问题发现:
最近线上一个后端接口项目连续两天中午12点30分左右QPS激增,导致2台实例中的某一台由于垃圾回收问题,导致CPU占用持续偏高,触发监控系统CPU占用告警和响应时间超时告警。
现象如下:

QPS瞬时激增后回落
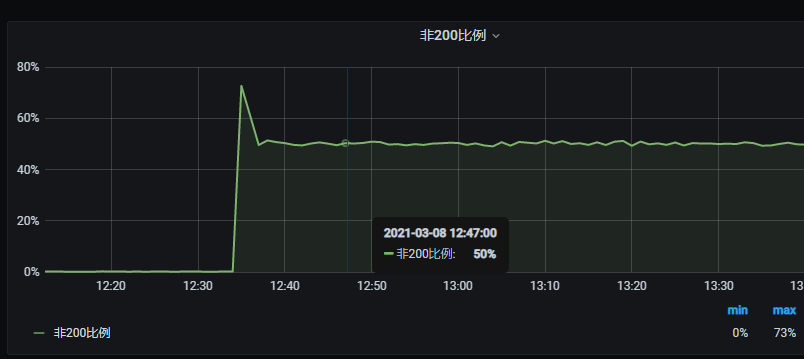
接口非200请求比例上升
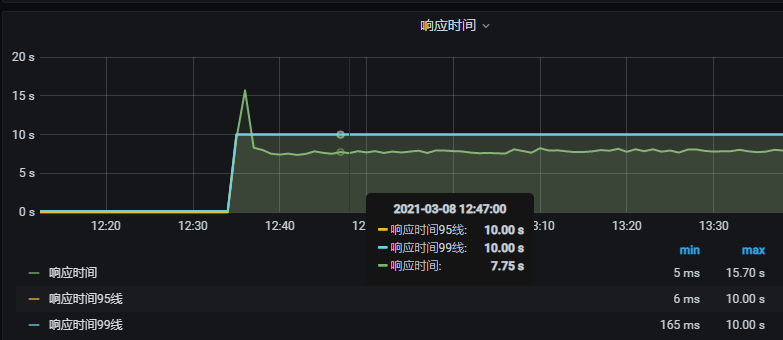
响应时间增加

服务器CPU占用增高

TCP连接情况
使用
jstat -gcutil ps
命令打印JVM 的gc日志,发现JVM一直出于频繁Full gc的状态,这也是导致机器CPU占用一直居高不下的原因。
接下来使用
jmap -dump:file=xxx.dump ps
命令导出内存映像文件,并使用Eclipse MAT 工具分析内存映像文件,结果如下:

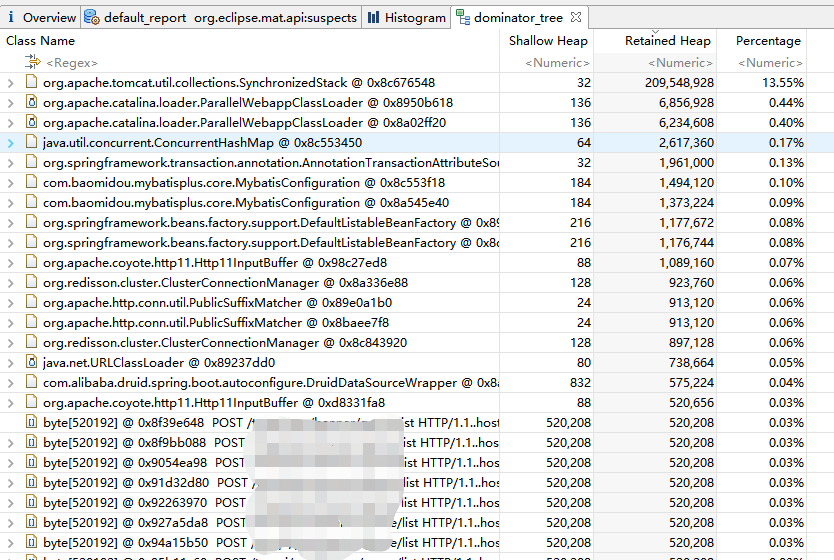
说明: Shallow Heap(浅堆)表示此对象占用的堆大小,包含对象的对象头,实例数据、对齐空间。 Retained Heap(深堆)表示该对象被回收后,能够释放的内存大小。

