1.用fork创建进程(Linux中使用)
1 import os 2 #fork函数,只在Unix/Linux/Mac上运⾏,windows不可以 3 pid = os.fork() 4 if pid == 0: 5 print('hello--1') 6 else: 7 print('hello--2')
程序走到os.fork()时,会创建出一个子进程,并将父进程中的所有信息复制到子进程中,父进程和子进程都会从os.fork()中得到一个返回值,子进程中这个返回值是0,而父进程中这个返回值就是子进程的id号
注意:fork被调用时会返回两个值,一个是代表子进程的0,另一个是代表父进程的子进程id号
父进程、子进程的执行顺序没有规律,完全取决于系统的调度算法
获取进程id号:
获取当前进程的进程id号: getpid()
获取父进程的进程id号: getppid()
多进程对于全局变量的影响:
多进程中,每个进程所有的数据都拥有一份(包括全局变量),不受影响
主要是因为多进程的实质是每个进程在cpu的各个核心上轮流占用,每一时刻在cpu的各个核心上都只有一个进程
2.用multiprocessing来创建多进程
1 from multiprocessing import * 2 import os 3 4 def run_process(num): 5 print("子进程%d--->%d 它的父进程--->%d"%(num,os.getpid(),os.getppid())) 6 7 def main(): 8 # 开始搞5个进程 9 for num in range(5): 10 # Process中常用的的参数有 target 、 args 、 kwargs 、name 其中name意为给这个进程命一个别名,如果不写name参数,则默认为name = Process-N N为一个递增的整数 11 p = Process(target=run_process,args=(num,)) 12 p.start() 13 # p.join() join()的作用是等待子进程结束再往下走,通常用于进程间的同步 14 # join(timeout) join()中可接受一个超时参数,以确定它要等待多少秒的时间 15 16 if __name__ == "__main__": 17 main()
其运行的结果如下:
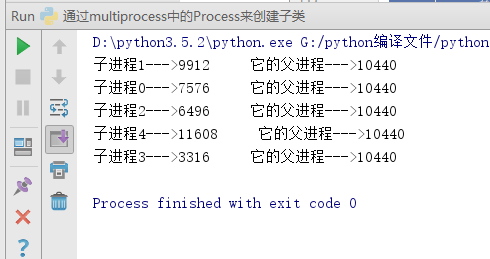
运行结果中子进程的编号并没有遵从for循环中的0,1,2,3,4的顺序是因为子进程的运行是没有顺序而言的,它取决于系统的调度算法
3.通过Process的子类来创建进程
1 from multiprocessing import Process 2 import os 3 4 # 创建一个Process的子类 5 class process_children(Process): 6 def __init__(self, num): 7 # 这里主要是因为Process类中也有__init__方法 8 # 如果不加不写这句话就相当于重写了__init__方法,然而这并不是我们想要的结果 9 # 这句话的作用就是将子类中接收到的参数再传给Process父类 10 Process.__init__(self) 11 self.num = num 12 13 # 这个run方法一定要定义,且必须写成run ,因为这个函数中的代码决定了创建的子进程会怎样执行 14 def run(self): 15 print("%s ---> 当前进程id为%s ,父进程为%s"%(self.num, os.getpid(), os.getppid())) 16 17 def main(): 18 while True: 19 for num in range(5): 20 # 如果我们用Process的子类来创建进程,直接将需要传递的参数传递给类就可以了 21 p = process_children(num) 22 p.start() 23 # p.join() 24 25 if __name__ == "__main__": 26 main()
4.进程池(代码在Ubuntu下测试)
1 from multiprocessing import Pool 2 import os 3 4 def func(num): 5 print("%d---> 当前进程为:%d,它的父进程为:%d"%(num, os.getpid(), os.getppid())) 6 7 #开启一个进程池,池中最大的进程数为3 8 #最大进程数的意思是统一时刻在这个进程池中的最多的进程数量是3 9 #如果进程池中有进程结束,才会为等待的进程创建出新的进程 10 po=Pool(3) 11 12 def main(): 13 for i in range(0,10): 14 # apply_async为非阻塞模式 apply为阻塞模式 15 po.apply_async(func, args=(i,)) 16 print("start") 17 #close一定要放在join的前面 18 po.close() 19 #join的作用是让主进程等待子进程执行完毕 20 po.join() 21 print("finish") 22 23 if __name__ == "__main__": 24 main()
运行结果:
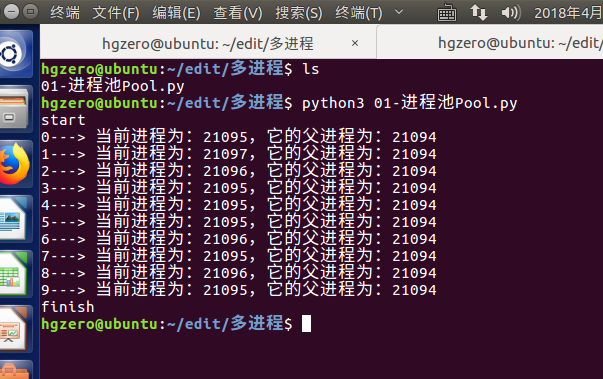
要点:最后的close() 一定要写在join() 的前面
5.进程间的通信------队列Queue
队列:first in first out(FIFO)---------先入先出
栈: first in last out(FILO)----------先入后出
队列的使用:q = Queue(num) num表示队列的最大长度
写入:q.put(value) , q.put_nowait() 读取:q.get() , q.get_nowait()
判断:q.full() , q.empty() , q.qsize()
q.get([block[timeout]])