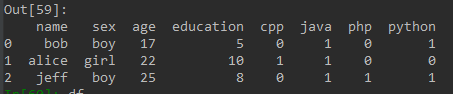
在处理数据的时候偶尔会遇到特征维如下情况:
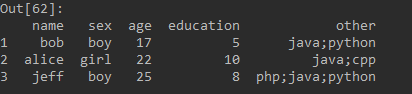
可以将other维中的以分号分隔的词转化为词向量的形式:
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer df = pd.read_csv("data.txt",index_col=0) df['other'] = df['other'].apply(lambda x: ' '.join(x.split(';'))) cv = CountVectorizer() other_list = cv.fit_transform(df['other']) df1 = pd.DataFrame(other_list.toarray(), columns = cv.get_feature_names()) df = df.reset_index(drop = True) df_tmp = df.drop('other', axis=1) df_final = df_tmp.join(df1)
最终得到结果: