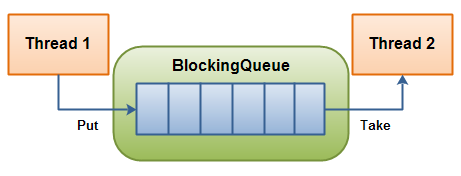
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。
这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
阻塞队列提供了四种处理方法:
| 方法处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
对于 BlockingQueue,我们的关注点应该在 put(e) 和 take() 这两个方法,因为这两个方法是带阻塞的。
- 抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException(“Queue full”)异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。
- 返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null
- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
一、应用
先使用Object.wait()和Object.notify()、非阻塞队列实现生产者-消费者模式:
public class Test { private int queueSize = 10; private PriorityQueue<Integer> queue = new PriorityQueue<Integer>(queueSize); public static void main(String[] args) { Test test = new Test(); Producer producer = test.new Producer(); Consumer consumer = test.new Consumer(); producer.start(); consumer.start(); } class Consumer extends Thread { @Override public void run() { consume(); } private void consume() { while (true) { synchronized (queue) { while (queue.size() == 0) { try { System.out.println("队列空,等待数据"); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); queue.notify(); } } queue.poll(); // 每次移走队首元素 queue.notify(); System.out.println("从队列取走一个元素,队列剩余" + queue.size() + "个元素"); } } } } class Producer extends Thread { @Override public void run() { produce(); } private void produce() { while (true) { synchronized (queue) { while (queue.size() == queueSize) { try { System.out.println("队列满,等待有空余空间"); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); queue.notify(); } } queue.offer(1); // 每次插入一个元素 queue.notify(); System.out.println("向队列取中插入一个元素,队列剩余空间:" + (queueSize - queue.size())); } } } } }
使用阻塞队列实现的生产者-消费者模式:
public class Test { private int queueSize = 10; private ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<Integer>(queueSize); public static void main(String[] args) { Test test = new Test(); Producer producer = test.new Producer(); Consumer consumer = test.new Consumer(); producer.start(); consumer.start(); } class Consumer extends Thread{ @Override public void run() { consume(); } private void consume() { while(true){ try { queue.take(); System.out.println("从队列取走一个元素,队列剩余"+queue.size()+"个元素"); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Producer extends Thread{ @Override public void run() { produce(); } private void produce() { while(true){ try { queue.put(1); System.out.println("向队列取中插入一个元素,队列剩余空间:"+(queueSize-queue.size())); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
Java线程(十三):BlockingQueue-线程的阻塞队列 BlockingQueue(阻塞队列)详解 中都有应用举例可以参考
二、ArrayBlockingQueue
ArrayBlockingQueue,一个由数组实现的有界阻塞队列。该队列采用FIFO的原则对元素进行排序添加的。
ArrayBlockingQueue 实现并发同步的原理:
读操作和写操作都需要获取到同一个 AQS 独占锁才能进行操作。
如果队列为空,这个时候读操作的线程进入到读线程队列排队,等待写线程写入新的元素,然后唤醒读线程队列的第一个等待线程。
如果队列已满,这个时候写操作的线程进入到写线程队列排队,等待读线程将队列元素移除腾出空间,然后唤醒写线程队列的第一个等待线程。
源码分析:
// 属性 // 用于存放元素的数组 final Object[] items; // 下一次读取操作的位置 int takeIndex; // 下一次写入操作的位置 int putIndex; // 队列中的元素数量 int count; // 以下几个就是控制并发用的同步器 final ReentrantLock lock; private final Condition notEmpty; private final Condition notFull;