问题解决:
从内存占用分析可看出,大部分的内存空间都被byte数组占用了,Http11OutPutBuffer 这个类也占用了500多KB的内存,上图的依赖树表里可以看出Http11InPutBuffer、Http11OutPutBuffer 中大部分的空间都被byte数组占用了,而持有byte数组的类 是HeapByteBuffer。
我们知道Http11OutPutBuffer 这个类,是属于tomcat中的,而我的项目中使用的是外置的Tomcat 9,所以就需要检查一下Tomcat中的相关配置:
<Connector port="8084" relaxedPathChars="|{}[]," relaxedQueryChars="|{}[]," executor="tomcatThreadPool" connectionTimeout="30000" keepAliveTimeout="-1" maxKeepAliveRequests="-1" protocol="org.apache.coyote.http11.Http11Nio2Protocol" enableLookups="false" socketBuffer="65536" maxHttpHeaderSize ="512000" URIEncoding="UTF-8" redirectPort="8443" /> <Executor name="tomcatThreadPool" namePrefix="catalina-exec-" maxThreads="600" minSpareThreads="100"/>
由上可发现maxHttpHeaderSize的大小竟然和上面的byte数组大小一致,而官方文档 中的默认配置仅为8192,也就是8KB。
所以我将maxHttpHeaderSize值调整为了默认值8192,同时将socketBuffer的值也减小为了默认值9000。
另外,还将tomcat线程池的配置也优化了一下,通过观察监控,发现这个后台接口平均QPS在600左右,所以我将minSpareThreads这个值修改成了600,保证有足够的空闲线程支撑平时的访问量,同时将maxThreads调整成了2000,注意这个值不能调的过大,过大的话会导致CPU 花费过多的时间在线程 上下文切换上,导致运行效率的下降。我的这个后台接口仅做数据查询,对CPU资源消耗较少,所以我将maxThreads设置的较大一点,同时也满足高峰时的并发请求。
同时,由于项目中是使用的Nginx作为前置代理网关,为保证Nginx和Tomcat之间的连接高效,我将Nginx和Tomcat之间的连接配置成了长连接。参考:https://blog.csdn.net/nimasike/article/details/81129163
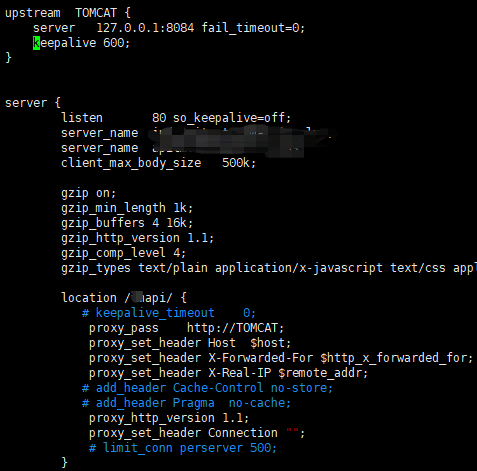
上图中的keepalive 600 为配置Nginx和Tomcat之间的 空闲长连接个数为600个,另外配置了proxy_http_version 1.1; proxy_set_header Connection ""; 保证Nginx和Tomcat之间的网络连接高效利用。
而客户端到Nginx端我根据我们业务的情况,限制了他们之间的长连接:
http{ keepalive_timeout 15s; keepalive_requests 10; }
以便于在高峰期尽快释放连接。
同时还配置了Nginx里的请求体压缩功能,这个也是常见的优化手段。
优化后的效果如下:

12点30分高峰准时来临
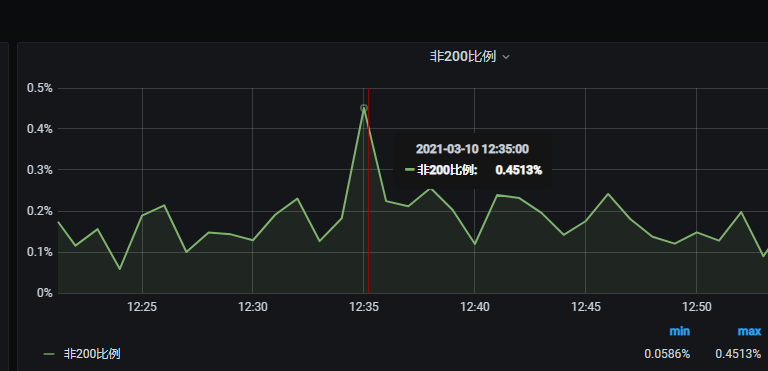
非200响应无较大变化
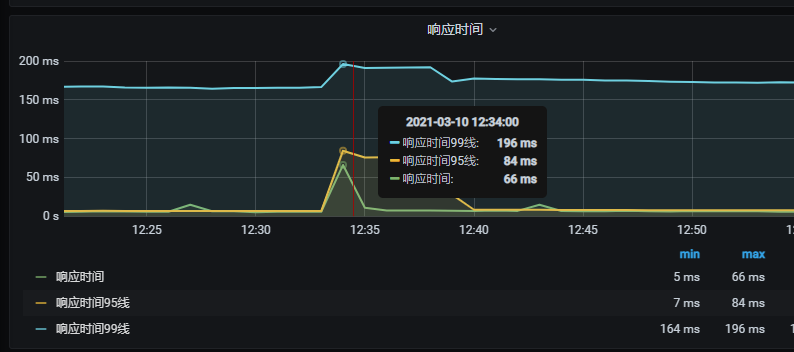
响应时间无较大变化
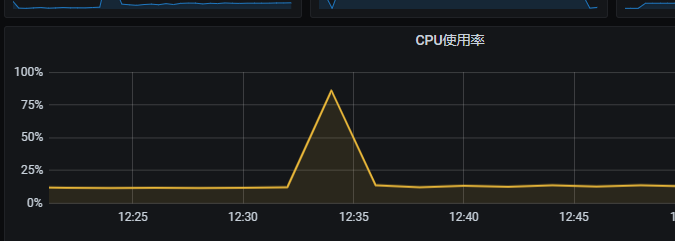
CPU飙升后迅速回落

TCP连接情况,可以看到_tw 也就是timewait状态的连接相比之前变多了,这是我们调整限制了Nginx和客户端之间的长连接后的结果。
以上就是这次线上OOM问题的解决过程,欢迎讨论。