else: translated += symbol return translated if __name__ == '__main__': mode = getMode() message = getMessage() if mode[0] != 'b': key = getKey() print('你要翻译的信息是:') if mode[0] != 'b': print(getTranslatedMessage(mode, message, key)) else: for key in range(1, MAX_KEY_SIZE + 1): print(key, getTranslatedMessage('decrypt', message, key))
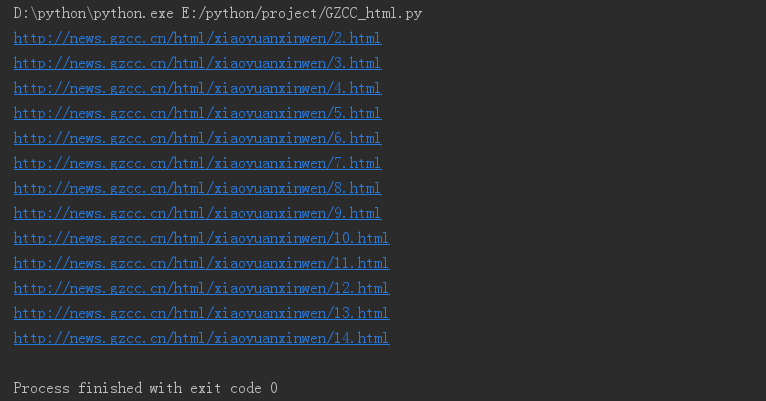
网址观察与批量生成
for i in range(2,15): print('http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i))
2.英文词频统计预处理
下载一首英文的歌词或文章或小说
将所有大写转换为小写
将所有其他做分隔符(,.?!)替换为空格
分隔出一个一个的单词
并统计单词出现的次数
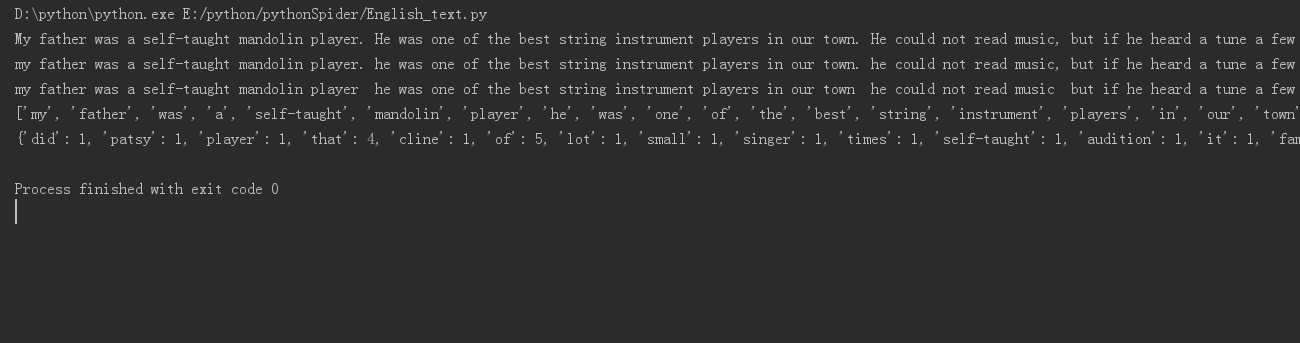
import requests import chardet from bs4 import BeautifulSoup from fake_useragent import UserAgent def Info(): url = "http://www.duwenzhang.com/wenzhang/yingyuwenzhang/20130519/255870.html" ua = UserAgent() headers = {'User_Agent':ua.random} html = requests.get(url,headers=headers) charset = chardet.detect(html.content) html.encoding = charset['encoding'] soup = BeautifulSoup(html.text,'lxml') engInfo = soup.find('div',{'class':'article 255870'}).find_all('p')[0].get_text(' ','<br/>').replace("u3000",' ')#获取文本 print(engInfo) engInfo = engInfo.lower()#将所有大写转换为小写 print(engInfo) s = ',.?!' for i in s: engInfo = engInfo.replace(i,' ')#将所有其他做分隔符(,.?!)替换为空格 print(engInfo) engInfo = engInfo.split()#分隔出一个一个的单词 print(engInfo) InfoSet = set(engInfo) Count = {} for word in InfoSet: Count.setdefault(word,engInfo.count(word))#统计单词出现的次数 print(Count) if __name__ == '__main__': Info()
3.文件操作
同一目录、绝对路径、相对路径
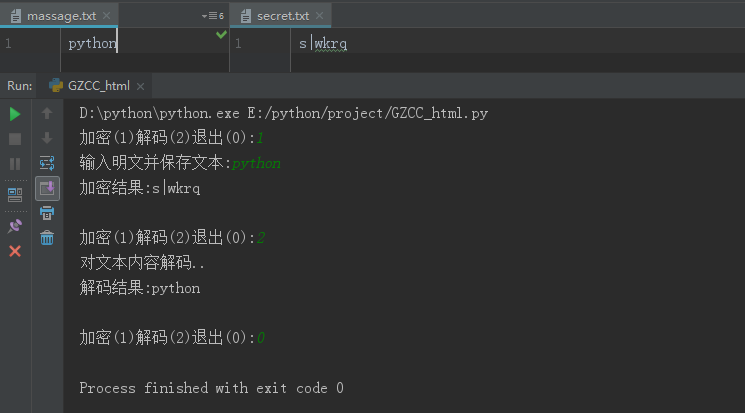
凯撒密码:从文件读入密函,进行加密或解密,保存到文件。
def getMima(): Massage = str(input("输入明文并保存文本:")) with open('massage.txt','w') as f: f.write(Massage) f.close() Mima = '' for i in Massage: Mima = Mima + chr(ord(i)+3) print('加密结果:'+Mima+' ') with open('secret.txt','w') as f: f.write(Mima) f.close() def getMassageFromTXT(): print("对文本内容解码..") with open('secret.txt','r') as f: s = f.read() Massage = '' if s == None: print('没有可解码的文本 ') else: for i in s: Massage = Massage + chr(ord(i)-3) print('解码结果:'+Massage+' ') if __name__ == '__main__': while 1: a = int(input('加密(1)解码(2)退出(0):')) if a == 0: break elif a == 1: getMima() elif a == 2: getMassageFromTXT()
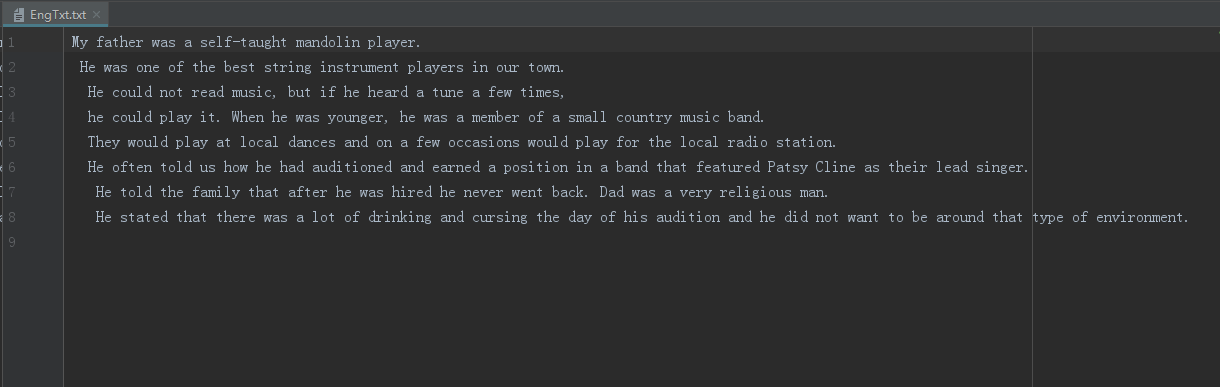
词频统计:下载一首英文的歌词或文章或小说,保存为utf8文件。从文件读入文本进行处理。
engInfo = '''My father was a self-taught mandolin player. He was one of the best string instrument players in our town. He could not read music, but if he heard a tune a few times, he could play it. When he was younger, he was a member of a small country music band. They would play at local dances and on a few occasions would play for the local radio station. He often told us how he had auditioned and earned a position in a band that featured Patsy Cline as their lead singer. He told the family that after he was hired he never went back. Dad was a very religious man. He stated that there was a lot of drinking and cursing the day of his audition and he did not want to be around that type of environment. ''' f = open('EngTxt.txt','a',encoding='utf-8') f.write(engInfo) f.close()
4.函数定义
加密函数、解密函数
def getTranslatedMessage(mode, message, key): if mode[0] == 'd': key = -key translated = '' for symbol in message: if symbol.isalpha(): num = ord(symbol) num += key if symbol.isupper(): if num > ord('Z'): num -= 26 elif num < ord('A'): num += 26 elif symbol.islower(): if num > ord('z'): num -= 26 elif num < ord('a'): num += 26 translated += chr(num) else: translated += symbol return translated
读文本函数
def getMima(): Massage = str(input("输入明文并保存文本:")) with open('massage.txt','w') as f: f.write(Massage) f.close() Mima = '' for i in Massage: Mima = Mima + chr(ord(i)+3) print('加密结果:'+Mima+' ') with open('secret.txt','w') as f: f.write(Mima) f.close()