put:
public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) // 自旋 队列满时,挂起写线程 notFull.await(); enqueue(e); } finally { lock.unlock(); } } private void enqueue(E x) { final Object[] items = this.items; items[putIndex] = x; if (++putIndex == items.length) putIndex = 0; count++; notEmpty.signal();// 成功插入元素后,唤醒读线程 }
take:
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == 0) // 自旋 队列为空,挂起读线程 notEmpty.await(); return dequeue(); } finally { lock.unlock(); } } private E dequeue() { final Object[] items = this.items; @SuppressWarnings("unchecked") E x = (E) items[takeIndex]; items[takeIndex] = null; if (++takeIndex == items.length) takeIndex = 0; count--; if (itrs != null) itrs.elementDequeued(); notFull.signal();// 成功读出一个元素之后,唤醒写线程 return x; }
三、LinkedBlockingQueue
LinkedBlockingQueue底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。
// 无界队列 public LinkedBlockingQueue() { this(Integer.MAX_VALUE); } // 有界队列
//注意,这里会初始化一个空的头结点,那么第一个元素入队的时候,队列中就会有两个元素。读取元素时,也总是获取头节点后面的一个节点。count 的计数值不包括这个头节点。 public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node<E>(null); } // 队列容量 private final int capacity; // 队列中的元素数量 private final AtomicInteger count = new AtomicInteger(0); // 队头 private transient Node<E> head; // 队尾 private transient Node<E> last; // take, poll, peek 等读操作的方法需要获取到这个锁 private final ReentrantLock takeLock = new ReentrantLock(); // 如果读操作的时候队列是空的,那么等待 notEmpty 条件 private final Condition notEmpty = takeLock.newCondition(); // put, offer 等写操作的方法需要获取到这个锁 private final ReentrantLock putLock = new ReentrantLock(); // 如果写操作的时候队列是满的,那么等待 notFull 条件 private final Condition notFull = putLock.newCondition();
原理:
这里用了两个锁,两个 Condition
takeLock 和 notEmpty 怎么搭配:如果要获取(take)一个元素,需要获取 takeLock 锁,但是获取了锁还不够,如果队列此时为空,还需要队列不为空(notEmpty)这个条件(Condition)。
putLock 需要和 notFull 搭配:如果要插入(put)一个元素,需要获取 putLock 锁,但是获取了锁还不够,如果队列此时已满,还需要队列不是满的(notFull)这个条件(Condition)。
put():
public void put(E e) throws InterruptedException { if (e == null) throw new NullPointerException(); // 如果你纠结这里为什么是 -1,可以看看 offer 方法。这就是个标识成功、失败的标志而已。 int c = -1; Node<E> node = new Node(e); final ReentrantLock putLock = this.putLock; final AtomicInteger count = this.count; // 必须要获取到 putLock 才可以进行插入操作 putLock.lockInterruptibly(); try { // 如果队列满,等待 notFull 的条件满足。 while (count.get() == capacity) { notFull.await(); } // 入队 enqueue(node); // count 原子加 1,c 还是加 1 前的值 c = count.getAndIncrement(); // 如果这个元素入队后,还有至少一个槽可以使用,调用 notFull.signal() 唤醒等待线程。 // 哪些线程会等待在 notFull 这个 Condition 上呢? if (c + 1 < capacity) notFull.signal(); } finally { // 入队后,释放掉 putLock putLock.unlock(); } // 如果 c == 0,那么代表队列在这个元素入队前是空的(不包括head空节点), // 那么所有的读线程都在等待 notEmpty 这个条件,等待唤醒,这里做一次唤醒操作 if (c == 0) signalNotEmpty(); } // 入队的代码非常简单,就是将 last 属性指向这个新元素,并且让原队尾的 next 指向这个元素 // 这里入队没有并发问题,因为只有获取到 putLock 独占锁以后,才可以进行此操作 private void enqueue(Node<E> node) { // assert putLock.isHeldByCurrentThread(); // assert last.next == null; last = last.next = node; } // 元素入队后,如果需要,调用这个方法唤醒读线程来读 private void signalNotEmpty() { final ReentrantLock takeLock = this.takeLock; takeLock.lock(); try { notEmpty.signal(); } finally { takeLock.unlock(); } }
