本节内容:
1:理解关联分析及专业名词
2:关联分析指定数据结构-->transactions(事务结构)
3:关联分析规则规定流程
4:R代码实现规则
一、理解关联分析及专业名词
1.1:什么是关联分析:
有一个非常有名的故事:"尿布和啤酒"。故事是这样的:美国的妇女们经常会嘱咐她们的丈夫 下班后为孩子买尿布,而丈夫在买完尿布后又要顺 手买回自己爱喝的啤酒,因此啤酒和尿布在 一起被购买的机会很多。这个举措使尿布和啤酒的销量双双增加,并一直为众商家所津津乐道。 我们从中会有疑问?为什么尿布和啤酒放在一起就提升销量呢? 如何去发现尿布和啤酒之间的关系就是我们要讲的关联分析
1.2:要进行关联分析要用什么方法?
Apriori algorithm是关联规则里一项基本算法。
是由Rakesh Agrawal和Ramakrishnan Srikant两位博士在1994年提出的关联规则挖掘算法。 关联规则的目的就是在一个数据集中找出项与项之间的关系,
也被称为购物蓝分析 (Market Basket analysis),因为“购物蓝分析”很贴切的表达了适用该算法情景中的一个子集。
我们将每一个顾客购买的购物蓝中物品称之为项,而购物篮的物品集合就叫做项集,这一次购买的东西的行为叫做事务
1.3:专业名词
支持度(Support):定 义为 supp(X) = occur(X) / count(D) = P(X)。
1. 解释一:比如选秀比赛,那个支持和这个有点类似,那么多人(资料库),其中有多少人是选择(支持)你的,那个就是支持度; 2. 解释二:在100个人去超市买东西的,其中买苹果的有9个人,那就是说苹果在这里的支持度是 9,9/100; 3. 解释三:P(X),意思是事件X出现的概率; 4. 解释四:关联规则当中是有绝对支持度(个数)和相对支持度(百分比)之分的。
置信度(Confidence/Strength): 定义为 conf(X->Y) = supp(X ∪ Y) / supp(X) = P(Y|X)。
买A的支持度是0.8 买B的支持度是0.6 同时买A和B的支持度是0.4 那么我们求A对B的置信度 = 0.4 / 0.8 = 0.5 ##求是说够买了A之后那么再购买B的成功率是0.5,而原本B的支持度是0.6,那么在后面的算法我们就不会生成这个关联规则
支持度(提升度Lift)
通过置信度A对B的支持度 = 0.5 / 0.6 =0.83 ##这说明支持度降低,不应该把A和B放在一起进行销售
频繁集
我们指定支持度为(0.25)那么项集从1到n的项集 > 0.25就叫做频繁集。 当购物车有2个商品:叫做2项集 当购物车有3个商品:叫做3项集
二、关联分析指定数据结构-->(事务结构)
要进行关联分析那么其数据集的数据结构必须为transactions(事务结构)。
library(arules)
library(gridBase)
tr_list = list(
c("Bread","Milk"),
c("Bread","Beer","Milk"),
c("Eggs","Beer","DR")
)
##重命名
names(tr_list) = paste("tr",c(1:3),sep = "")
summary(tr_list)
##变成事务类型
#使用as函数,将链表转化为事务类型
trans = as(tr_list,"transactions")
如何查看事务类型的属性
##展现事务 LIST(trans) ##查看事务数据 inspect(trans) image(trans) ##可视化查看事务 trans@data size(trans) #每个事务中包含多少项 filter_trans = trans[size(trans)>=3] ##筛选出事务中项数大于等于3的事务 summary(filter_trans)

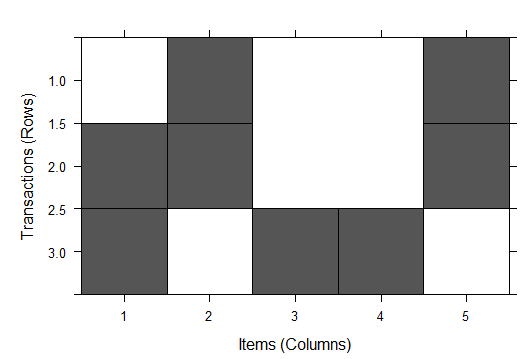
三、关联分析规则规定流程

从1项集到N项集,求出各个项集的支持度,我们指定支持度的阈值为(0.25),当支持度小于0.25,我们就
将其项集删除。然后就出各个的置信度和提升度判定是否要生成规则
