最近迷上一本小说,但是要收费,后来就想用爬虫把书籍进行获取,
但是这个网址使用的gbk编码,获取的数据全是乱码,经过好几个小时的研究终于找到方法了,后来进行了整理。
一:查看网站具体编码格式
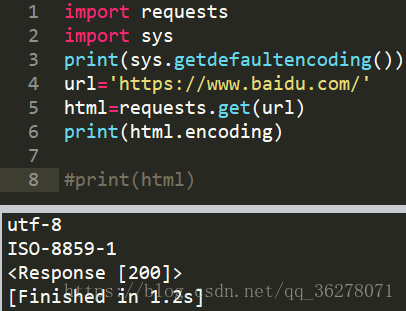
得到编码格式之后,就好解决问题了。就编写了如下代码
#!/usr/bin/env python
# coding=utf-8
from lxml import etree
import requests
# 指定URL
url = "https://www.sangwu.org/book/"
# 伪装UA
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
# 发送请求方式
page_text = requests.get(url=url,headers=headers).text
# 重点 先把gbk进行编码(encode),在解码(decode)
page_text = page_text.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(page_text)[0])
tree = etree.HTML(page_text)
dd_list = tree.xpath('//div[@class="main"]/dl/dd')
fp = open('book.txt',mode='a',encoding='utf-8')
for i in dd_list:
i_url = i.xpath('a/@href')[0] # 获取url
title = i.xpath('a/text()')[0] # 获取标签
# print(i_url,title)
new_url = url + i_url # 拼接新的URL
html = requests.get(url=new_url).text
a = html.encode('ISO-8859-1').decode(requests.utils.get_encodings_from_content(html)[0])
ret_tree = etree.HTML(a)
book = ret_tree.xpath('//div[@class="centent"]/text()')
fp.write(title + '
')
print(title)
for i in book:
a = i.replace("
", "")
fp.write(a)
# print(a)
print("over !!!")
fp.close()