Elasticsearch基础Api:
大家一定是使用过关系型数据库的,那么我们现在从关系型数据库的概念扩展讲解一下ES对应关系型数据库的内容
对应关系表
Elasticsearch => MySQL
索引库(indices) => Database 数据库
类型(type) => Table 数据表
文档(Document) => Row 行
域字段(Field) => Columns 列
映射配置(mappings) => 每个列的约束(类型、长度)
知识点思维导图
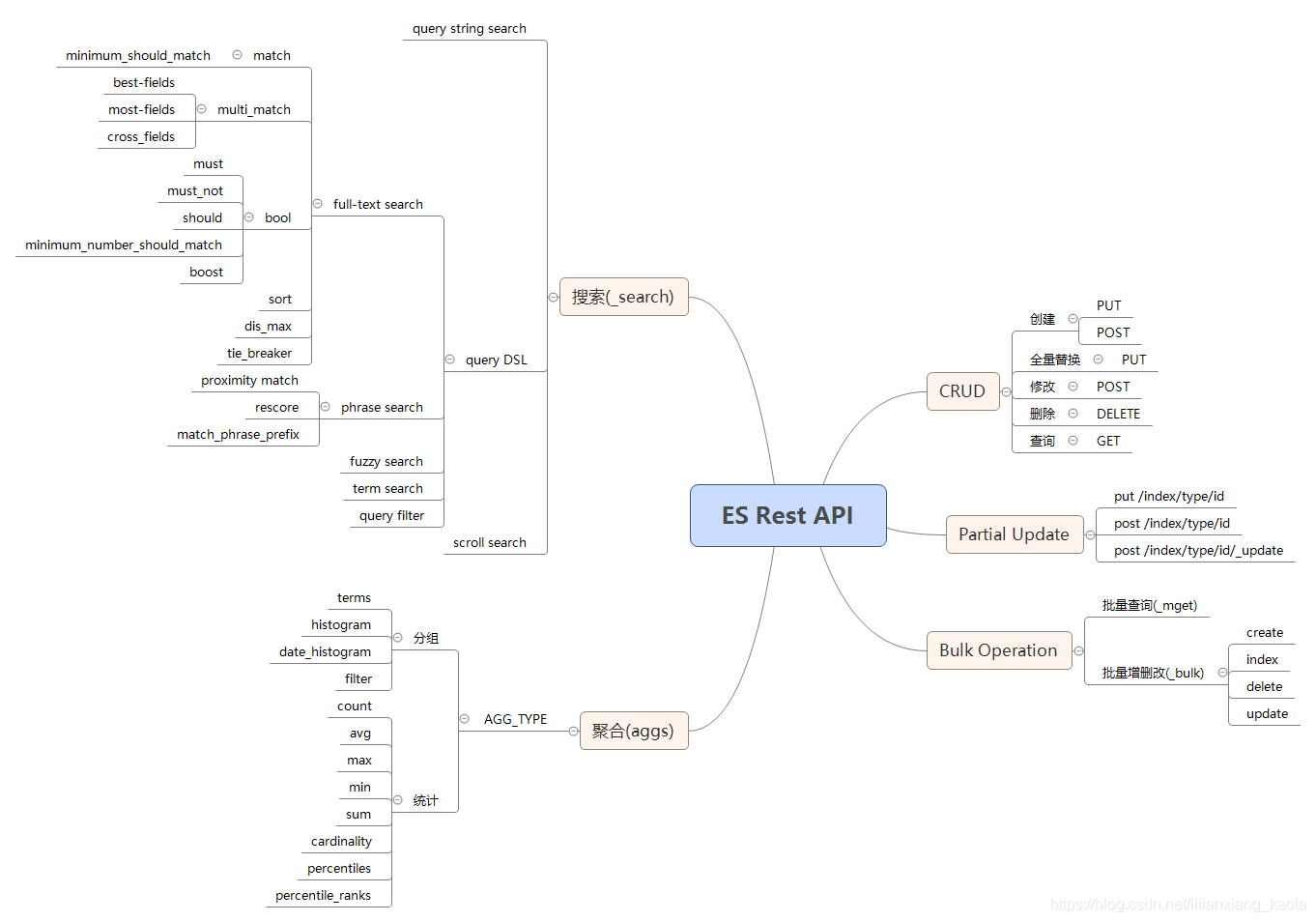
基础增删改查
语法
(1) 创建/全量替换
记录不存在就是创建, 否则是全量替换.