支持度: Beer = 0.6 Bread=0.8 Coke=0.4 Diaper = 0.8 Mike=0.8 置信度: Be,Br = 0.4 求置信度Be:Be和Br都发生的概率是0.4,原本购买Br的概率是0.8 所以0.4/0.8=0.5 就是说,够买了Br之后那么再购买Be的成功率是0.5 那么原本购买Be的0.6 变成了 0.5,所以就生成不了这个规则。 提升度: 0.5/0.6 = 0.83 购买Be提升度降低
四、R代码实现规则
1:实现:事务转换、查看事务数据
library(arules)
library(gridBase)
install.packages("arulesViz")
library(arulesViz)
tr_list = list(
c("Bread","Milk"),
c("Bread","Beer","Diaper","Eggs"),
c("Milk","Diaper","Beer","Coke"),
c("Bread","Milk","Diaper","Beer"),
c("Bread","Milk","Diaper","Coke")
)
names(tr_list) = paste("tr",c(1:5),sep = "")
summary(tr_list)
##变成事务类型
#使用as函数,将链表转化为事务类型
trans = as(tr_list,"transactions")
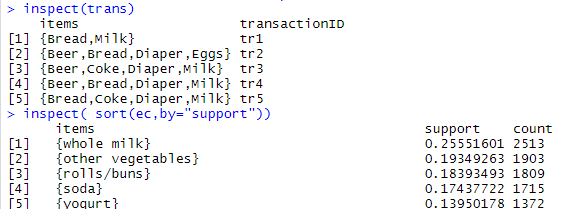
inspect(trans)
2:实现:查看单项集的支持度,还有经过支持度的筛选得到的多项集的支持度
##查看支持度 ac = itemFrequency(trans,type="relative") summary(ac) ec = eclat(trans,parameter = list(support=0.25,maxlen=5)) #找到所有项集 支持度大于0.25的,maxlen[最大项集是几项] summary(ec) inspect( sort(ec,by="support")) #查看各个项集的支持度,按支持度排序
3:实现规则
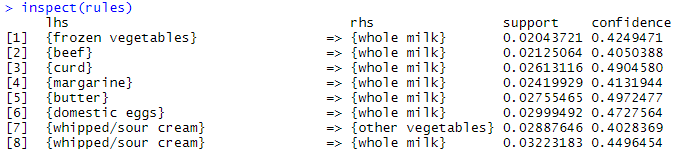
##-----------------生成规则,--------------- #conf = 0.5[置信度要大于0.5也就是起码不能是靠猜的买还是不买] rules = apriori(trans,parameter = list(supp=0.25,conf=0.5,target="rules")) inspect(rules) summary(rules) #对规则的置信度进行排序 rules.sorted = sort(rules,by="confidence",decreasing = T) inspect(rules.sorted)
##去重复规则 is_redun = is.redundant(rules.sorted) trans_punds = rules.sorted[!is_redun] inspect(trans_punds)
4:单独针对Milk的规则
#买Milk的人 我们要怎么做推荐
mike_rules = apriori(trans,parameter = list(supp=0.2,conf=0.5,minlen=2),
appearance = list(default="rhs",lhs="Milk"))
inspect(mike_rules)
plot(mike_rules,by="lift",main="milk_rule by lift",method="graph",
control=list(type="items"))
##买了什么产品会推荐Mike,rhs=>右边是milk
mike_rules_r = apriori(trans,parameter = list(supp=0.2,conf=0.5,minlen=3),
appearance = list(default="lhs",rhs="Milk"))
plot(mike_rules_r,by="lift",main="milk_rule by lift",method="graph",
control=list(type="items"))
plot(c(rules.sorted,mike_rules_r),mian="RHS_milk rules")
##绘制关联规则的气球图 #两个以上才能图画出来

