前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。

最近发现了一个不错的数据网站,叫“淘数据”。里面的数据都是淘宝的商家数据,包含了店名、类目、标价、成交均价、销量、销售金额等
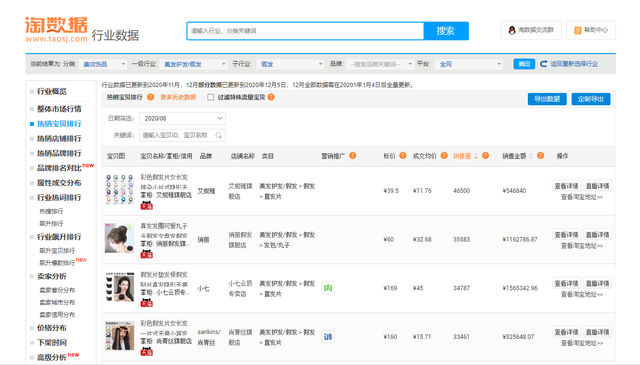
这个网站还是一位同学和我说才知道的,既然这样,那就开始爬

项目目标
爬取淘宝假发专业数据,假发是我当时随便选的,再想选别的,要收费了

可能是命运的安排吧,知道程序员需要什么

受害者地址
https://www.taosj.com/industry/index.html#/data/hotitems/?cid=50023283&brand=&type=&pcid=
环境
Python3.6
pycharm
爬虫代码
导入所需工具
import requests import csv
分析网页,先F12打开开发者工具,复制你所需要的数据,找数据所在的标签
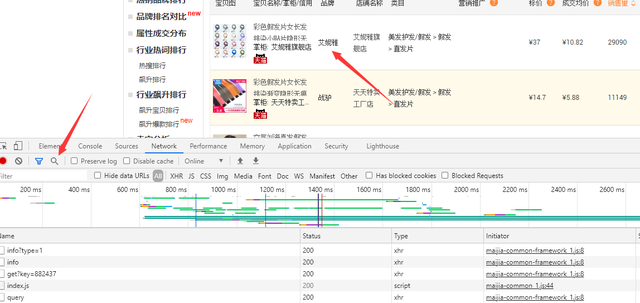
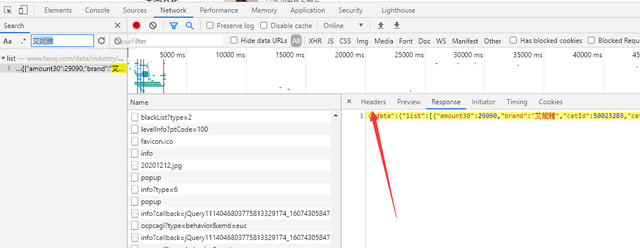
找到所需要的URL和headers中的参数
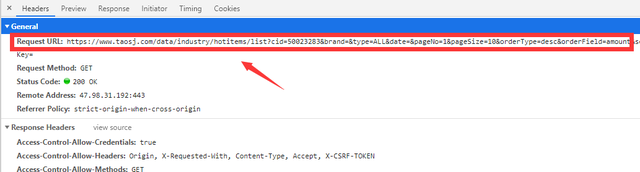
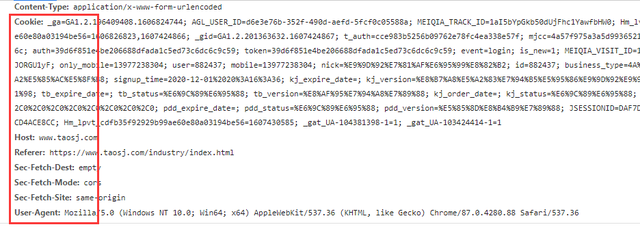
url = 'https://www.taosj.com/data/industry/hotitems/list?cid=50023283&brand=&type=ALL&date=1596211200000&pageNo=1&pageSize=10&orderType=desc&orderField='.format(page) headers = { 'Host':'www.taosj.com', 'Referer':'https://www.taosj.com/industry/index.html', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', } response = requests.get(url=url, headers=headers) html_data = response.json()
在json数据中提取相关数据
lis = html_data['data']['list'] for li in lis: tb_url = 'https://detail.tmall.com/item.htm?id={}'.format(li['id']) dit = { '标题': li['title'], '店铺名称': li['shop'], '类目': li['nextCatName'], '标价': li['oriPrice'], '成交均价': li['price'], '销售量': li['offer30'], '销售金额': li['price30'], '淘宝地址': tb_url, }
保存数据
f = open('淘数据.csv', mode='a', encoding='utf-8-sig', newline='') csv_writer = csv.DictWriter(f, fieldnames=['标题', '品牌', '店铺名称', '类目', '标价', '成交均价', '销售量', '销售金额', '淘宝地址']) csv_writer.writeheader() print(dit)
效果图
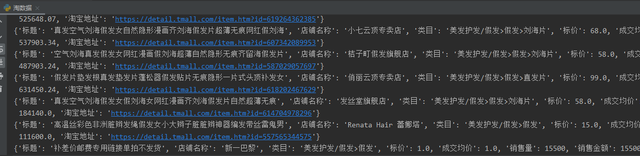

完整代码
import requests import csv f = open('淘数据.csv', mode='a', encoding='utf-8-sig', newline='') csv_writer = csv.DictWriter(f, fieldnames=['标题', '品牌', '店铺名称', '类目', '标价', '成交均价', '销售量', '销售金额', '淘宝地址']) csv_writer.writeheader() for page in range(1, 51): url = 'https://www.taosj.com/data/industry/hotitems/list?cid=50023282&brand=&type=ALL&date=1596211200000&pageNo={}&pageSize=10&orderType=desc&orderField=amount&searchKey='.format(page) """ 复制开发者工具中的requests headers 中的参数 记得加cookie """ headers = { 'Host': 'www.taosj.com', 'Referer': 'https://www.taosj.com/industry/index.html', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', } response = requests.get(url=url, headers=headers) html_data = response.json() lis = html_data['data']['list'] for li in lis: tb_url = 'https://detail.tmall.com/item.htm?id={}'.format(li['id']) dit = { '标题': li['title'], '品牌': li['brand'], '店铺名称': li['shop'], '类目': li['nextCatName'], '标价': li['oriPrice'], '成交均价': li['price'], '销售量': li['offer30'], '销售金额': li['price30'], '淘宝地址': tb_url, } csv_writer.writerow(dit) print(dit)