take():
public E take() throws InterruptedException { E x; int c = -1; final AtomicInteger count = this.count; final ReentrantLock takeLock = this.takeLock; // 首先,需要获取到 takeLock 才能进行出队操作 takeLock.lockInterruptibly(); try { // 如果队列为空,等待 notEmpty 这个条件满足再继续执行 while (count.get() == 0) { notEmpty.await(); } // 出队 x = dequeue(); // count 进行原子减 1 c = count.getAndDecrement(); // 如果这次出队后,队列中至少还有一个元素,那么调用 notEmpty.signal() 唤醒其他的读线程 if (c > 1) notEmpty.signal(); } finally { // 出队后释放掉 takeLock takeLock.unlock(); } // 如果 c == capacity,那么说明在这个 take 方法发生的时候,队列是满的 // 既然出队了一个,那么意味着队列不满了,唤醒写线程去写 if (c == capacity) signalNotFull(); return x; } // 取队头,出队 private E dequeue() { // assert takeLock.isHeldByCurrentThread(); // assert head.item == null; // 之前说了,头结点是空的 Node<E> h = head; Node<E> first = h.next; h.next = h; // help GC // 设置这个为新的头结点 head = first; E x = first.item; first.item = null; return x; } // 元素出队后,如果需要,调用这个方法唤醒写线程来写 private void signalNotFull() { final ReentrantLock putLock = this.putLock; putLock.lock(); try { notFull.signal(); } finally { putLock.unlock(); } }
四、PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界阻塞队列。默认情况下元素采用自然顺序升序排序,当然我们也可以通过构造函数来指定Comparator来对元素进行排序。需要注意的是PriorityBlockingQueue不能保证同优先级元素的顺序。
PriorityBlockingQueue为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容)。
需要注意的是PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。因此使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。
PriorityBlockingQueue底层采用二叉堆来实现。
关于二叉堆: 二叉堆的实现 二叉堆(一)之 图文解析 和 C语言的实现
属性:
// 构造方法中,如果不指定大小的话,默认大小为 11 private static final int DEFAULT_INITIAL_CAPACITY = 11; // 数组的最大容量 private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 这个就是存放数据的数组 private transient Object[] queue; // 队列当前大小 private transient int size; // 大小比较器,如果按照自然序排序,那么此属性可设置为 null private transient Comparator<? super E> comparator; // 并发控制所用的锁,所有的 public 且涉及到线程安全的方法,都必须先获取到这个锁 private final ReentrantLock lock; // 这个很好理解,其实例由上面的 lock 属性创建 private final Condition notEmpty; // 这个也是用于锁,用于数组扩容的时候,需要先获取到这个锁,才能进行扩容操作 // 其使用 CAS 操作 private transient volatile int allocationSpinLock; // 用于序列化和反序列化的时候用,对于 PriorityBlockingQueue 我们应该比较少使用到序列化 private PriorityQueue q;
put():
public void put(E e) { offer(e); // never need to block } public boolean offer(E e) { // 不能为null if (e == null) throw new NullPointerException(); // 获取锁 final ReentrantLock lock = this.lock; lock.lock(); int n, cap; Object[] array; // 扩容 while ((n = size) >= (cap = (array = queue).length)) tryGrow(array, cap); try { Comparator<? super E> cmp = comparator; // 根据比较器是否为null,做不同的处理 if (cmp == null) siftUpComparable(n, e, array); else siftUpUsingComparator(n, e, array, cmp); size = n + 1; // 唤醒正在等待的消费者线程 notEmpty.signal(); } finally { lock.unlock(); } return true; }
take():
