https://www.w3cschool.cn/openresty1/
OpenResty 简介
OpenResty(也称为 ngx_openresty)是一个全功能的 Web 应用服务器。它打包了标准的 Nginx 核心,很多的常用的第三方模块,以及它们的大多数依赖项。
通过揉和众多设计良好的 Nginx 模块,OpenResty 有效地把 Nginx 服务器转变为一个强大的 Web 应用服务器,基于它开发人员可以使用 Lua 编程语言对 Nginx 核心以及现有的各种 Nginx C 模块进行脚本编程,构建出可以处理一万以上并发请求的极端高性能的 Web 应用。
OpenResty 致力于将你的服务器端应用完全运行于 Nginx 服务器中,充分利用 Nginx 的事件模型来进行非阻塞 I/O 通信。不仅仅是和 HTTP 客户端间的网络通信是非阻塞的,与MySQL、PostgreSQL、Memcached 以及 Redis 等众多远方后端之间的网络通信也是非阻塞的。
因为 OpenResty 软件包的维护者也是其中打包的许多 Nginx 模块的作者,所以 OpenResty 可以确保所包含的所有组件可以可靠地协同工作。
OpenResty 最早是雅虎中国的一个公司项目,起步于 2007 年 10 月。当时兴起了 OpenAPI 的热潮,用于满足各种 Web Service 的需求,就诞生了 OpenResty。在公司领导的支持下,最早的 OpenResty 实现从一开始就开源了。最初的定位是服务于公司外的开发者,像其他的 OpenAPI 那样,但后来越来越多地是为雅虎中国的搜索产品提供内部服务。这是第一代的 OpenResty,当时的想法是,提供一套抽象的 web service,能够让用户利用这些 web service 构造出新的符合他们具体业务需求的 Web Service 出来,所以有些“meta web service”的意味,包括数据模型、查询、安全策略都可以通过这种 meta web service 来表达和配置。同时这种 web service 也有意保持 REST 风格。与这种概念相对应的是纯 AJAX 的 web 应用,即 web 应用几乎都使用客户端 JavaScript 来编写,然后完全由 web service 让 web 应用“活”起来。用户把 .html, .js, .css, .jpg 等静态文件下载到 web browser 中,然后 js 开始运行,跨域请求雅虎提供的经过站长定制过的 web service,然后应用就可以运行起来。不过随着后来的发展,公司外的用户毕竟还是少数,于是应用的重点是为公司内部的其他团队提供 web service,比如雅虎中国的全能搜索产品,及其外围的一些产品。从那以后,开发的重点便放在了性能优化上面。章亦春在加入淘宝数据部门的量子团队之后,决定对 OpenResty 进行重新设计和彻底重写,并把应用重点放在支持像量子统计这样的 web 产品上面,所以量子统计 3.0 开始也几乎完全是 web service 驱动的纯 AJAX 应用。
这是第二代的 OpenResty,一般称之为 ngx_openresty,以便和第一代基于 Perl 和 Haskell 实现的 OpenResty 加以区别。章亦春和他的同事王晓哲一起设计了第二代的 OpenResty。在王晓哲的提议下,选择基于 nginx 和 lua 进行开发。
为什么要取 OpenResty 这个名字呢?OpenResty 最早是顺应 OpenAPI 的潮流做的,所以 Open 取自“开放”之意,而Resty便是 REST 风格的意思。虽然后来也可以基于 ngx_openresty 实现任何形式的 web service 或者传统的 web 应用。
也就是说 Nginx 不再是一个简单的静态网页服务器,也不再是一个简单的反向代理了。第二代的 openresty 致力于通过一系列 nginx 模块,把nginx扩展为全功能的 web 应用服务器。
ngx_openresty 是用户驱动的项目,后来也有不少国内用户的参与,从 openresty.org 的点击量分布上看,国内和国外的点击量基本持平。
ngx_openresty 目前有两大应用目标:
- 通用目的的 web 应用服务器。在这个目标下,现有的 web 应用技术都可以算是和 OpenResty 或多或少有些类似,比如 Nodejs, PHP 等等。ngx_openresty 的性能(包括内存使用和 CPU 效率)算是最大的卖点之一。
- Nginx 的脚本扩展编程,用于构建灵活的 Web 应用网关和 Web 应用防火墙。有些类似的是 NetScaler。其优势在于 Lua 编程带来的巨大灵活性。
ngx_openresty 从一开始就是公司实际的业务需求的产物。在过去的几年中的大部分开发工作也是由国内外许多公司和个人的实际业务需求驱动的。这种模型在实践中工作得非常好,可以确保我们做的就是大家最迫切需要的。在此过程中,慢慢形成了 ngx_openresty 的两大应用方向,也就是前面提到的那两大方向。是我们的用户帮助我们确认了这两个方向,事实上,这并不等同于第一代 OpenResty 的方向,而是变得更加底层和更加通用了。
OpenResty Lua 环境搭建
在 Windows 上搭建环境
从 1.9.3.2 版本开始,OpenResty 正式对外同时公布维护了 Windows 版本,其中直接包含了编译好的最新版本 LuaJIT。由于 Windows 操作系统自身相对良好的二进制兼容性,使用者只需要下载、解压两个步骤即可。
打开 http://openresty.org,选择左侧的 Download 连接,这时候我们就可以下载最新版本的 OpenResty 版本(例如笔者写书时的最新版本:ngx_openresty-1.9.7.1-win32.zip)。
在 Linux、Mac OS X 上搭建环境
到 LuaJIT 官网 http://luajit.org/download.html,查看当前最新开发版本,例如笔者写书时的最新版本:http://luajit.org/download/LuaJIT-2.1.0-beta1.tar.gz。
# wget http://luajit.org/download/LuaJIT-2.1.0-beta1.tar.gz
# tar -xvf LuaJIT-2.1.0-beta1.tar.gz
# cd LuaJIT-2.1.0-beta1
# make
# sudo make install大家都知道,在不同平台,可能都有不同的安装工具来简化我们的安装。为什么我们这给大家推荐的是源码这么原始的方式?笔者为了偷懒么?答案:是的。当然还有另外一个原因,就是我们安装的是 LuaJIT 2.1 版本。
由于LuaJIT 2.1 目前还是beta版本,所以在make install后,并没有进行luajit的符号连接,可以执行下面的指令将luajit-2.1.0-beta1和luajit进行软连接,从而可以直接使用luajit命令
ln -sf luajit-2.1.0-beta1 /usr/local/bin/luajit
验证 LuaJIT 是否安装成功
# luajit -v
LuaJIT 2.1.0-beta1 -- Copyright (C) 2005-2015 Mike Pall.
http://luajit.org/
如果想了解其他系统安装 LuaJIT 的步骤,或者安装过程中遇到问题,可以到 LuaJIT 官网查看:http://luajit.org/install.html
OpenResty Nginx 新手起步
为什选择 Nginx
为什么选择 Nginx?因为它具有以下特点:
1、处理响应请求很快
在正常的情况下,单次请求会得到更快的响应。在高峰期,Nginx 可以比其它的 Web 服务器更快的响应请求。
2、高并发连接
在互联网快速发展,互联网用户数量不断增加的今天,一些大公司、网站都需要面对高并发请求,如果有一个能够在峰值顶住 10 万以上并发请求的 Server,肯定会得到大家的青睐。理论上,Nginx 支持的并发连接上限取决于你的内存,10 万远未封顶。
3、低的内存消耗
在一般的情况下,10000 个非活跃的 HTTP Keep-Alive 连接在 Nginx 中仅消耗 2.5MB 的内存,这也是 Nginx 支持高并发连接的基础。
4、具有很高的可靠性:
Nginx 是一个高可靠性的 Web 服务器,这也是我们为什么选择 Nginx 的基本条件,现在很多的网站都在使用 Nginx,足以说明 Nginx 的可靠性。高可靠性来自其核心框架代码的优秀设计、模块设计的简单性,并且这些模块都非常的稳定。
5、高扩展性
Nginx 的设计极具扩展性,它完全是由多个不同功能、不同层次、不同类型且耦合度极低的模块组成。这种设计造就了 Nginx 庞大的第三方模块。
6、热部署
master 管理进程与 worker 工作进程的分离设计,使得 Nginx 具有热部署的功能,可以在 7 × 24 小时不间断服务的前提下,升级 Nginx 的可执行文件。也可以在不停止服务的情况下修改配置文件,更换日志文件等功能。
7、自由的 BSD 许可协议
BSD 许可协议不只是允许用户免费使用 Nginx,也允许用户修改 Nginx 源码,还允许用户用于商业用途。
如何使用 Nginx
Nginx 安装:
不同系统依赖包可能不同,例如 pcre,zlib,openssl 等。
- 获取 Nginx,在 http://nginx.org/en/download.html 上可以获取当前最新的版本。
- 解压缩 nginx-xx.tar.gz 包。
- 进入解压缩目录,执行 ./configure
- make & make install
若安装时找不到上述依赖模块,使用 --with-openssl=<openssl_dir>、--with-pcre=<pcre_dir>、--with-zlib=<zlib_dir> 指定依赖的模块目录。如已安装过,此处的路径为安装目录;若未安装,则此路径为编译安装包路径,Nginx 将执行模块的默认编译安装。
启动 Nginx 之后,浏览器中输入 http://localhost 可以验证是否安装启动成功。

Nginx 配置示例:
安装完成之后,配置目录 conf 下有以下配置文件,过滤掉了 xx.default 配置:
ubuntu: /opt/nginx-1.7.7/conf$ tree |grep -v default
.