PUT /index/type/id { "属性名" : "value" ... }
(2) 创建/修改创建
//如果不传id, 则系统自动生成一个UUID POST /index/type/ { "属性名":修改值 } 或者 POST /index/type/id { "属性名":修改值 }
修改
//没有带上的属性会被清除 POST /index/type/id { "属性名":修改值 }
(3) 查询
GET /index/type/id
(4) 删除
只是逻辑删除, 将其标记为delete, 当数据越来越多时, ES会自动物理删除
DELETE /index/type/id
实例
(1) 新增
PUT /company/employee/1 { "age":25, "salary":"20k", "skill":["java","mysql","es"] }
或者
POST /company/employee { "age":30, "salary":"30k", "skill":["python","redis","hadoop"] }
POST /company/employee/2
{ "age":22, "salary":"10k", "skill":["python","java"] }
POST 命令新增数据时, 如果不传id, 则系统自动生成一个UUID.
(2) 查询
GET /company/employee/1
(3) 修改
POST /company/employee/1 { "age":40, "salary":"100k" }
或
PUT /company/employee/1 { "age":18, "salary":"50K", "skill":["c++"] }
PUT 是全量替换, 且是幂等操作. 上面的POST修改, skill属性被清除了, 属性现在只有age和salary.
幂等操作: GET, PUT, DELETE都是幂等操作, 执行多次与执行一次结果一样.
(4) 删除
DELETE /company/employee/1
Partial Update
部分更新.
(1) 语法
post /index/type/id/_update { "doc": { "属性名" : "value" ... } }
2) 与全量替换和普通修改的区别
在应用程序中, 全量替换是先从ES中查询出记录, 然后在修改, 一个属性都不能少. 而部分更新就不用先从ES查询记录了, 可以直接修改, 且不用所有属性都列出.
部分更新如果只包含部分属性, 那么其他没有被包含的属性仍然存在, 但普通修改其他没有被包含的属性就直接清除了.
(3) 实例
a. 先添加一条数据
PUT /school/student/1 { "name": "alice", "age": 17 }
b. 测试部分更新
//部分更新 POST /school/student/1/_update { "doc": { "name" : "Tom" } } //查询 GET /school/student/1 //结果 { "_index": "school", "_type": "student", "_id": "1", "_version": 7, "found": true, "_source": { "name": "Tom", "age": 17 } }
c. 测试普通修改
//普通修改 POST /school/student/1 { "name" : "Linda" } //查询 GET school/student/1 //结果 { "_index": "school", "_type": "student", "_id": "1", "_version": 8, "found": true, "_source": { "name": "Linda" } }
Bulk Operation
批量查询和批量增删改的语法不同, 所以分开来介绍.
批量查询
GET /_mget { "docs" : [ { "_index" : "company", "_type" : "employee", "_id" : 1 }, { "_index" : "company", "_type" : "employee", "_id" : 2 } ] } GET /company/_mget { "docs" : [ { "_type" : "employee", "_id" : 1 }, { "_type" : "employee", "_id" : 2 } ] } GET /company/employee/_mget { "ids" : [1,2] }
批量增删改
(1) 语法
每一个操作要两个json串,语法如下:
POST /index/type/_bulk {"action": {"metadata"}} {"data"}
ndex和type可以放入metadata中. 每个json串不能换行, 只能放一行. 同时一个json串和一个json串之间, 必须有一个换行.
(2) action类型
delete 删除.
create 强制创建. PUT /index/type/id/_create
index 创建或替换.
update 属于部分更新.
(3) 实例
POST /_bulk {"delete" : {"_index":"company", "_type":"employee","_id":"1"}}
{"create" :{"_index":"company","_type":"employee","_id":"2"}} {"name":"tyshawn", "age":18}
{"index":{"_index":"company","_type":"employee","_id":"3"}} {"name":"lee", "age":24}
{"update":{"_index":"company","_type":"employee","_id":"2"}} {"doc":{"age":30}}
搜索
添加搜索实例数据.
PUT /website/article/1 { "post_date": "2017-01-01", "title": "my first article", "content": "this is my first article in this website", "author_id": 11401, "tags": [ "java", "c" ] } PUT /website/article/2 { "post_date": "2017-01-02", "title": "my second article", "content": "this is my second article in this website", "author_id": 11402, "tags": [ "redis", "linux" ] } PUT /website/article/3 { "post_date": "2017-01-03", "title": "my third article", "content": "this is my third article in this website", "author_id": 11403, "tags": [ "elaticsearch", "kafka" ] }
mapping结构如下:
GET /website/_mapping/article { "website": { "mappings": { "article": { "properties": { "author_id": { "type": "long" }, "content": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "post_date": { "type": "date" }, "tags": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } } } }
当type = text时, ES默认会设置两个field, 一个分词, 一个不分词. 如content会分词, 而content.keyword不分词, content.keyword最多保留256个字符.
通用语法
(1) 搜索所有index数据.
GET /_search
(2) 搜索指定index, type下的数据(index和type可以有多个)
GET /index1/_search GET /index1,index2/_search GET /index1/type1/_search GET /index1/type1,type2/_search GET /index1,index2/type1,type2/_search
(3) 搜索所有index下的指定type的数据.
GET /_all/employee,product/_search
下面再介绍Elasticsearch搜索的条件语法.
query string search
这个查询就类似于HTTP里的GET请求, 参数放在URL上.
(1) 语法
GET /index/type/_search?q=属性名:属性值 GET /index/type/_search?q=+属性名:属性值 GET /index/type/_search?q=-属性名:属性值 也可以省略属性名, 直接q=属性值 GET /index/type/_search?q=属性值
(2) + 和 - 的区别
默认是+, 指必须包含该字段, - 指不包含该字段.
(3) 实例
GET /website/article/_search?q=author_id:11403 GET /website/article/_search?q=-author_id:11403 GET /website/article/_search?q=11403
(4) _all metadata的原理
GET /index/type/_search?q=属性值.
这个语句是从所有属性中搜索包含指定的关键字的数据. 那么ES在搜索时是遍历所有document中的每一个field吗? 不是的, 我们在插入一条document时, ES会自动将多个field的值, 全部用字符串的方式串联起来, 变成一个长的字符串(以空格作为分隔符),作为_all field的值,同时进行分词建立倒排索引. 如果在搜索时没有指定属性名, 就会默认搜索_all field. (生产环境不使用)
query DSL
DSL, Domain Specified Language,特定领域的语言. 这个查询就类似于HTTP里的POST请求, 参数放在body中.
实例: 从website索引中查询所有文章
GET /website/article/_search { "query": { "match_all": {} } }
full-text search
全文搜索.
(1) 基础使用
a. 搜索标题中包含first或second的文章
GET /website/article/_search { "query": { "match": { "title": "first second" } } } 或者 GET /website/article/_search { "query": { "match": { "title": { "query": "first second" , "operator": "or" } } } } 或者 GET /website/article/_search { "query": { "bool": { "should": [ {"match": { "title":"first" }}, {"match": { "title":"second" }} ] } } }
b. 搜索标题中包含first和second的文章
GET /website/article/_search { "query": { "match": { "title": { "query": "first second" , "operator": "and" } } } } 或者 GET /website/article/_search { "query": { "bool": { "must": [ {"match": { "title": "first" }}, {"match": { "title": "second" }} ] } } }
c. 搜索标题中至少包含first, second, third, fourth中三个单词的文章.
GET /website/article/_search { "query": { "match": { "title": { "query": "first second third fourth", "minimum_should_match": "75%" } } } } 或者 GET /website/article/_search { "query": { "bool": { "should": [ {"match": { "title": "first" }}, {"match": { "title": "second" }}, {"match": { "title": "third" }}, {"match": { "title": "fourth" }} ], "minimum_number_should_match": 3 } } }
d. 从website索引中查询, 标题必须包含elasticsearch,内容可以包含elasticsearch也可以不包含,作者id必须不为111.
GET /website/article/_search { "query": { "bool": { "must": [ { "match": { "title":"elasticsearch" } } ], "should": [ { "match": { "content":"elasticsearch" } } ], "must_not": [ { "match": { "author_id":"111" } } ] } } }
e. 从website索引中查询, 标题包含first, 同时按作者id降序排序
GET /website/article/_search { "query": { "match": { "title": "first" } }, "sort": [ { "author_id": { "order": "desc" } } ] }
f. 从website索引中分页查询,总共3篇文章,假设每页就显示1篇文章,现在显示第2页
GET /website/article/_search { "query": { "match_all": {} }, "from": 1, "size": 1 }
g. 从website索引中查询所有文章, 只显示post_date, title两个属性.
GET /website/article/_search { "query": { "match_all": {} }, "_source": ["post_date","title"] }
h. 搜索标题中包含 article 的文章, 如果标题中包含first或second就优先搜索出来, 同时, 如果一个文章标题包含first article, 另一个文章标题包含second article, 包含first article的文章要优先搜索出来.
//通过加权重来处理, 默认权重为1 GET /website/article/_search { "query": { "bool": { "must": [ {"match": { "title": "article" }} ], "should": [ {"match": { "title": { "query": "first", "boost" : 3 } }}, {"match": { "title": { "query": "second", "boost": 2 } }} ] } } }
(2) multi_match
multi_match 用于查询词匹配多个属性. 这里涉及到几种匹配策略:
best-fields
doc的某个属性匹配尽可能多的关键词, 那么这个doc会优先返回.
most-fields
某个关键词匹配doc尽可能多的属性, 那么这个doc会优先返回.
cross_fields
跨越多个field搜索一个关键词.
best-fields和most-fields的区别:
比如, doc1的field1匹配的三个关键词, doc2的field1, field2都匹配上了同一个关键词. 如果是best-fields策略, 则doc1的相关度分数要更高, 如果是most-fields策略, 则doc2的相关度分数要更高.
实例:
a. 使用best_fields策略, 从title和content中搜索"my third article".
GET /website/article/_search { "query": { "multi_match": { "query": "my third article", "type": "best_fields", "fields": ["title","content"] } } }
b. 从title和content中搜索"my third article", 且这三个单词要连在一起.
GET /website/article/_search { "query": { "multi_match": { "query": "my third article", "type": "cross_fields", "operator": "and", "fields": ["title","content"] } } }
3) dis_max
在我们进行多个条件的全文搜索时, 最后的计算出的相关度分数是根据多个条件的匹配分数综合而来的, 比如score = (score1 + score2) / 2, 如果我们想让最终的相关度分数等于多个条件匹配分数中的最大值, 即score = max(score1, score2), 则可以使用dis_max.
实例: 搜索title或content中包含first或article的文章
GET /website/article/_search { "query": { "bool": { "should": [ { "match": { "title": "first article" } }, { "match": { "content": "first article" } } ] } } }
使用dis_max:
GET /website/article/_search { "query": { "dis_max": { "queries": [ { "match": { "title": "first article" } }, { "match": { "content": "first article" } } ] } } }
(4) tie_breaker
tie_breaker是与dis_max配套使用的. dis_max只取分数最大的那个条件的分数, 完全不考虑其他条件的分数, 但如果在某些场景下也需要考虑其他条件的分数呢? 我们可以指定一个系数值tie_breaker, 将其他条件的分数乘以tie_breaker, 然后和最大分数综合起来计算最终得分.
tie_breaker的取值为 0 ~ 1之间.
a. 将上面的实例优化下:
GET /website/article/_search { "query": { "dis_max": { "tie_breaker": 0.7, "queries": [ { "match": { "title": "first article" } }, { "match": { "content": "first article" } } ] } } }
b. 继续优化. 如果搜索词包含多个关键字, 我们要求至少匹配多个关键词, 且多个条件的权重不同.
GET /website/article/_search { "query": { "dis_max": { "tie_breaker": 0.7, "queries": [ { "match": { "title": { "query": "first article hello world", "minimum_should_match": "50%", "boost": 2 } } }, { "match": { "content": { "query": "first article is my hero", "minimum_should_match": "20%", "boost": 1 } } } ] } } }
phrase search
(1) 短语搜索, 与全文搜索有什么区别呢?
全文搜索会将"查询词"拆解开来, 去倒排索引中一一匹配, 只要能匹配上任意一个拆解后的关键词, 就可以作为结果返回. 而短语搜索在全文搜索的基础上, 要求关键词必须相邻. (注意短语搜索的"查询词"也是会被分词的)
GET /website/article/_search { "query": { "match": { "title": "first article" } } } //三条记录都会搜索出来 GET /website/article/_search { "query": { "match_phrase": { "title": "first article" } } } //只有一条记录
(2) 原理:
短语搜索的原理实际上是相邻匹配(proximity match). Lucene建立的倒排索引结构为: 关键词 -> 文档号, 在文档中的位置, 在文档出现的频率等, 当一个"查询词"包含多个关键词时, Lucene先通过关键词找到对应的文档号, 判断多个关键词所在的文档号是否相同, 然后再判断在文档中的位置是否相邻.
(3) 实例
短语搜索默认是搜索相邻的关键词, 但也可以搜索间隔几个位置的关键词. 间隔越小相关度分数越高.
a. 从content中搜索"first website", first和website必须在同一个doc中, 且间隔不能超过10.
ET /website/article/_search { "query": { "match_phrase": { "content": { "query": "first website", "slop": 10 } } } }
b. 全文搜索和短语搜索配合使用. 从content中搜索"first website", 在优先满足召回率的前提下, 尽可能提高精准度.
召回率: 从n个doc中搜索, 有多少个doc返回.
精准度: 让两个关键词间隔越小的doc相关度分数越高.
GET /website/article/_search { "query": { "bool": { "must": [ { "match": { "content": "first website" } } ], "should": [ { "match_phrase": { "content": { "query": "first website", "slop": 10 } } } ] } } }
(4) 优化短语搜索: rescore
短语搜索的性能要比全文搜索的性能低10倍以上, 所以一般我们要用短语搜索时都会配合全文搜索使用. 先通过全文搜索出匹配的doc, 然后对相关度分数最高的前n条doc进行rescore短语搜索. (这里只能用于分页搜索)
GET /website/article/_search { "query": { "match": { "content": "first website" } }, "rescore": { "window_size": 20, "query": { "rescore_query": { "match_phrase": { "content": { "query": "first website", "slop": 10 } } } } } }
(5) match_phrase_prefix
匹配短语的前缀, 用于做搜索推荐. 比如我们在百度输入一个关键词, 立马就会推荐一系列查询词, 这个就是搜索推荐.
这个功能不推荐使用, 因为性能太差, 我们一般通过ngram分词机制来实现搜索推荐.
GET /website/article/_search { "query": { "match_phrase_prefix": { "title": "my sec" } } }
fuzzy search
模糊搜索, 自动将拼写错误的搜索文本进行纠正, 然后去匹配索引中的数据.
(1) 语法一
GET /website/article/_search { "query": { "fuzzy": { "title.keyword": { "value": "my wecond article", "fuzziness": 2 } } } }
fuzziness代表最多纠正多少个字母, 默认为2. 搜索文本不会被分词.
(2) 语法二
GET /website/article/_search { "query": { "match": { "title": { "query": "my wecond article", "fuzziness": "auto", "operator": "and" } } } }
fuzziness可以给定个数, 也可以设置为auto.
term search
term查询, 是一种结构化查询, "查询词"不会被分词, 结果要么存在要么不存在, 不关心结果的score相关度. 如果查询text属性, 需要改为查询filed.keyword.
(1) 实例
和短语搜索对比一下可以更好的理解:
1. phrase搜索 GET /website/article/_search { "query": { "match_phrase": { "title": "my first article" } } } //存在一条结果 2. term搜索text GET /website/article/_search { "query": { "term": { "title": { "value": "my first article" } } } } //不存在结果, 原因是词语查询的value值不会被分词, 也就是直接查询"my first article". 3. term搜索keyword GET /website/article/_search { "query": { "term": { "title.keyword": { "value": "my first article" } } } } //存在一条结果, filed.keyword属性不分词.
2) 常用语法
为了提高效率, term搜索一般与filter和constant_score联用. constant_score 以固定的评分来执行查询(默认为1), 而filter不计算score相关度, 因此执行效率非常高.
GET /website/article/_search { "query": { "constant_score": { "filter": { "term": { "post_date": "2017-01-03" } } } } }
query filter
(1) 语法
query filter 用于过滤数据, 不参与score相关度计算, 效率很高. 适用于范围查询以及不计算相关度score的精确查询(filter + term)
(2) 实例
a. 从website索引中查询, 作者id必须大于等于11402,同时发表时间必须是2017-01-02.
GET /website/article/_search { "query": { "constant_score": { "filter": { "bool": { "must": [ { "term": { "post_date": "2017-01-02" } }, { "range": { "author_id": { "gte": 11402 } } } ] } } } } }
b. 搜索发布日期为2017-01-01, 或者文章标题为"my first article"的帖子, 同时要求文章的发布日期绝对不为2017-01-02.
GET /website/article/_search { "query": { "constant_score": { "filter": { "bool": { "should": [ { "term":{ "post_date": "2017-01-01" } }, { "term":{ "title.keyword": "my first article" } } ], "must_not": { "term": { "post_date": "2017-01-02" } } } } } } }
c. 搜索文章标题为"my first article", 或者是文章标题为"my second article", 而且发布日期为"2017-01-01"的文章.
GET /website/article/_search { "query": { "constant_score": { "filter": { "bool": { "should": [ { "term":{ "title.keyword": "my first article" } }, { "bool": { "must": [ { "term":{ "title.keyword": "my second article" } }, { "term":{ "post_date": "2017-01-01" } } ] } } ] } } } } }
d. 搜索文章标题为"my first article"或"my second article"的文章
GET /website/article/_search { "query": { "constant_score": { "filter": { "terms": { "title.keyword": [ "my first article", "my second article" ] } } } } }
e. 搜索tags中包含java的帖子.
GET /website/article/_search { "query": { "constant_score": { "filter": { "terms": { "tags.keyword": [ "java" ] } } } } }
注意, 这里必须用terms, 因为term不支持数组.
d. 搜索tags中只包含java的帖子.
如果想搜索tags中只包含java的帖子, 就需要新增一个字段tags_count, 表示tags中有几个tag, 否则就无法搜索.
GET /website/article/_search { "query": { "constant_score": { "filter": { "bool": { "must": [ { "terms": { "tags.keyword": [ "java" ] } }, { "term": { "tags_count": "1" } } ] } } } } }
对上面这几实例做个总结, should表示或, must表示且. scroll search scroll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来. 它的原理是每次查询时都生成一个游标scroll_id, 后续的查询根据这个游标去获取数据, 直到返回的hits字段为空. scroll_id相当于建立了一个历史快照, 在此之后的写操作不会影响到这个快照的结果, 也就意味着其不能用于实时查询.
滚动查询用来解决深度分页的问题, 就类似于sql语句: select * from comment where id > 1000 order by id asc limit 1000.
(1) 语法
查询时指定一个参数scroll, 代表scroll_id的有效期, 过期后scroll_id会被ES自动清除.
如果不需要特定的排序, 按照文档创建时间排序更高效.
scroll_id只能使用一次, 使用过后会被自动删除.
最后一次查询, hits为空时也会返回一个scroll_id, 我们需要手动删除来释放资源.
(2) 实例
a. 首次查询
GET /website/article/_search?scroll=1s { "query": { "match_all": {} }, "sort": [ { "_doc": { "order": "asc" } } ], "size": 1 }
b. 后续查询
scroll_id只能使用一次.
GET /_search/scroll?scroll=1s&scroll_id=DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAATqFmRBQ3FwUFVrUUw2VHgyU2I5UWRMRlEAAAAAAAAE6xZkQUNxcFBVa1FMNlR4MlNiOVFkTEZRAAAAAAAABOwWZEFDcXBQVWtRTDZUeDJTYjlRZExGUQAAAAAAAATtFmRBQ3FwUFVrUUw2VHgyU2I5UWRMRlEAAAAAAAAE7hZkQUNxcFBVa1FMNlR4MlNiOVFkTEZR { } 或者 GET /_search/scroll { "scroll":"1s", "scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAATqFmRBQ3FwUFVrUUw2VHgyU2I5UWRMRlEAAAAAAAAE6xZkQUNxcFBVa1FMNlR4MlNiOVFkTEZRAAAAAAAABOwWZEFDcXBQVWtRTDZUeDJTYjlRZExGUQAAAAAAAATtFmRBQ3FwUFVrUUw2VHgyU2I5UWRMRlEAAAAAAAAE7hZkQUNxcFBVa1FMNlR4MlNiOVFkTEZR" }
c. 删除指定scroll_id
DELETE /_search/scroll { "scroll_id": "scroll_id=DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAiXFmRBQ3FwUFVrUUw2VHgyU2I5UWRMRlEAAAAAAAAImBZkQUNxcFBVa1FMNlR4MlNiOVFkTEZRAAAAAAAACJkWZEFDcXBQVWtRTDZUeDJTYjlRZExGUQAAAAAAAAiaFmRBQ3FwUFVrUUw2VHgyU2I5UWRMRlEAAAAAAAAImxZkQUNxcFBVa1FMNlR4MlNiOVFkTEZR==" }
d. 删除所有scroll_id
DELETE /_search/scroll/_all
聚合
聚合包括分组和统计, 其中分组操作包括term, histogram, date_histogram, filter. 统计操作包括count, avg, max, min, sum, cardinality, percentiles, percentile_ranks等.
注意: 注意: 聚合的属性不能被分词.
语法
GET /index/type/_search { size: 0, "aggs": { "NAME": { "AGG_TYPE": { "field": "field_name" } } } }
NAME为聚合操作的名称, 可以取一个有参考意义的名称. AGG_TYPE为分组或统计操作, 当进行分组操作时, 会自动生成一个doc_count, 统计了组内数据的数量. 默认按照doc_count降序排列.
size=0的原因是不需要搜索结果, 如果需要搜索结果, 则去除size=0.
实例
(1) 实例数据
新增电视机销售记录, 用于接下来的实例分析.
POST /televisions/sales/_bulk { "index": {}} { "price" : 1000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-10-28" } { "index": {}} { "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-11-05" } { "index": {}} { "price" : 3000, "color" : "绿色", "brand" : "小米", "sold_date" : "2016-05-18" } { "index": {}} { "price" : 1500, "color" : "蓝色", "brand" : "TCL", "sold_date" : "2016-07-02" } { "index": {}} { "price" : 1200, "color" : "绿色", "brand" : "TCL", "sold_date" : "2016-08-19" } { "index": {}} { "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-11-05" } { "index": {}} { "price" : 8000, "color" : "红色", "brand" : "三星", "sold_date" : "2017-01-01" } { "index": {}} { "price" : 2500, "color" : "蓝色", "brand" : "小米", "sold_date" : "2017-02-12" }
mapping结构如下:
GET /televisions/_mapping/sales { "televisions": { "mappings": { "sales": { "properties": { "brand": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "color": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "price": { "type": "long" }, "sold_date": { "type": "date" } } } } } }
(2) 基础聚合实例
a. 统计哪种颜色的电视销量最高
GET /televisions/sales/_search { "size": 0, "aggs": { "max_sales_color": { "terms": { "field": "color.keyword" } } } }
分组后会计算出每组数据个数(doc_count), 默认按照doc_count降序显示.
b. 统计每种颜色电视的平均价格
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_color": { "terms": { "field": "color.keyword" }, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } }
c. 统计每种颜色电视的平均价格, 以及统计每种颜色下每个品牌的平均价格.
这里就涉及到嵌套分组了, 也叫做多层下钻分析.
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_color": { "terms": { "field": "color.keyword" }, "aggs": { "color_avg_price": { "avg": { "field": "price" } }, "group_by_brand": { "terms": { "field": "brand.keyword" }, "aggs": { "brand_avg_price": { "avg": { "field": "price" } } } } } } } }
d. 统计每种颜色电视机的最大最小价格
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_color": { "terms": { "field": "color.keyword" }, "aggs": { "max_price": { "max": { "field": "price" } }, "min_price": { "min": { "field": "price" } } } } } }
e. 统计每种颜色电视机的总销售额
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_color": { "terms": { "field": "color.keyword" }, "aggs": { "sum_price": { "sum": { "field": "price" } } } } } }
(2) 高级聚合实例
a. 按价格区间统计电视销量和销售额
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_price_range": { "histogram": { "field": "price", "interval": 2000 }, "aggs": { "sum_price": { "sum": { "field": "price" } } } } } }
b. 统计 2016-01-01 ~ 2017-12-31 范围内每个月的电视机销量.
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_sold_date": { "date_histogram": { "field": "sold_date", "interval": "month", "format": "yyyy-MM-dd", "min_doc_count": 0, "extended_bounds": { "min": "2016-01-01", "max": "2017-12-31" } } } } }
c. 统计 2016-01-01 ~ 2017-12-31 范围内每个季度的销售额以及该季度下每个品牌的销售额
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_sold_date": { "date_histogram": { "field": "sold_date", "interval": "quarter", "format": "yyyy-MM-dd", "min_doc_count": 0, "extended_bounds": { "min": "2016-01-01", "max": "2017-12-31" } }, "aggs": { "sum_price": { "sum": { "field": "price" } }, "group_by_brand": { "terms": { "field": "brand.keyword" }, "aggs": { "brand_sum_price": { "sum": { "field": "price" } } } } } } } }
d. 统计每种颜色电视的销售额, 按照销售额升序排序
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_color": { "terms": { "field": "color.keyword", "order": { "sum_price": "asc" } }, "aggs": { "sum_price": { "sum": { "field": "price" } } } } } }
e. 统计每种颜色下的每个品牌电视机的总销售额, 并按这个销售额升序排序.
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_color": { "terms": { "field": "color.keyword" }, "aggs": { "group_by_brand": { "terms": { "field": "brand.keyword", "order": { "color_brand_sum_price": "asc" } }, "aggs": { "color_brand_sum_price": { "sum": { "field": "price" } } } } } } } }
f. 统计每个月的电视销量, 并按品牌去重.
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_sold_date": { "date_histogram": { "field": "sold_date", "interval": "month", "format": "yyyy-MM-dd" }, "aggs": { "distinct_brand": { "cardinality": { "field": "brand.keyword", "precision_threshold": 100 } } } } } }
cardinality 去重采用的是近似估计的算法, 错误率在5%左右, 其中precision_threshold指定的值为100%准确去重的数量, 值设置的越大, 内存开销也就越大.
g. 统计50%, 90% 和 99%的电视的最大价格(一般用于统计api请求的最长延迟时间)
GET /televisions/sales/_search { "size": 0, "aggs": { "price_percentiles": { "percentiles": { "field": "price", "percents": [ 50, 90, 99 ] } } } }
h. 统计每个品牌的电视机的价格, 在1000以内, 2000以内, 3000以内, 4000以内的所占比例.
GET /televisions/sales/_search { "size": 0, "aggs": { "group_by_brand": { "terms": { "field": "brand.keyword" }, "aggs": { "price_percentile_ranks": { "percentile_ranks": { "field": "price", "values": [ 1000, 2000, 3000, 4000 ] } } } } } }
3) 搜索+聚合
a. 统计指定品牌下(小米)每个颜色的销量
GET /televisions/sales/_search { "size": 0, "query": { "term": { "brand.keyword": { "value": "小米" } } }, "aggs": { "group_by_color": { "terms": { "field": "color.keyword" } } } }
或者
GET /televisions/sales/_search { "size": 0, "query": { "constant_score": { "filter": { "term": { "brand.keyword": "小米" } } } }, "aggs": { "group_by_color": { "terms": { "field": "color.keyword" } } } }
其实对于聚合来说, 因为不需要搜索结果, 可以直接用filter, 效率更高.
b. 统计单个品牌(长虹)与所有品牌销售额对比
GET /televisions/sales/_search { "size": 0, "query": { "constant_score": { "filter": { "term": { "brand.keyword": "长虹" } } } }, "aggs": { "single_brand_sum_price": { "sum": { "field": "price" } }, "all_brand": { "global": {}, "aggs": { "all_brand_sum_price": { "sum": { "field": "price" } } } } } }
global 表示将所有数据纳入聚合的scope,忽视前面的query过滤.
c. 统计指定品牌(长虹)最近一个月和最近半年的平均价格
GET /televisions/sales/_search { "size": 0, "query": { "term": { "brand.keyword": { "value": "长虹" } } }, "aggs": { "recent_one_month": { "filter": { "range": { "sold_date": { "gte": "now-1M" } } }, "aggs": { "recent_one_month_avg_price": { "avg": { "field": "price" } } } }, "recent_six_month": { "filter": { "range": { "sold_date": { "gte": "now-6M" } } }, "aggs": { "recent_six_month_avg_price": { "avg": { "field": "price" } } } } } }
————————————————
版权声明:本文为CSDN博主「椰子Tyshawn」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/litianxiang_kaola/article/details/102936324