public E poll() { final ReentrantLock lock = this.lock; lock.lock(); try { return dequeue(); } finally { lock.unlock(); } } private E dequeue() { // 没有元素 返回null int n = size - 1; if (n < 0) return null; else { Object[] array = queue; // 出对元素 E result = (E) array[0]; // 最后一个元素(也就是插入到空穴中的元素) E x = (E) array[n]; array[n] = null; // 根据比较器释放为null,来执行不同的处理 Comparator<? super E> cmp = comparator; if (cmp == null) siftDownComparable(0, x, array, n); else siftDownUsingComparator(0, x, array, n, cmp); size = n; return result; } }
五、DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列。
队列使用PriorityQueue来实现。
队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。
里面的元素全部都是“可延期”的元素,列头的元素是最先“到期”的元素,如果队列里面没有元素到期,是不能从列头获取元素的,哪怕有元素也不行。也就是说只有在延迟期到时才能够从队列中取元素。
DelayQueue应用场景:
- 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
- 定时任务调度。使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。
队列中的Delayed必须实现compareTo来指定元素的顺序。比如让延时时间最长的放在队列的末尾。实现代码如下:
public int compareTo(Delayed other) { if (other == this) // compare zero ONLY if same object return 0; if (other instanceof ScheduledFutureTask) { ScheduledFutureTask x = (ScheduledFutureTask)other; long diff = time - x.time; if (diff < 0) return -1; else if (diff > 0) return 1; else if (sequenceNumber < x.sequenceNumber) return -1; else return 1; } long d = (getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS)); return (d == 0) ? 0 : ((d < 0) ? -1 : 1); }
六、SynchronousQueue
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。
SynchronousQueue 的队列其实是虚的,其不提供任何空间(一个都没有)来存储元素。数据必须从某个写线程交给某个读线程,而不是写到某个队列中等待被消费。
当一个线程往队列中写入一个元素时,写入操作不会立即返回,需要等待另一个线程来将这个元素拿走;同理,当一个读线程做读操作的时候,同样需要一个相匹配的写线程的写操作。这里的 Synchronous 指的就是读线程和写线程需要同步,一个读线程匹配一个写线程。
SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景,比如在一个线程中使用的数据,传递给另外一个线程使用。
// 构造时,我们可以指定公平模式还是非公平模式,区别之后再说 public SynchronousQueue(boolean fair) { transferer = fair ? new TransferQueue() : new TransferStack(); } abstract static class Transferer { // 从方法名上大概就知道,这个方法用于转移元素,从生产者手上转到消费者手上 // 也可以被动地,消费者调用这个方法来从生产者手上取元素 // 第一个参数 e 如果不是 null,代表场景为:将元素从生产者转移给消费者 // 如果是 null,代表消费者等待生产者提供元素,然后返回值就是相应的生产者提供的元素 // 第二个参数代表是否设置超时,如果设置超时,超时时间是第三个参数的值 // 返回值如果是 null,代表超时,或者中断。具体是哪个,可以通过检测中断状态得到。 abstract Object transfer(Object e, boolean timed, long nanos); }
我们来看看 transfer 的设计思路,其基本算法如下:
- 当调用这个方法时,如果队列是空的,或者队列中的节点和当前的线程操作类型一致(如当前操作是 put 操作,而队列中的元素也都是写线程)。这种情况下,将当前线程加入到等待队列即可。
- 如果队列中有等待节点,而且与当前操作可以匹配(如队列中都是读操作线程,当前线程是写操作线程,反之亦然)。这种情况下,匹配等待队列的队头,出队,返回相应数据。
其实这里有个隐含的条件被满足了,队列如果不为空,肯定都是同种类型的节点,要么都是读操作,要么都是写操作。这个就要看到底是读线程积压了,还是写线程积压了。
put 方法和 take 方法:
// 写入值 public void put(E o) throws InterruptedException { if (o == null) throw new NullPointerException(); if (transferer.transfer(o, false, 0) == null) { // 1 Thread.interrupted(); throw new InterruptedException(); } } // 读取值并移除 public E take() throws InterruptedException { Object e = transferer.transfer(null, false, 0); // 2 if (e != null) return (E)e; Thread.interrupted(); throw new InterruptedException(); }
节点:
static final class QNode { volatile QNode next; // 可以看出来,等待队列是单向链表 volatile Object item; // CAS'ed to or from null volatile Thread waiter; // 将线程对象保存在这里,用于挂起和唤醒 final boolean isData; // 用于判断是写线程节点(isData == true),还是读线程节点 QNode(Object item, boolean isData) { this.item = item; this.isData = isData; } ......
transfer 方法:
Object transfer(Object e, boolean timed, long nanos) { QNode s = null; // constructed/reused as needed boolean isData = (e != null); for (;;) { QNode t = tail; QNode h = head; if (t == null || h == null) // saw uninitialized value continue; // spin // 队列空,或队列中节点类型和当前节点一致, // 即我们说的第一种情况,将节点入队即可。读者要想着这块 if 里面方法其实就是入队 if (h == t || t.isData == isData) { // empty or same-mode QNode tn = t.next; // t != tail 说明刚刚有节点入队,continue 即可 if (t != tail) // inconsistent read continue; // 有其他节点入队,但是 tail 还是指向原来的,此时设置 tail 即可 if (tn != null) { // lagging tail // 这个方法就是:如果 tail 此时为 t 的话,设置为 tn advanceTail(t, tn); continue; } // if (timed && nanos <= 0) // can't wait return null; if (s == null) s = new QNode(e, isData); // 将当前节点,插入到 tail 的后面 if (!t.casNext(null, s)) // failed to link in continue; // 将当前节点设置为新的 tail advanceTail(t, s); // swing tail and wait // 看到这里,请读者先往下滑到这个方法,看完了以后再回来这里,思路也就不会断了 Object x = awaitFulfill(s, e, timed, nanos); // 到这里,说明之前入队的线程被唤醒了,准备往下执行 if (x == s) { // wait was cancelled clean(t, s); return null; } if (!s.isOffList()) { // not already unlinked advanceHead(t, s); // unlink if head if (x != null) // and forget fields s.item = s; s.waiter = null; } return (x != null) ? x : e; // 这里的 else 分支就是上面说的第二种情况,有相应的读或写相匹配的情况 } else { // complementary-mode QNode m = h.next; // node to fulfill if (t != tail || m == null || h != head) continue; // inconsistent read Object x = m.item; if (isData == (x != null) || // m already fulfilled x == m || // m cancelled !m.casItem(x, e)) { // lost CAS advanceHead(h, m); // dequeue and retry continue; } advanceHead(h, m); // successfully fulfilled LockSupport.unpark(m.waiter); return (x != null) ? x : e; } } } void advanceTail(QNode t, QNode nt) { if (tail == t) UNSAFE.compareAndSwapObject(this, tailOffset, t, nt);
// 自旋或阻塞,直到满足条件,这个方法返回 Object awaitFulfill(QNode s, Object e, boolean timed, long nanos) { long lastTime = timed ? System.nanoTime() : 0; Thread w = Thread.currentThread(); // 判断需要自旋的次数, int spins = ((head.next == s) ? (timed ? maxTimedSpins : maxUntimedSpins) : 0); for (;;) { // 如果被中断了,那么取消这个节点 if (w.isInterrupted()) // 就是将当前节点 s 中的 item 属性设置为 this s.tryCancel(e); Object x = s.item; // 这里是这个方法的唯一的出口 if (x != e) return x; // 如果需要,检测是否超时 if (timed) { long now = System.nanoTime(); nanos -= now - lastTime; lastTime = now; if (nanos <= 0) { s.tryCancel(e); continue; } } if (spins > 0) --spins; // 如果自旋达到了最大的次数,那么检测 else if (s.waiter == null) s.waiter = w; // 如果自旋到了最大的次数,那么线程挂起,等待唤醒 else if (!timed) LockSupport.park(this); // spinForTimeoutThreshold 这个之前讲 AQS 的时候其实也说过,剩余时间小于这个阈值的时候,就 // 不要进行挂起了,自旋的性能会比较好 else if (nanos > spinForTimeoutThreshold) LockSupport.parkNanos(this, nanos); } }
七、LinkedTransferQueue
BlockingQueue对读或者写都是锁上整个队列,在并发量大的时候,各种锁是比较耗资源和耗时间的,而前面的SynchronousQueue虽然不会锁住整个队列,但它是一个没有容量的“队列”。
LinkedTransferQueue是ConcurrentLinkedQueue、SynchronousQueue (公平模式下)、无界的LinkedBlockingQueues等的超集。即可以像其他的BlockingQueue一样有容量又可以像SynchronousQueue一样不会锁住整个队列
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于LinkedTransferQueue多了tryTransfer和transfer方法。
transfer方法:如果当前有消费者正在等待接收元素(消费者使用take()方法或带时间限制的poll()方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail节点,并等到该元素被消费者消费了才返回。transfer方法的关键代码如下:
Node pred = tryAppend(s, haveData);
return awaitMatch(s, pred, e, (how == TIMED), nanos);
第一行代码是试图把存放当前元素的s节点作为tail节点。第二行代码是让CPU自旋等待消费者消费元素。因为自旋会消耗CPU,所以自旋一定的次数后使用Thread.yield()方法来暂停当前正在执行的线程,并执行其他线程。
tryTransfer方法:则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。和transfer方法的区别是tryTransfer方法无论消费者是否接收,方法立即返回。而transfer方法是必须等到消费者消费了才返回。
源码分析:【死磕Java并发】—–J.U.C之阻塞队列:LinkedTransferQueue
八、LinkedBlockingDeque
LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。
双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque多了addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast等方法。
在初始化LinkedBlockingDeque时可以初始化队列的容量,用来防止其再扩容时过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式中。
源码分析:【死磕Java并发】—–J.U.C之阻塞队列:LinkedBlockingDeque
参考资料 / 相关推荐:
【死磕Java并发】—–J.U.C之阻塞队列:ArrayBlockingQueue