├── fastcgi.conf
├── fastcgi_params
├── koi-utf
├── koi-win
├── mime.types
├── nginx.conf
├── scgi_params
├── uwsgi_params
└── win-utf
除了 nginx.conf,其余配置文件,一般只需要使用默认提供即可。
nginx.conf 是主配置文件,默认配置去掉注释之后的内容如下图所示:
worker_process # 表示工作进程的数量,一般设置为cpu的核数
worker_connections # 表示每个工作进程的最大连接数
server{} # 块定义了虚拟主机
listen # 监听端口
server_name # 监听域名
location {} # 是用来为匹配的 URI 进行配置,URI 即语法中的“/uri/”
location /{} # 匹配任何查询,因为所有请求都以 / 开头
root # 指定对应uri的资源查找路径,这里html为相对路径,完整路径为
# /opt/nginx-1.7.7/html/
index # 指定首页index文件的名称,可以配置多个,以空格分开。如有多
# 个,按配置顺序查找。
真实用例
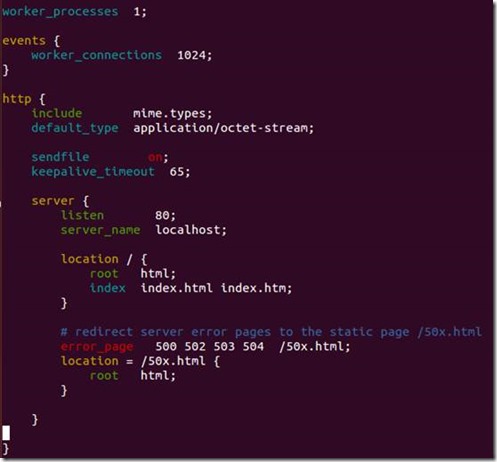
从配置可以看出,Nginx 监听了 80 端口、域名为 localhost、根路径为 html 文件夹(我的安装路径为 /opt/nginx-1.7.7,所以 /opt/nginx-1.7.7/html)、默认 index 文件为 index.html,index.htm 服务器错误重定向到 50x.html 页面。
可以看到 /opt/nginx-1.7.7/html/ 有以下文件:
ubuntu:/opt/nginx-1.7.7/html$ ls
50x.html index.html
这也是上面在浏览器中输入 http://localhost,能够显示欢迎页面的原因。实际上访问的是 /opt/nginx-1.7.7/html/index.html 文件。
OpenResty Nginx location匹配规则
语法规则
location [=|~|~*|^~] /uri/ { … }
| 模式 | 含义 |
|---|---|
| location = /uri | = 表示精确匹配,只有完全匹配上才能生效 |
| location ^~ /uri | ^~ 开头对URL路径进行前缀匹配,并且在正则之前。 |
| location ~ pattern | 开头表示区分大小写的正则匹配 |
| location ~* pattern | 开头表示不区分大小写的正则匹配 |
| location /uri | 不带任何修饰符,也表示前缀匹配,但是在正则匹配之后 |
| location / | 通用匹配,任何未匹配到其它location的请求都会匹配到,相当于switch中的default |
前缀匹配时,Nginx 不对 url 做编码,因此请求为 /static/20%/aa,可以被规则 ^~ /static/ /aa 匹配到(注意是空格)
多个 location 配置的情况下匹配顺序为(参考资料而来,还未实际验证,试试就知道了,不必拘泥,仅供参考):
- 首先精确匹配
= - 其次前缀匹配
^~ - 其次是按文件中顺序的正则匹配
- 然后匹配不带任何修饰的前缀匹配。
- 最后是交给
/ 通用匹配 - 当有匹配成功时候,停止匹配,按当前匹配规则处理请求
注意:前缀匹配,如果有包含关系时,按最大匹配原则进行匹配。比如在前缀匹配:location /dir01 与 location /dir01/dir02,如有请求 http://localhost/dir01/dir02/file 将最终匹配到 location /dir01/dir02
例子,有如下匹配规则:
location = / {
echo "规则A";
}
location = /login {
echo "规则B";
}
location ^~ /static/ {
echo "规则C";
}
location ^~ /static/files {
echo "规则X";
}
location ~ \.(gif|jpg|png|js|css)$ {
echo "规则D";
}
location ~* \.png$ {
echo "规则E";
}
location /img {
echo "规则Y";
}
location / {
echo "规则F";
}
那么产生的效果如下:
- 访问根目录
/,比如 http://localhost/ 将匹配规则A - 访问
http://localhost/login 将匹配 规则B,http://localhost/register 则匹配 规则F - 访问
http://localhost/static/a.html 将匹配 规则C - 访问
http://localhost/static/files/a.exe 将匹配 规则X,虽然 规则C 也能匹配到,但因为最大匹配原则,最终选中了 规则X。你可以测试下,去掉规则 X ,则当前 URL 会匹配上 规则C。 - 访问
http://localhost/a.gif, http://localhost/b.jpg将匹配 规则D 和规则 E,但是 规则 D 顺序优先,规则 E 不起作用,而 http://localhost/static/c.png 则优先匹配到 规则 C - 访问
http://localhost/a.PNG 则匹配 规则 E,而不会匹配 规则 D ,因为 规则 E 不区分大小写。 - 访问
http://localhost/img/a.gif 会匹配上 规则D,虽然 规则Y 也可以匹配上,但是因为正则匹配优先,而忽略了 规则Y。 - 访问
http://localhost/img/a.tiff 会匹配上规则Y。
访问 http://localhost/category/id/1111 则最终匹配到规则 F ,因为以上规则都不匹配,这个时候应该是 Nginx 转发请求给后端应用服务器,比如 FastCGI(php),tomcat(jsp),Nginx 作为反向代理服务器存在。
所以实际使用中,笔者觉得至少有三个匹配规则定义,如下:
# 直接匹配网站根,通过域名访问网站首页比较频繁,使用这个会加速处理,官网如是说。
# 这里是直接转发给后端应用服务器了,也可以是一个静态首页
# 第一个必选规则
location = / {
proxy_pass http://tomcat:8080/index
}
# 第二个必选规则是处理静态文件请求,这是 nginx 作为 http 服务器的强项
# 有两种配置模式,目录匹配或后缀匹配,任选其一或搭配使用
location ^~ /static/ {
root /webroot/static/;
}
location ~* \.(gif|jpg|jpeg|png|css|js|ico)$ {
root /webroot/res/;
}
# 第三个规则就是通用规则,用来转发动态请求到后端应用服务器
# 非静态文件请求就默认是动态请求,自己根据实际把握
# 毕竟目前的一些框架的流行,带.php、.jsp后缀的情况很少了
location / {
proxy_pass http://tomcat:8080/
}
rewrite 语法
- last – 基本上都用这个 flag
- break – 中止 rewrite,不再继续匹配
- redirect – 返回临时重定向的 HTTP 状态 302
- permanent – 返回永久重定向的 HTTP 状态 301
1、下面是可以用来判断的表达式:
-f 和 !-f 用来判断是否存在文件
-d 和 !-d 用来判断是否存在目录
-e 和 !-e 用来判断是否存在文件或目录
-x 和 !-x 用来判断文件是否可执行
2、下面是可以用作判断的全局变量
例:http://localhost:88/test1/test2/test.php?k=v
$host:localhost
$server_port:88
$request_uri:/test1/test2/test.php?k=v
$document_uri:/test1/test2/test.php
$document_root:D:\nginx/html
$request_filename:D:\nginx/html/test1/test2/test.php
redirect 语法
server {
listen 80;
server_name start.igrow.cn;
index index.html index.php;
root html;
if ($http_host !~ "^star\.igrow\.cn$") {
rewrite ^(.*) http://star.igrow.cn$1 redirect;
}
}
防盗链
location ~* \.(gif|jpg|swf)$ {
valid_referers none blocked start.igrow.cn sta.igrow.cn;
if ($invalid_referer) {
rewrite ^/ http://$host/logo.png;
}
}
根据文件类型设置过期时间
location ~* \.(js|css|jpg|jpeg|gif|png|swf)$ {
if (-f $request_filename) {
expires 1h;
break;
}
}
禁止访问某个目录
location ~* \.(txt|doc)${
root /data/www/wwwroot/linuxtone/test;
deny all;
}OpenResty Nginx 静态文件服务
我们先来看看最简单的本地静态文件服务配置示例:
server {
listen 80;
server_name www.test.com;
charset utf-8;
root /data/www.test.com;
index index.html index.htm;
}
就这些?恩,就这些!如果只是提供简单的对外静态文件,它真的就可以用了。可是他不完美,远远没有发挥 Nginx 的半成功力,为什么这么说呢,看看下面的配置吧,为了大家看着方便,我们把每一项的作用都做了注释。
http {
# 这个将为打开文件指定缓存,默认是没有启用的,max 指定缓存数量,
# 建议和打开文件数一致,inactive 是指经过多长时间文件没被请求后删除缓存。
open_file_cache max=204800 inactive=20s;
# open_file_cache 指令中的inactive 参数时间内文件的最少使用次数,
# 如果超过这个数字,文件描述符一直是在缓存中打开的,如上例,如果有一个
# 文件在inactive 时间内一次没被使用,它将被移除。
open_file_cache_min_uses 1;
# 这个是指多长时间检查一次缓存的有效信息
open_file_cache_valid 30s;
# 默认情况下,Nginx的gzip压缩是关闭的, gzip压缩功能就是可以让你节省不
# 少带宽,但是会增加服务器CPU的开销哦,Nginx默认只对text/html进行压缩 ,
# 如果要对html之外的内容进行压缩传输,我们需要手动来设置。
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/x-javascript text/css application/xml;
server {
listen 80;
server_name www.test.com;
charset utf-8;
root /data/www.test.com;
index index.html index.htm;
}
}
我们都知道,应用程序和网站一样,其性能关乎生存。但如何使你的应用程序或者网站性能更好,并没有一个明确的答案。代码质量和架构是其中的一个原因,但是在很多例子中我们看到,你可以通过关注一些十分基础的应用内容分发技术(basic application delivery techniques),来提高终端用户的体验。其中一个例子就是实现和调整应用栈(application stack)的缓存。
文件缓存漫谈
一个 web 缓存坐落于客户端和原始服务器(origin server)中间,它保留了所有可见内容的拷贝。如果一个客户端请求的内容在缓存中存储,则可以直接在缓存中获得该内容而不需要与服务器通信。这样一来,由于 web 缓存距离客户端“更近”,就可以提高响应性能,并更有效率的使用应用服务器,因为服务器不用每次请求都进行页面生成工作。
在浏览器和应用服务器之间,存在多种潜在缓存,如:客户端浏览器缓存、中间缓存、内容分发网络(CDN)和服务器上的负载平衡和反向代理。缓存,仅在反向代理和负载均衡的层面,就对性能提高有很大的帮助。
举个例子说明,去年,我接手了一项任务,这项任务的内容是对一个加载缓慢的网站进行性能优化。首先引起我注意的事情是,这个网站差不多花费了超过 1 秒钟才生成了主页。经过一系列调试,我发现加载缓慢的原因在于页面被标记为不可缓存,即为了响应每一个请求,页面都是动态生成的。由于页面本身并不需要经常性的变更,并且不涉及个性化,那么这样做其实并没有必要。为了验证一下我的结论,我将页面标记为每 5 秒缓存一次,仅仅做了这一个调整,就能明显的感受到性能的提升。第一个字节到达的时间降低到几毫秒,同时页面的加载明显要更快。
并不是只有大规模的内容分发网络(CDN)可以在使用缓存中受益——缓存还可以提高负载平衡器、反向代理和应用服务器前端 web 服务的性能。通过上面的例子,我们看到,缓存内容结果,可以更高效的使用应用服务器,因为不需要每次都去做重复的页面生成工作。此外,Web 缓存还可以用来提高网站可靠性。当服务器宕机或者繁忙时,比起返回错误信息给用户,不如通过配置 Nginx 将已经缓存下来的内容发送给用户。这意味着,网站在应用服务器或者数据库故障的情况下,可以保持部分甚至全部的功能运转。
下面讨论如何安装和配置 Nginx 的基础缓存(Basic Caching)。
如何安装和配置基础缓存
我们只需要两个命令就可以启用基础缓存:proxy_cache_path 和 proxy_cache。proxy_cache_path 用来设置缓存的路径和配置,proxy_cache 用来启用缓存。
proxy_cache_path/path/to/cache levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m
use_temp_path=off;
server {
...
location / {
proxy_cache my_cache;
proxy_pass http://my_upstream;
}
}
proxy_cache_path 命令中的参数及对应配置说明如下:
- 用于缓存的本地磁盘目录是 /path/to/cache/
- levels 在 /path/to/cache/ 设置了一个两级层次结构的目录。将大量的文件放置在单个目录中会导致文件访问缓慢,所以针对大多数部署,我们推荐使用两级目录层次结构。如果 levels 参数没有配置,则 Nginx 会将所有的文件放到同一个目录中。
- keys_zone 设置一个共享内存区,该内存区用于存储缓存键和元数据,有些类似计时器的用途。将键的拷贝放入内存可以使 Nginx 在不检索磁盘的情况下快速决定一个请求是
HIT还是 MISS,这样大大提高了检索速度。一个 1MB 的内存空间可以存储大约 8000 个 key,那么上面配置的 10MB 内存空间可以存储差不多 80000 个 key。 - max_size 设置了缓存的上限(在上面的例子中是 10G)。这是一个可选项;如果不指定具体值,那就是允许缓存不断增长,占用所有可用的磁盘空间。当缓存达到这个上限,处理器便调用 cache manager 来移除最近最少被使用的文件,这样把缓存的空间降低至这个限制之下。
- inactive 指定了项目在不被访问的情况下能够在内存中保持的时间。在上面的例子中,如果一个文件在 60 分钟之内没有被请求,则缓存管理将会自动将其在内存中删除,不管该文件是否过期。该参数默认值为 10 分钟(10m)。注意,非活动内容有别于过期内容。Nginx 不会自动删除由缓存控制头部指定的过期内容(本例中 Cache-Control:max-age=120)。过期内容只有在 inactive 指定时间内没有被访问的情况下才会被删除。如果过期内容被访问了,那么 Nginx 就会将其从原服务器上刷新,并更新对应的 inactive 计时器。
- Nginx 最初会将注定写入缓存的文件先放入一个临时存储区域,use_temp_path=off 命令指示 Nginx 将在缓存这些文件时将它们写入同一个目录下。我们强烈建议你将参数设置为 off 来避免在文件系统中不必要的数据拷贝。use_temp_path 在 Nginx 1.7 版本和 Nginx Plus R6 中有所介绍。
最终,proxy_cache 命令启动缓存那些 URL 与 location 部分匹配的内容(本例中,为 /)。你同样可以将 proxy_cache 命令添加到 server 部分,这将会将缓存应用到所有的那些 location 中未指定自己的 proxy_cache 命令的服务中。
陈旧总比没有强
Nginx 内容缓存的一个非常强大的特性是:当无法从原始服务器获取最新的内容时,Nginx 可以分发缓存中的陈旧(stale,编者注:即过期内容)内容。这种情况一般发生在关联缓存内容的原始服务器宕机或者繁忙时。比起对客户端传达错误信息,Nginx 可发送在其内存中的陈旧的文件。Nginx 的这种代理方式,为服务器提供额外级别的容错能力,并确保了在服务器故障或流量峰值的情况下的正常运行。为了开启该功能,只需要添加 proxy_cache_use_stale 命令即可:
location / {
...
proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504;
}
按照上面例子中的配置,当 Nginx 收到服务器返回的 error,timeout 或者其他指定的 5xx 错误,并且在其缓存中有请求文件的陈旧版本,则会将这些陈旧版本的文件而不是错误信息发送给客户端。
缓存微调
Nginx 提供了丰富的可选项配置用于缓存性能的微调。下面是使用了几个配置的例子:
proxy_cache_path /path/to/cache levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m
use_temp_path=off;
server {
...
location / {
proxy_cache my_cache;
proxy_cache_revalidate on;
proxy_cache_min_uses 3;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_cache_lock on;
proxy_pass http://my_upstream;
}
}
这些命令配置了下列的行为:
- proxy_cache_revalidate 指示 Nginx 在刷新来自服务器的内容时使用 GET 请求。如果客户端的请求项已经被缓存过了,但是在缓存控制头部中定义为过期,那么 Nginx 就会在 GET 请求中包含 If-Modified-Since 字段,发送至服务器端。这项配置可以节约带宽,因为对于 Nginx 已经缓存过的文件,服务器只会在该文件请求头中 Last-Modified 记录的时间内被修改时才将全部文件一起发送。
- proxy_cache_min_uses 该指令设置同一链接请求达到几次即被缓存,默认值为 1 。当缓存不断被填满时,这项设置便十分有用,因为这确保了只有那些被经常访问的内容会被缓存。
- proxy_cache_use_stale 中的 updating 参数告知 Nginx 在客户端请求的项目的更新正在原服务器中下载时发送旧内容,而不是向服务器转发重复的请求。第一个请求陈旧文件的用户不得不等待文件在原服务器中更新完毕。陈旧的文件会返回给随后的请求直到更新后的文件被全部下载。
- 当 proxy_cache_lock 被启用时,当多个客户端请求一个缓存中不存在的文件(或称之为一个 MISS),只有这些请求中的第一个被允许发送至服务器。其他请求在第一个请求得到满意结果之后在缓存中得到文件。如果不启用 proxy_cache_lock,则所有在缓存中找不到文件的请求都会直接与服务器通信。
跨多硬盘分割缓存
使用 Nginx 不需要建立一个 RAID(磁盘阵列)。如果有多个硬盘,Nginx 可以用来在多个硬盘之间分割缓存。下面是一个基于请求 URI 跨越两个硬盘之间均分缓存的例子:
proxy_cache_path /path/to/hdd1 levels=1:2 keys_zone=my_cache_hdd1:10m max_size=10g
inactive=60m use_temp_path=off;
proxy_cache_path /path/to/hdd2 levels=1:2 keys_zone=my_cache_hdd2:10m max_size=10g inactive=60m use_temp_path=off;
split_clients $request_uri $my_cache {
50% "my_cache_hdd1";
50% "my_cache_hdd2";
}
server {
...
location / {
proxy_cache $my_cache;
proxy_pass http://my_upstream;
}
}OpenResty Nginx 日志
Nginx 日志主要有两种:access_log(访问日志) 和 error_log(错误日志)。
access_log 访问日志
access_log 主要记录客户端访问 Nginx 的每一个请求,格式可以自定义。通过 access_log 你可以得到用户地域来源、跳转来源、使用终端、某个 URL 访问量等相关信息。
log_format 指令用于定义日志的格式,语法: log_format name string; 其中 name 表示格式名称,string 表示定义的格式字符串。log_format 有一个默认的无需设置的组合日志格式。
默认的无需设置的组合日志格式
log_format combined '$remote_addr - $remote_user [$time_local] '
' "$request" $status $body_bytes_sent '
' "$http_referer" "$http_user_agent" ';
access_log 指令用来指定访问日志文件的存放路径(包含日志文件名)、格式和缓存大小,语法:access_log path [format_name [buffer=size | off]]; 其中 path 表示访问日志存放路径,format_name 表示访问日志格式名称,buffer 表示缓存大小,off 表示关闭访问日志。
log_format 使用示例:在 access.log 中记录客户端 IP 地址、请求状态和请求时间
log_format myformat '$remote_addr $status $time_local';
access_log logs/access.log myformat;
需要注意的是:log_format 配置必须放在 http 内,否则会出现警告。Nginx 进程设置的用户和组必须对日志路径有创建文件的权限,否则,会报错。
定义日志使用的字段及其作用:
| 字段 | 作用 |
|---|---|
| $remote_addr与$http_x_forwarded_for | 记录客户端IP地址 |
| $remote_user | 记录客户端用户名称 |
| $request | 记录请求的URI和HTTP协议 |
| $status | 记录请求状态 |
| $body_bytes_sent | 发送给客户端的字节数,不包括响应头的大小 |
| $bytes_sent | 发送给客户端的总字节数 |
| $connection | 连接的序列号 |
| $connection_requests | 当前通过一个连接获得的请求数量 |
| $msec | 日志写入时间。单位为秒,精度是毫秒 |
| $pipe | 如果请求是通过HTTP流水线(pipelined)发送,pipe值为“p”,否则为“.” |
| $http_referer | 记录从哪个页面链接访问过来的 |
| $http_user_agent | 记录客户端浏览器相关信息 |
| $request_length | 请求的长度(包括请求行,请求头和请求正文) |
| $request_time | 请求处理时间,单位为秒,精度毫秒 |
| $time_iso8601 | ISO8601标准格式下的本地时间 |
| $time_local | 记录访问时间与时区 |
error_log 错误日志
error_log 主要记录客户端访问 Nginx 出错时的日志,格式不支持自定义。通过查看错误日志,你可以得到系统某个服务或 server 的性能瓶颈等。因此,将日志利用好,你可以得到很多有价值的信息。
error_log 指令用来指定错误日志,语法: error_log path [level]; 其中 path 表示错误日志存放路径,level 表示错误日志等级,日志等级包括 debug、info、notice、warn、error、crit、alert、emerg,从左至右,日志详细程度逐级递减,即 debug 最详细,emerg 最少,默认为 error。
注意:error_log off 并不能关闭错误日志记录,此时日志信息会被写入到文件名为 off 的文件当中。如果要关闭错误日志记录,可以使用如下配置:
Linux 系统把存储位置设置为空设备
error_log /dev/null;
http {
# ...
}
Windows 系统把存储位置设置为空设备
error_log nul;
http {
# ...
}
另外 Linux 系统可以使用 tail 命令方便的查阅正在改变的文件,tail -f filename 会把 filename 里最尾部的内容显示在屏幕上, 并且不断刷新, 使你看到最新的文件内容。Windows 系统没有这个命令,你可以在网上找到动态查看文件的工具。
OpenResty Nginx 反向代理
什么是反向代理
反向代理(Reverse Proxy)方式是指用代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
举个例子,一个用户访问 http://www.example.com/readme,但是 www.example.com 上并不存在 readme 页面,它是偷偷从另外一台服务器上取回来,然后作为自己的内容返回给用户。但是用户并不知情这个过程。对用户来说,就像是直接从 www.example.com 获取 readme 页面一样。这里所提到的 www.example.com 这个域名对应的服务器就设置了反向代理功能。
反向代理服务器,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容原本就是它自己的一样。如下图所示:
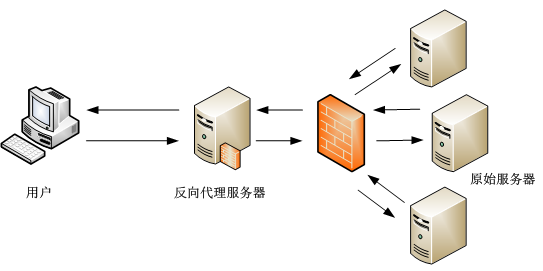
反向代理典型应用场景
反向代理的典型用途是将防火墙后面的服务器提供给 Internet 用户访问,加强安全防护。反向代理还可以为后端的多台服务器提供负载均衡,或为后端较慢的服务器提供 缓冲 服务。另外,反向代理还可以启用高级 URL 策略和管理技术,从而使处于不同 web 服务器系统的 web 页面同时存在于同一个 URL 空间下。
Nginx 的其中一个用途是做 HTTP 反向代理,下面简单介绍 Nginx 作为反向代理服务器的方法。
场景描述:访问本地服务器上的 README.md 文件 http://localhost/README.md,本地服务器进行反向代理,从 https://github.com/moonbingbing/openresty-best-practices/blob/master/README.md 获取页面内容。
nginx.conf 配置示例:
worker_processes 1;
pid logs/nginx.pid;
error_log logs/error.log warn;
events {
worker_connections 3000;
}
http {
include mime.types;
server_tokens off;
## 下面配置反向代理的参数
server {
listen 8866;
## 1. 用户访问 http://ip:port,则反向代理到 https://github.com
location / {
proxy_pass https://github.com;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
## 2.用户访问 http://ip:port/README.md,则反向代理到
## https://github.com/.../README.md
location /README.md {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass https://github.com/moonbingbing/openresty-best-practices/blob/master/README.md;
}
}
}
成功启动 Nginx 后,我们打开浏览器,验证下反向代理的效果。在浏览器地址栏中输入 localhost/README.md,返回的结果是我们 GitHub 源代码的 README 页面。如下图:
我们只需要配置一下 nginx.conf 文件,不用写任何 web 页面,就可以偷偷地从别的服务器上读取一个页面返回给用户。
下面我们来看一下 nginx.conf 里用到的配置项:
(1) location
location 项对请求 URI 进行匹配,location 后面配置了匹配规则。例如上面的例子中,如果请求的 URI 是 localhost/,则会匹配 location / 这一项;如果请求的 URI 是 localhost/README.md,则会匹配 location /README.md 这项。
上面这个例子只是针对一个确定的 URI 做了反向代理,有的读者会有疑惑:如果对每个页面都进行这样的配置,那将会大量重复,能否做 批量 配置呢?此时需要配合使用 location 的正则匹配功能。具体实现方法可参考 Nginx 文档中 关于 location 的描述。
(2) proxy_pass
proxy_pass 后面跟着一个 URL,用来将请求反向代理到 URL 参数指定的服务器上。例如我们上面例子中的 proxy_pass https://github.com,则将匹配的请求反向代理到 https://github.com。
(3) proxy_set_header
默认情况下,反向代理不会转发原始请求中的 Host 头部,如果需要转发,就需要加上这句:proxy_set_header Host $host;
除了上面提到的常用配置项,还有 proxy_redirect、proxy_set_body、proxy_limit_rate 等参数,具体用法可以到Nginx 官网查看。
正向代理
既然有反向代理,自然也有正向代理。简单来说,正向代理就像一个跳板,例如一个用户访问不了某网站(例如 www.google.com),但是他能访问一个代理服务器,这个代理服务器能访问 www.google.com,于是用户可以先连上代理服务器,告诉它需要访问的内容,代理服务器去取回来返回给用户。例如一些常见的FQ工具、游戏代理就是利用正向代理的原理工作的,我们需要在这些正向代理工具上配置服务器的 IP 地址等信息。
OpenResty Nginx 负载均衡
负载均衡(Load balancing)是一种计算机网络技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。
使用带有负载均衡的多个服务器组件,取代单一的组件,可以通过冗余提高可靠性。负载均衡服务通常是由专用软体和硬件来完成。
负载均衡最重要的一个应用是利用多台服务器提供单一服务,这种方案有时也称之为服务器农场。通常,负载均衡主要应用于 Web 网站,大型的 Internet Relay Chat 网络,高流量的文件下载网站,NNTP(Network News Transfer Protocol)服务和 DNS 服务。现在负载均衡器也开始支持数据库服务,称之为数据库负载均衡器。
对于互联网服务,负载均衡器通常是一个软体程序,这个程序侦听一个外部端口,互联网用户可以通过这个端口来访问服务,而作为负载均衡器的软体会将用户的请求转发给后台内网服务器,内网服务器将请求的响应返回给负载均衡器,负载均衡器再将响应发送到用户,这样就向互联网用户隐藏了内网结构,阻止了用户直接访问后台(内网)服务器,使得服务器更加安全,可以阻止对核心网络栈和运行在其它端口服务的攻击。
当所有后台服务器出现故障时,有些负载均衡器会提供一些特殊的功能来处理这种情况。例如转发请求到一个备用的负载均衡器、显示一条关于服务中断的消息等。负载均衡器使得 IT 团队可以显著提高容错能力。它可以自动提供大量的容量以处理任何应用程序流量的增加或减少。
负载均衡在互联网世界中的作用如此重要,本章我们一起了解一下 Nginx 是如何帮我们完成 HTTP 协议负载均衡的。
upstream 负载均衡概要
配置示例,如下:
upstream test.net{
ip_hash;
server 192.168.10.13:80;
server 192.168.10.14:80 down;
server 192.168.10.15:8009 max_fails=3 fail_timeout=20s;
server 192.168.10.16:8080;
}
server {
location / {
proxy_pass http://test.net;
}
}
upstream 是 Nginx 的 HTTP Upstream 模块,这个模块通过一个简单的调度算法来实现客户端 IP 到后端服务器的负载均衡。在上面的设定中,通过 upstream 指令指定了一个负载均衡器的名称 test.net。这个名称可以任意指定,在后面需要用到的地方直接调用即可。
upstream 支持的负载均衡算法
Nginx 的负载均衡模块目前支持 6 种调度算法,下面进行分别介绍,其中后两项属于第三方调度算法。
- 轮询(默认):每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某台服务器宕机,故障系统被自动剔除,使用户访问不受影响。Weight 指定轮询权值,Weight 值越大,分配到的访问机率越高,主要用于后端每个服务器性能不均的情况下。
- ip_hash:每个请求按访问 IP 的 hash 结果分配,这样来自同一个 IP 的访客固定访问一个后端服务器,有效解决了动态网页存在的 session 共享问题。
- fair:这是比上面两个更加智能的负载均衡算法。此种算法可以依据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间来分配请求,响应时间短的优先分配。Nginx 本身是不支持 fair 的,如果需要使用这种调度算法,必须下载 Nginx 的 upstream_fair 模块。
- url_hash:此方法按访问 url 的 hash 结果来分配请求,使每个 url 定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。Nginx 本身是不支持 url_hash 的,如果需要使用这种调度算法,必须安装 Nginx 的 hash 软件包。
- least_conn:最少连接负载均衡算法,简单来说就是每次选择的后端都是当前最少连接的一个 server(这个最少连接不是共享的,是每个 worker 都有自己的一个数组进行记录后端 server 的连接数)。
- hash:这个 hash 模块又支持两种模式 hash, 一种是普通的 hash, 另一种是一致性 hash(consistent)。
upstream 支持的状态参数
在 HTTP Upstream 模块中,可以通过 server 指令指定后端服务器的 IP 地址和端口,同时还可以设定每个后端服务器在负载均衡调度中的状态。常用的状态有:
- down:表示当前的 server 暂时不参与负载均衡。
- backup:预留的备份机器。当其他所有的非 backup 机器出现故障或者忙的时候,才会请求 backup 机器,因此这台机器的压力最轻。
- max_fails:允许请求失败的次数,默认为 1 。当超过最大次数时,返回 proxy_next_upstream 模块定义的错误。
- fail_timeout:在经历了 max_fails 次失败后,暂停服务的时间。max_fails 可以和 fail_timeout 一起使用。
当负载调度算法为 ip_hash 时,后端服务器在负载均衡调度中的状态不能是 backup。
配置 Nginx 负载均衡
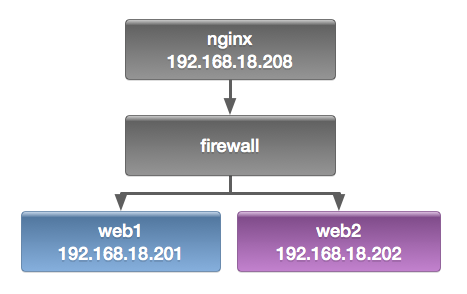
Nginx 配置负载均衡
upstream webservers {
server 192.168.18.201 weight=1;
server 192.168.18.202 weight=1;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_pass http://webservers;
proxy_set_header X-Real-IP $remote_addr;
}
}
注,upstream 是定义在 server{ } 之外的,不能定义在 server{ } 内部。定义好 upstream 之后,用 proxy_pass 引用一下即可。
重新加载一下配置文件
# service nginx reload
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
# curl http://192.168.18.208
web1.test.com
# curl http://192.168.18.208
web2.test.com
# curl http://192.168.18.208
web1.test.com
# curl http://192.168.18.208
web2.test.com
注,大家可以不断的刷新浏览的内容,可以发现 web1 与 web2 是交替出现的,达到了负载均衡的效果。
查看一下Web访问服务器日志
Web1:
# tail /var/log/nginx/access_log
192.168.18.138 - - [04/Sep/2013:09:41:58 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:41:58 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:41:59 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:41:59 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:42:00 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:42:00 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:42:00 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:44:21 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:44:22 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:44:22 +0800] "GET / HTTP/1.0" 200 23 "-"
Web2:
先修改一下,Web 服务器记录日志的格式。
# LogFormat "%{X-Real-IP}i %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
# tail /var/log/nginx/access_log
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:28 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:29 +0800] "GET / HTTP/1.0" 200 23 "-"
192.168.18.138 - - [04/Sep/2013:09:50:29 +0800] "GET / HTTP/1.0" 200 23 "-"
注,大家可以看到,两台服务器日志都记录是 192.168.18.138 访问的日志,也说明了负载均衡配置成功。
配置 Nginx 进行健康状态检查
利用 max_fails、fail_timeout 参数,控制异常情况,示例配置如下:
upstream webservers {
server 192.168.18.201 weight=1 max_fails=2 fail_timeout=2;
server 192.168.18.202 weight=1 max_fails=2 fail_timeout=2;
}
重新加载一下配置文件:
# service nginx reload
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
重新载入 nginx: [确定]
先停止 Web1,进行测试:
# service nginx stop
停止 nginx: [确定]
# curl http://192.168.18.208
web2.test.com
# curl http://192.168.18.208
web2.test.com
# curl http://192.168.18.208
web2.test.com
注,大家可以看到,现在只能访问 Web2,再重新启动 Web1,再次访问一下。
# service nginx start
正在启动 nginx: [确定]
# curl http://192.168.18.208
web1.test.com
# curl http://192.168.18.208
web2.test.com
# curl http://192.168.18.208
web1.test.com
# curl http://192.168.18.208
web2.test.com
PS:大家可以看到,现在又可以重新访问,说明 Nginx 的健康状态查检配置成功。但大家想一下,如果不幸的是所有服务器都不能提供服务了怎么办,用户打开页面就会出现出错页面,那么会带来用户体验的降低,所以我们能不能像配置 LVS 是配置 sorry_server 呢,答案是可以的,但这里不是配置 sorry_server 而是配置 backup。
配置 backup 服务器
备份服务器配置:
server {
listen 8080;
server_name localhost;
root /data/www/errorpage;
index index.html;
}
index.html 文件内容:
# cat index.html
<h1>Sorry......</h1>
负载均衡配置:
upstream webservers {
server 192.168.18.201 weight=1 max_fails=2 fail_timeout=2;
server 192.168.18.202 weight=1 max_fails=2 fail_timeout=2;
server 127.0.0.1:8080 backup;
}
重新加载配置文件:
# service nginx reload
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
重新载入 nginx: [确定]
关闭 Web 服务器并进行测试:
# service nginx stop
停止 nginx: [确定]
进行测试:
# curl http://192.168.18.208
<h1>Sorry......</h1>
# curl http://192.168.18.208
<h1>Sorry......</h1>
# curl http://192.168.18.208
<h1>Sorry......</h1>
注,大家可以看到,当所有服务器都不能工作时,就会启动备份服务器。好了,backup 服务器就配置到这里,下面我们来配置 ip_hash 负载均衡。
配置 ip_hash 负载均衡
ip_hash:每个请求按访问 IP 的 hash 结果分配,这样来自同一个 IP 的访客固定访问一个后端服务器,有效解决了动态网页存在的 session 共享问题,电子商务网站用的比较多。
# vim /etc/nginx/nginx.conf
upstream webservers {
ip_hash;
server 192.168.18.201 weight=1 max_fails=2 fail_timeout=2;
server 192.168.18.202 weight=1 max_fails=2 fail_timeout=2;
#server 127.0.0.1:8080 backup;
}
注,当负载调度算法为 ip_hash 时,后端服务器在负载均衡调度中的状态不能有 backup。有人可能会问,为什么呢?大家想啊,如果负载均衡把你分配到 backup 服务器上,你能访问到页面吗?不能,所以了不能配置 backup 服务器。
重新加载一下服务器:
# service nginx reload
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
重新载入 nginx: [确定]
测试一下:
# curl http://192.168.18.208
web2.test.com
# curl http://192.168.18.208
web2.test.com
# curl http://192.168.18.208
web2.test.com
注,大家可以看到,你不断的刷新页面一直会显示 Web2,说明 ip_hash 负载均衡配置成功。
OpenResty 环境搭建
Mac OS X 平台安装
从包管理安装
通过 Homebrew,OpenResty 提供了 OSX 上的 官方包。 你只需运行下面的命令:
brew install openresty/brew/openresty
如果你之前是从 homebrew/nginx 安装的 OpenResty,请先执行:
brew untap homebrew/nginx
如果一切顺利,OpenResty 应该已经安装好了。 接下来,我们就可以进入到后面的章节 HelloWorld 学习。
如果你想了解更多 OpenResty 上的细节,且不介意弄脏双手;抑或有自定义 OpenResty 安装的需求,可以往下看从源码安装的方式。
源码包准备(不适用太麻烦)
我们首先要在官网下载OpenResty的源码包。官网上会提供很多的版本,各个版本有什么不同也会有说明,我们可以按需选择下载。笔者选择下载的源码包 ngx_openresty-1.9.7.1.tar.gz。
相关库的安装
将这些相关库安装到系统中,推荐如 Homebrew 这类包管理方式完成包管理:
$ brew update
$ brew install pcre openssl
OpenResty 安装
- 在命令行中切换到源码包所在目录。
- 输入命令
tar xzvf ngx_openresty-1.9.7.1.tar.gz,按回车键解压源码包。若你下载的源码包版本不一样, 将相应的版本号改为你所下载的即可,或者直接拷贝源码包的名字到命令中。 此时当前目录下会出现一个ngx_openresty-1.9.7.1文件夹。 - 在命令行中切换工作目录到ngx_openresty-1.9.7.1。输入命令cd ngx_openresty-1.9.7.1。
- 配置安装目录及需要激活的组件。使用选项 --prefix=install_path ,指定其安装目录(默认为/usr/local/openresty)。 使用选项 --with-Components 激活组件, --without 则是禁止组件,你可以根据自己实际需要选择 with 及 without 。 输入如下命令,OpenResty 将配置安装在 /opt/openresty 目录下(注意使用root用户),激活 LuaJIT、HTTP_iconv_module 并禁止 http_redis2_module 组件。
./configure --prefix=/opt/openresty\ --with-cc-opt="-I/usr/local/include"\ --with-luajit\ --without-http_redis2_module \ --with-ld-opt="-L/usr/local/lib" - 在上一步中,最后没有什么error的提示就是最好的。若有错误,最后会显示error字样, 具体原因可以看源码包目录下的 build/nginx-VERSION/objs/autoconf.err 文件查看。 若没有错误,则会出现如下信息,提示下一步操作:
Type the following commands to build and install: make sudo make install - 编译。根据上一步命令提示,输入
make。 - 安装。输入
sudo make install,这里可能需要输入你的管理员密码。 - 上面的步骤顺利完成之后,安装已经完成。可以在你指定的安装目录下看到一些相关目录及文件。
设置环境变量
为了后面启动OpenResty的命令简单一些,不用在OpenResty的安装目录下进行启动,我们通过设置环境变量来简化操作。 将OpenResty目录下的 nginx/sbin 目录添加到 PATH 中。
OpenResty HelloWorld
创建工作目录
OpenResty 安装之后就有配置文件及相关的目录的,为了工作目录与安装目录互不干扰,并顺便学下简单的配置文件编写,我们另外创建一个 OpenResty 的工作目录来练习,并且另写一个配置文件。我选择在当前用户目录下创建 openresty-test 目录,并在该目录下创建 logs 和 conf 子目录分别用于存放日志和配置文件。
$ mkdir ~/openresty-test ~/openresty-test/logs/ ~/openresty-test/conf/
$
$ tree ~/openresty-test
/Users/yuansheng/openresty-test
├── conf
└── logs
2 directories, 0 files
创建配置文件
在 conf 目录下创建一个文本文件作为配置文件,命名为 nginx.conf,文件内容如下:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
server {
#监听端口,若你的6699端口已经被占用,则需要修改
listen 6699;
location / {
default_type text/html;
content_by_lua_block {
ngx.say("HelloWorld")
}
}
}
}
提示:如果你安装的是 openresty 1.9.3.1 及以下版本,请使用 content_by_lua 命令代替示例中的 content_by_lua_block。可使用 nginx -V 命令查看版本号。
万事俱备只欠东风
我们启动 Nginx 即可,输入命令形式为:nginx -p ~/openresty-test,如果没有提示错误。如果提示 nginx 不存在,则需要在环境变量中加入安装路径,可以根据你的操作平台,参考前面的安装章节(一般需要重启生效)。
启动成功后,我们可以查看 nginx 进程是否存在,并通过访问 HTTP 页面查看应答内容。操作提示如下:
➜ ~ nginx -p ~/openresty-test
➜ ~ ps -ef | grep nginx
501 88620 1 0 10:58AM ?? 0:00.00 nginx: master process nginx -p
/Users/yuansheng/openresty-test
501 88622 88620 0 10:58AM ?? 0:00.00 nginx: worker process
➜ ~ curl http://localhost:6699 -i
HTTP/1.1 200 OK
Server: openresty/1.9.7.3
Date: Sun, 20 Mar 2016 03:01:35 GMT
Content-Type: text/html
Transfer-Encoding: chunked
Connection: keep-alive
HelloWorld
在浏览器中完成同样的访问:
OpenResty 与其他 location 配合
紧接着,稍微扩充一下,并行请求的效果,示例如下:
location = /sum {
internal;
content_by_lua_block {
ngx.sleep(0.1)
local args = ngx.req.get_uri_args()
ngx.print(tonumber(args.a) + tonumber(args.b))
}
}
location = /subduction {
internal;
content_by_lua_block {
ngx.sleep(0.1)
local args = ngx.req.get_uri_args()
ngx.print(tonumber(args.a) - tonumber(args.b))
}
}
location = /app/test_parallels {
content_by_lua_block {
local start_time = ngx.now()
local res1, res2 = ngx.location.capture_multi( {
{"/sum", {args={a=3, b=8}}},
{"/subduction", {args={a=3, b=8}}}
})
ngx.say("status:", res1.status, " response:", res1.body)
ngx.say("status:", res2.status, " response:", res2.body)
ngx.say("time used:", ngx.now() - start_time)
}
}
location = /app/test_queue {
content_by_lua_block {
local start_time = ngx.now()
local res1 = ngx.location.capture_multi( {
{"/sum", {args={a=3, b=8}}}
})
local res2 = ngx.location.capture_multi( {
{"/subduction", {args={a=3, b=8}}}
})
ngx.say("status:", res1.status, " response:", res1.body)
ngx.say("status:", res2.status, " response:", res2.body)
ngx.say("time used:", ngx.now() - start_time)
}
}
测试结果:
➜ ~ curl 127.0.0.1/app/test_parallels
status:200 response:11
status:200 response:-5
time used:0.10099983215332
➜ ~ curl 127.0.0.1/app/test_queue
status:200 response:11
status:200 response:-5
time used:0.20199990272522
利用 ngx.location.capture_multi 函数,直接完成了两个子请求并行执行。当两个请求没有相互依赖,这种方法可以极大提高查询效率。两个无依赖请求,各自是 100ms,顺序执行需要 200ms,但通过并行执行可以在 100ms 完成两个请求。实际生产中查询时间可能没这么规整,但思想大同小异,这个特性是很有用的。
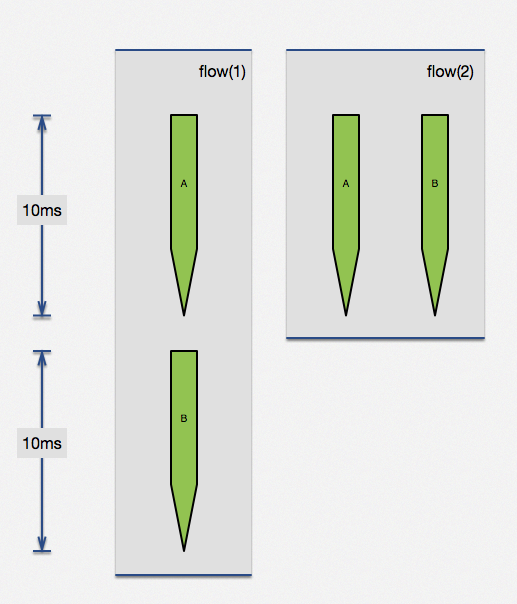
该方法,可以被广泛应用于广告系统(1:N模型,一个请求,后端从N家供应商中获取条件最优广告)、高并发前端页面展示(并行无依赖界面、降级开关等)。
流水线方式跳转
现在的网络请求,已经变得越来越拥挤。各种不同 API 、下载请求混杂在一起,就要求不同厂商对下载的动态调整有各种不同的定制策略,而这些策略在一天的不同时间段,规则可能还不一样。这时候我们还可以效仿工厂的流水线模式,逐层过滤、处理。
示例代码:
location ~ ^/static/([-_a-zA-Z0-9/]+).jpg {
set $image_name $1;
content_by_lua_block {
ngx.exec("/download_internal/images/"
.. ngx.var.image_name .. ".jpg");
};
}
location /download_internal {
internal;
# 这里还可以有其他统一的 download 下载设置,例如限速等
alias ../download;
}
注意,ngx.exec 方法与 ngx.redirect 是完全不同的,前者是个纯粹的内部跳转并且没有引入任何额外 HTTP 信号。 这里的两个 location 更像是流水线上工人之间的协作关系。第一环节的工人对完成自己处理部分后,直接交给第二环节处理人(实际上可以有更多环节),它们之间的数据流是定向的。

外部重定向
不知道大家什么时候开始注意的,百度的首页已经不再是 HTTP 协议,它已经全面修改到了 HTTPS 协议上。但是对于大家的输入习惯,估计还是在地址栏里面输入 baidu.com ,回车后发现它会自动跳转到 https://www.baidu.com ,这时候就需要的外部重定向了。
location = /foo {
content_by_lua_block {
ngx.say([[I am foo]])
}
}
location = / {
rewrite_by_lua_block {
return ngx.redirect('/foo');
}
}
执行测试,结果如下:
➜ ~ curl 127.0.0.1 -i
HTTP/1.1 302 Moved Temporarily
Server: openresty/1.9.3.2rc3
Date: Sun, 22 Nov 2015 11:04:03 GMT
Content-Type: text/html
Content-Length: 169
Connection: keep-alive
Location: /foo
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>openresty/1.9.3.2rc3</center>
</body>
</html>
➜ ~ curl 127.0.0.1/foo -i
HTTP/1.1 200 OK
Server: openresty/1.9.3.2rc3
Date: Sun, 22 Nov 2015 10:43:51 GMT
Content-Type: text/html
Transfer-Encoding: chunked
Connection: keep-alive
I am foo
当我们使用浏览器访问页面 http://127.0.0.1 就可以发现浏览器会自动跳转到 http://127.0.0.1/foo 。
OpenResty 获取 uri 参数
获取请求 uri 参数
首先看一下官方 API 文档,获取一个 uri 有两个方法:ngx.req.get_uri_args、ngx.req.get_post_args,二者主要的区别是参数来源有区别。
参考下面例子:
server {
listen 80;
server_name localhost;
location /print_param {
content_by_lua_block {
local arg = ngx.req.get_uri_args()
for k,v in pairs(arg) do
ngx.say("[GET ] key:", k, " v:", v)
end
ngx.req.read_body() -- 解析 body 参数之前一定要先读取 body
local arg = ngx.req.get_post_args()
for k,v in pairs(arg) do
ngx.say("[POST] key:", k, " v:", v)
end
}
}
}
输出结果:
➜ ~ curl '127.0.0.1/print_param?a=1&b=2%26' -d 'c=3&d=4%26'
[GET ] key:b v:2&
[GET ] key:a v:1
[POST] key:d v:4&
[POST] key:c v:3
从这个例子中,我们可以很明显看到两个函数 ngx.req.get_uri_args、ngx.req.get_post_args 获取数据来源是有明显区别的,前者来自 uri 请求参数,而后者来自 post 请求内容。
传递请求 uri 参数
当我们可以获取到请求参数,自然是需要这些参数来完成业务控制目的。大家都知道,URI 内容传递过程中是需要调用 ngx.encode_args 进行规则转义。
参看下面例子:
location /test {
content_by_lua_block {
local res = ngx.location.capture(
'/print_param',
{
method = ngx.HTTP_POST,
args = ngx.encode_args({a = 1, b = '2&'}),
body = ngx.encode_args({c = 3, d = '4&'})
}
)
ngx.say(res.body)
}
}
输出结果:
➜ ~ curl '127.0.0.1/test'
[GET] key:b v:2&
[GET] key:a v:1
[POST] key:d v:4&
[POST] key:c v:3
与我们预期是一样的。
如果这里不调用ngx.encode_args ,可能就会比较丑了,看下面例子:
local res = ngx.location.capture('/print_param',
{
method = ngx.HTTP_POST,
args = 'a=1&b=2%26', -- 注意这里的 %26 ,代表的是 & 字符
body = 'c=3&d=4%26'
}
)
ngx.say(res.body)
PS:对于 ngx.location.capture 这里有个小技巧,args 参数可以接受字符串或Lua 表的,这样我们的代码就更加简洁直观。
local res = ngx.location.capture('/print_param',
{
method = ngx.HTTP_POST,
args = {a = 1, b = '2&'},
body = 'c=3&d=4%26'
}
)
ngx.say(res.body)OpenResty 获取请求 body
在 Nginx 的典型应用场景中,几乎都是只读取 HTTP 头即可,例如负载均衡、正反向代理等场景。但是对于 API Server 或者 Web Application ,对 body 可以说就比较敏感了。由于 OpenResty 基于 Nginx ,所以天然的对请求 body 的读取细节与其他成熟 Web 框架有些不同。
最简单的 “Hello ****”
我们先来构造最简单的一个请求,POST 一个名字给服务端,服务端应答一个 “Hello ****”。
http {
server {
listen 80;
location /test {
content_by_lua_block {
local data = ngx.req.get_body_data()
ngx.say("hello ", data)
}
}
}
}
测试结果:
➜ ~ curl 127.0.0.1/test -d jack
hello nil
大家可以看到 data 部分获取为空,如果你熟悉其他 web 开发框架,估计立刻就觉得 OpenResty 弱爆了。查阅一下官方 wiki 我们很快知道,原来我们还需要添加指令 lua_need_request_body 。究其原因,主要是 Nginx 诞生之初主要是为了解决负载均衡情况,而这种情况,是不需要读取 body 就可以决定负载策略的,所以这个点对于 API Server 和 Web Application 开发的同学有点怪。
参看下面例子:
http {
server {
listen 80;
# 默认读取 body
lua_need_request_body on;
location /test {
content_by_lua_block {
local data = ngx.req.get_body_data()
ngx.say("hello ", data)
}
}
}
}
再次测试,符合我们预期:
➜ ~ curl 127.0.0.1/test -d jack
hello jack
如果你只是某个接口需要读取 body(并非全局行为),那么这时候也可以显示调用 ngx.req.read_body() 接口,参看下面示例:
http {
server {
listen 80;
location /test {
content_by_lua_block {
ngx.req.read_body()
local data = ngx.req.get_body_data()
ngx.say("hello ", data)
}
}
}
}
body 偶尔读取不到?
ngx.req.get_body_data() 读请求体,会偶尔出现读取不到直接返回 nil 的情况。
如果请求体尚未被读取,请先调用 ngx.req.read_body (或打开 lua_need_request_body 选项强制本模块读取请求体,此方法不推荐)。
如果请求体已经被存入临时文件,请使用 ngx.req.get_body_file 函数代替。
如需要强制在内存中保存请求体,请设置 client_body_buffer_size 和 client_max_body_size 为同样大小。
参考下面代码:
http {
server {
listen 80;
# 强制请求 body 到临时文件中(仅仅为了演示)
client_body_in_file_only on;
location /test {
content_by_lua_block {
function getFile(file_name)
local f = assert(io.open(file_name, 'r'))
local string = f:read("*all")
f:close()
return string
end
ngx.req.read_body()
local data = ngx.req.get_body_data()
if nil == data then
local file_name = ngx.req.get_body_file()
ngx.say(">> temp file: ", file_name)
if file_name then
data = getFile(file_name)
end
end
ngx.say("hello ", data)
}
}
}
}
测试结果:
➜ ~ curl 127.0.0.1/test -d jack
>> temp file: /Users/rain/Downloads/nginx/client_body_temp/0000000018
hello jackOpenResty 输出响应体
HTTP响应报文分为三个部分:
- 响应行
- 响应头
- 响应体

对于 HTTP 响应体的输出,在 OpenResty 中调用 ngx.say 或 ngx.print 即可。经过查看官方 wiki ,这两者都是输出响应体,区别是 ngx.say 会对输出响应体多输出一个 \n 。如果你用的是浏览器完成的功能调试,使用这两着是没有区别的。但是如果使用各种终端工具,这时候使用 ngx.say 明显就更方便了。
ngx.say 与 ngx.print 均为异步输出
首先需要明确一下的,是这两个函数都是异步输出的,也就是说当调用 ngx.say 后并不会立刻输出响应体。参考下面的例子:
server {
listen 80;
location /test {
content_by_lua_block {
ngx.say("hello")
ngx.sleep(3)
ngx.say("the world")
}
}
location /test2 {
content_by_lua_block {
ngx.say("hello")
ngx.flush() -- 显式的向客户端刷新响应输出
ngx.sleep(3)
ngx.say("the world")
}
}
}
测试接口可以观察到, /test 响应内容实在触发请求 3s 后一起接收到响应体,而 /test2 则是先收到一个 hello 停顿 3s 后又接收到后面的 the world。
再看下面的例子:
server {
listen 80;
lua_code_cache off;
location /test {
content_by_lua_block {
ngx.say(string.rep("hello", 1000))
ngx.sleep(3)
ngx.say("the world")
}
}
}
执行测试,可以发现首先收到了所有的 "hello" ,停顿大约 3 秒后,接着又收到了 "the world" 。
通过两个例子对比,可以知道,因为是异步输出,两个响应体的输出时机是 不一样 的。
如何优雅处理响应体过大的输出
如果响应体比较小,这时候相对就比较随意。但是如果响应体过大(例如超过 2G),是不能直接调用 API 完成响应体输出的。响应体过大,分两种情况:
- 输出内容本身体积很大,例如超过 2G 的文件下载
- 输出内容本身是由各种碎片拼凑的,碎片数量庞大,例如应答数据是某地区所有人的姓名
第①个情况,要利用 HTTP 1.1 特性 CHUNKED 编码来完成,一起来看看 CHUNKED 编码格式样例:

可以利用 CHUNKED 格式,把一个大的响应体拆分成多个小的应答体,分批、有节制的响应给请求方。
参考下面的例子:
location /test {
content_by_lua_block {
-- ngx.var.limit_rate = 1024*1024
local file, err = io.open(ngx.config.prefix() .. "data.db","r")
if not file then
ngx.log(ngx.ERR, "open file error:", err)
ngx.exit(ngx.HTTP_SERVICE_UNAVAILABLE)
end
local data
while true do
data = file:read(1024)
if nil == data then
break
end
ngx.print(data)
ngx.flush(true)
end
file:close()
}
}
按块读取本地文件内容(每次 1KB),并以流式方式进行响应。笔者本地文件 data.db 大小是 4G , Nginx 服务可以稳定运行,并维持内存占用在 几MB 范畴。
注:其实 nginx 自带的静态文件解析能力已经非常好了。这里只是一个例子,实际中过大响应体都是后端服务生成的,为了演示环境相对封闭,所以这里选择本地文件。
第②个情况,其实就是要利用 ngx.print 的特性了,它的输入参数可以是单个或多个字符串参数,也可以是 table 对象。
参考官方示例代码:
local table = {
"hello, ",
{"world: ", true, " or ", false,
{": ", nil}}
}
ngx.print(table)
将输出:
hello, world: true or false: nilOpenResty 日志输出
标准日志输出
OpenResty 的标准日志输出原句为 ngx.log(log_level, ...) ,几乎可以在任何 ngx_lua 阶段进行日志的输出。
请看下面的示例:
#user nobody;
worker_processes 1;
error_log logs/error.log error; # 日志级别
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
server {
listen 80;
location / {
content_by_lua_block {
local num = 55
local str = "string"
local obj
ngx.log(ngx.ERR, "num:", num)
ngx.log(ngx.INFO, " string:", str)
print([[i am print]])
ngx.log(ngx.ERR, " object:", obj)
}
}
}
}
访问网页,生成日志(logs/error.log 文件)结果如下:
2016/01/22 16:43:34 [error] 61610#0: *10 [lua] content_by_lua(nginx.conf:26):5:
num:55, client: 127.0.0.1, server: , request: "GET /hello HTTP/1.1",
host: "127.0.0.1"
2016/01/22 16:43:34 [error] 61610#0: *10 [lua] content_by_lua(nginx.conf:26):7:
object:nil, client: 127.0.0.1, server: , request: "GET /hello HTTP/1.1",
host: "127.0.0.1"
大家可以在单行日志中获取很多有用的信息,例如:时间、日志级别、请求ID、错误代码位置、内容、客户端 IP 、请求参数等等,这些信息都是环境信息,可以用来辅助完成更多其他操作。当然我们也可以根据自己需要定义日志格式,具体可以参考 nginx 的 log_format 章节。
细心的读者发现了,中间的两行日志哪里去了?这里不卖关子,其实是日志输出级别的原因。上面的例子,日志输出级别使用的 error,只有等于或大于这个级别的日志才会输出。这里还有一个知识点就是 OpenResty 里面的 print 语句是 INFO 级别。
有关 Nginx 的日志级别,请看下表:
ngx.STDERR -- 标准输出
ngx.EMERG -- 紧急报错
ngx.ALERT -- 报警
ngx.CRIT -- 严重,系统故障,触发运维告警系统
ngx.ERR -- 错误,业务不可恢复性错误
ngx.WARN -- 告警,业务中可忽略错误
ngx.NOTICE -- 提醒,业务比较重要信息
ngx.INFO -- 信息,业务琐碎日志信息,包含不同情况判断等
ngx.DEBUG -- 调试OpenResty 简单API Server框架
实现一个最最简单的数学计算:加、减、乘、除,给大家演示如何搭建简单的 API Server。
按照前面几章的写法,先来看看加法、减法示例代码:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
server {
listen 80;
# 加法
location /addition {
content_by_lua_block {
local args = ngx.req.get_uri_args()
ngx.say(args.a + args.b)
}
}
# 减法
location /subtraction {
content_by_lua_block {
local args = ngx.req.get_uri_args()
ngx.say(args.a - args.b)
}
}
# 乘法
location /multiplication {
content_by_lua_block {
local args = ngx.req.get_uri_args()
ngx.say(args.a * args.b)
}
}
# 除法
location /division {
content_by_lua_block {
local args = ngx.req.get_uri_args()
ngx.say(args.a / args.b)
}
}
}
}
代码写多了一眼就可以看出来,这么简单的加减乘除,居然写了这么长,而且还要对每个 API 都写一个 location ,作为有追求的人士,怎能容忍这种代码风格?
- 首先是需要把这些 location 合并;
- 其次是这些接口的实现放到独立文件中,保持 nginx 配置文件的简洁;
基于这两点要求,可以改成下面的版本,看上去有那么几分模样的样子:
nginx.conf 内容:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
# 设置默认 lua 搜索路径,添加 lua 路径
# 此处写相对路径时,对启动 nginx 的路径有要求,必须在 nginx 目录下启动,require 找不到
# comm.param 绝对路径当然也没问题,但是不可移植,因此应使用变量 $prefix 或
# ${prefix},OR 会替换为 nginx 的 prefix path。
# lua_package_path 'lua/?.lua;/blah/?.lua;;';
lua_package_path '$prefix/lua/?.lua;/blah/?.lua;;';
# 这里设置为 off,是为了避免每次修改之后都要重新 reload 的麻烦。
# 在生产环境上务必确保 lua_code_cache 设置成 on。
lua_code_cache off;
server {
listen 80;
# 在代码路径中使用nginx变量
# 注意: nginx var 的变量一定要谨慎,否则将会带来非常大的风险
location ~ ^/api/([-_a-zA-Z0-9/]+) {
# 准入阶段完成参数验证
access_by_lua_file lua/access_check.lua;
#内容生成阶段
content_by_lua_file lua/$1.lua;
}
}
}OpenResty 使用 Nginx 内置绑定变量
Nginx作为一个成熟、久经考验的负载均衡软件,与其提供丰富、完整的内置变量是分不开的,它极大增加了对Nginx网络行为的控制细度。这些变量大部分都是在请求进入时解析的,并把他们缓存到请求cycle中,方便下一次获取使用。首先来看看Nginx对都开放了那些API。
参看下表:
| 名称 | 说明 |
|---|---|
| $arg_name | 请求中的name参数 |
| $args | 请求中的参数 |
| $binary_remote_addr | 远程地址的二进制表示 |
| $body_bytes_sent | 已发送的消息体字节数 |
| $content_length | HTTP请求信息里的"Content-Length" |
| $content_type | 请求信息里的"Content-Type" |
| $document_root | 针对当前请求的根路径设置值 |
| $document_uri | 与$uri相同; 比如 /test2/test.php |
| $host | 请求信息中的"Host",如果请求中没有Host行,则等于设置的服务器名 |
| $hostname | 机器名使用 gethostname系统调用的值 |
| $http_cookie | cookie 信息 |
| $http_referer | 引用地址 |
| $http_user_agent | 客户端代理信息 |
| $http_via | 最后一个访问服务器的Ip地址。 |
| $http_x_forwarded_for | 相当于网络访问路径 |
| $is_args | 如果请求行带有参数,返回“?”,否则返回空字符串 |
| $limit_rate | 对连接速率的限制 |
| $nginx_version | 当前运行的nginx版本号 |
| $pid | worker进程的PID |
| $query_string | 与$args相同 |
| $realpath_root | 按root指令或alias指令算出的当前请求的绝对路径。其中的符号链接都会解析成真是文件路径 |
| $remote_addr | 客户端IP地址 |
| $remote_port | 客户端端口号 |
| $remote_user | 客户端用户名,认证用 |
| $request | 用户请求 |
| $request_body | 这个变量(0.7.58+)包含请求的主要信息。在使用proxy_pass或fastcgi_pass指令的location中比较有意义 |
| $request_body_file | 客户端请求主体信息的临时文件名 |
| $request_completion | 如果请求成功,设为"OK";如果请求未完成或者不是一系列请求中最后一部分则设为空 |
| $request_filename | 当前请求的文件路径名,比如/opt/nginx/www/test.php |
| $request_method | 请求的方法,比如"GET"、"POST"等 |
| $request_uri | 请求的URI,带参数 |
| $scheme | 所用的协议,比如http或者是https |
| $server_addr | 服务器地址,如果没有用listen指明服务器地址,使用这个变量将发起一次系统调用以取得地址(造成资源浪费) |
| $server_name | 请求到达的服务器名 |
| $server_port | 请求到达的服务器端口号 |
| $server_protocol | 请求的协议版本,"HTTP/1.0"或"HTTP/1.1" |
| $uri | 请求的URI,可能和最初的值有不同,比如经过重定向之类的 |
其实这还不是全部,Nginx在不停迭代更新是一个原因,还有一个是有些变量太冷门,借助它们,会有很多玩法。
首先,在OpenResty中如何引用这些变量呢?参考 ngx.var.VARIABLE 小节。
利用这些内置变量,来做一个简单的数学求和运算例子:
server {
listen 80;
server_name localhost;
location /sum {
#处理业务
content_by_lua_block {
local a = tonumber(ngx.var.arg_a) or 0
local b = tonumber(ngx.var.arg_b) or 0
ngx.say("sum: ", a + b )
}
}
}
验证一下:
➜ ~ curl 'http://127.0.0.1/sum?a=11&b=12'
sum: 23
也许你笑了,这个API太简单没有实际意义。我们做个简易防火墙,看看如何开始玩耍。
参看下面示例代码:
server {
listen 80;
server_name localhost;
location /sum {
# 使用access阶段完成准入阶段处理
access_by_lua_block {
local black_ips = {["127.0.0.1"]=true}
local ip = ngx.var.remote_addr
if true == black_ips[ip] then
ngx.exit(ngx.HTTP_FORBIDDEN)
end
};
#处理业务
content_by_lua_block {
local a = tonumber(ngx.var.arg_a) or 0
local b = tonumber(ngx.var.arg_b) or 0
ngx.say("sum:", a + b )
}
}
}OpenResty 子查询
例如,发送一个 POST 子请求,可以这样做:
res = ngx.location.capture(
'/foo/bar',
{ method = ngx.HTTP_POST, body = 'hello, world' }
)
除了 POST 的其他 HTTP 请求方法请参考 HTTP method constants。 method 选项默认值是 ngx.HTTP_GET。
args 选项可以设置附加的 URI 参数,例如:
ngx.location.capture('/foo?a=1',
{ args = { b = 3, c = ':' } }
)OpenResty 防止 SQL 注入
SQL 注入例子
下面给了一个完整的可复现的 SQL 注入例子,实际上注入的 SQL 语句写法有很多,下例是比较简单的。
location /test {
content_by_lua_block {
local mysql = require "resty.mysql"
local db, err = mysql:new()
if not db then
ngx.say("failed to instantiate mysql: ", err)
return
end
db:set_timeout(1000) -- 1 sec
local ok, err, errno, sqlstate = db:connect{
host = "127.0.0.1",
port = 3306,
database = "ngx_test",
user = "ngx_test",
password = "ngx_test",
max_packet_size = 1024 * 1024 }
if not ok then
ngx.say("failed to connect: ", err, ": ", errno, " ", sqlstate)
return
end
ngx.say("connected to mysql.")
local res, err, errno, sqlstate =
db:query("drop table if exists cats")
if not res then
ngx.say("bad result: ", err, ": ", errno, ": ", sqlstate, ".")
return
end
}
}
OpenResty 如何发起新 HTTP 请求
OpenResty 最主要的应用场景之一是 API Server,有别于传统 Nginx 的代理转发应用场景,API Server 中心内部有各种复杂的交易流程和判断逻辑,学会高效的与其他 HTTP Server 调用是必备基础。本文将介绍 OpenResty 中两个最常见 HTTP 接口调用方法。
我们先来模拟一个接口场景,一个公共服务专门用来对外提供加了“盐” md5 计算,业务系统调用这个公共服务完成业务逻辑,用来判断请求本身是否合法。
利用 proxy_pass
参考下面示例,利用 proxy_pass 完成 HTTP 接口访问的成熟配置+调用方法。
http {
upstream md5_server{
server 127.0.0.1:81; # ①
keepalive 20; # ②
}
server {
listen 80;
location /test {
content_by_lua_block {
ngx.req.read_body()
local args, err = ngx.req.get_uri_args()
-- ③
local res = ngx.location.capture('/spe_md5',
{
method = ngx.HTTP_POST,
body = args.data
}
)
if 200 ~= res.status then
ngx.exit(res.status)
end
if args.key == res.body then
ngx.say("valid request")
else
ngx.say("invalid request")
end
}
}
location /spe_md5 {
proxy_pass http://md5_server; -- ④
#For HTTP, the proxy_http_version directive should be set to “1.1” and the “Connection”
#header field should be cleared.(from:http://nginx.org/en/docs/http/ngx_http_upstream_module.html#keepalive)
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
server {
listen 81; -- ⑤
location /spe_md5 {
content_by_lua_block {
ngx.req.read_body()
local data = ngx.req.get_body_data()
ngx.print(ngx.md5(data .. "*&^%$#$^&kjtrKUYG"))
}
}
}
}
重点说明: ① 上游访问地址清单(可以按需配置不同的权重规则); ② 上游访问长连接,是否开启长连接,对整体性能影响比较大(大家可以实测一下); ③ 接口访问通过 ngx.location.capture 的子查询方式发起; ④ 由于 ngx.location.capture 方式只能是 nginx 自身的子查询,需要借助 proxy_pass 发出 HTTP 连接信号; ⑤ 公共 API 输出服务;
这里大家可以看到,借用 nginx 周边成熟组件力量,为了发起一个 HTTP 请求,我们需要绕好几个弯子,甚至还有可能踩到坑(upstream 中长连接的细节处理),显然没有足够优雅,所以我们继续看下一章节。
利用 cosocket
立马开始我们的新篇章,给大家展示优雅的解决方式。
http {
server {
listen 80;
location /test {
content_by_lua_block {
ngx.req.read_body()
local args, err = ngx.req.get_uri_args()
local http = require "resty.http" -- ①
local httpc = http.new()
local res, err = httpc:request_uri( -- ②
"http://127.0.0.1:81/spe_md5",
{
method = "POST",
body = args.data,
}
)
if 200 ~= res.status then
ngx.exit(res.status)
end
if args.key == res.body then
ngx.say("valid request")
else
ngx.say("invalid request")
end
}
}
}
server {
listen 81;
location /spe_md5 {
content_by_lua_block {
ngx.req.read_body()
local data = ngx.req.get_body_data()
ngx.print(ngx.md5(data .. "*&^%$#$^&kjtrKUYG"))
}
}
}
}
重点解释: ① 引用 resty.http 库资源,它来自 github https://github.com/pintsized/lua-resty-http。 ② 参考 resty-http 官方 wiki 说明,我们可以知道 request_uri 函数完成了连接池、HTTP 请求等一系列动作。
题外话,为什么这么简单的方法我们还要求助外部开源组件呢?其实我也觉得这个功能太基础了,真的应该集成到 OpenResty 官方包里面,只不过目前官方默认包里还没有。
如果你的内部请求比较少,使用 ngx.location.capture+proxy_pass 的方式还没什么问题。但如果你的请求数量比较多,或者需要频繁的修改上游地址,那么 resty.http就更适合你。