kafka是一个高吞吐量得分布式发布订阅消息系统,解耦了消息生产者和消费者,与大数据框架spark配合使用,可以实现数据得实时流处理。 目前做大数据相关的项目,都会用到kafka消息系统。
目标:
1.了解mq消息系统概念
2.理解kafka消息系统的基本框架。
3.安装单机版kafka集群
4,使用shell命令创建topic.
5.使用consumer,Producer发送和接收信息。
kafka是一个分布式的流处理平台,具有以下特点:
1.支持消息的发布和订阅,类似rabbitmq,activemq等消息队列。
2.支持数据实时处理
3.能保证消息的可靠性投递
4.支持消息的持久化存储,并通过多副本分布式的存储方案来保证消息的容错。
5.高吞吐量,单broker可轻松处理数千分区以及每秒百万级的消息量。
kafaka的架构就是好比收发邮件, 小王发送邮件,发送邮件存储到邮件服务器,小李从邮件服务器中读取邮件。 类似的 生产者生产消息,将消息发送到kafka服务器,消费者消费消息。从kafaka服务器读取消息。这里的kafka服务器相当于一个中间人,用于存储生产者和消费者交互的数据(消息)
安装kafka集群
#切换到 opt 目录 cd /opt
#下载 Kafka 软件包到当前目录中 sudo wget https://labfile.oss.aliyuncs.com/courses/859/kafka_2.11-1.1.1.tgz
#查看目录 ll

接着运行如下命令:
# 解压 Kafka 软件包 sudo tar -zxvf kafka_2.11-1.1.1.tgz
# 重命名 Kafka 软件包文件夹名称为 kafka sudo mv kafka_2.11-1.1.1 kafka
#查看目录能看到kafka ll

依次接着运行如下命令:
#进入到kafka软件包的 config 目录 cd /opt/kafka/config
#列出当前 config 文件下的文件,可以看到有个 server.properties 文件 ll
#复制 server.properties 文件为 server-1.properties sudo cp server.properties server-1.properties
#复制 server.properties 文件为 server-2.properties sudo cp server.properties server-2.properties
到目前为止,我们下载了 Kafka 软件包,解压了 Kafka 软件包,重命名 Kafka 软件目录名称,复制了 Kafka 配置文件,下一步需要修改这三个配置文件,使其组成集群。
在修改这三个配置文件之前,我们需要先启动 zookeeper ,因为 Kafka 集群使用 Zookeeper 软件进行元数据信息的同步。在生产环境中,安装 Kafka 之前,需要先安装 Zookeeper。基于实验的目的,本次实验我们不再单独安装 Zookeeper 软件,而是使用 Kafka 自带的 Zookeeper 软件,从功能上讲,没有区别。
---- 依次运行如下命令,启动 Zookeeper:
#将kafka目录的执行权限授予当前用户 sudo chmod 777 -R /opt/kafka
#切换到启动 Zookeeper 命令所在的目录 cd /opt/kafka/bin
#使用上级目录中的 config 目录中的 zookeeper.perperties 配置文件,运行当前目录下的 zookeeper-server-start.sh 命令,启动 Kafka 软件包自带的 Zookeeper ./zookeeper-server-start.sh ../config/zookeeper.properties
不要关闭当前命令行终端,再打开一个新的命令行终端。
小技巧:
在运行命令前加 nohup ,并且在运行命令后加 & 。这样,这个命令就会以 Linux 后台进程运行,关闭当前命令行终端也无影响。
如运行:nohup ./zookeeper-server-start.sh ../config/server. properties & 命令,以后台进程启动 Zookeeper。
在新的命令行终端运行命令:
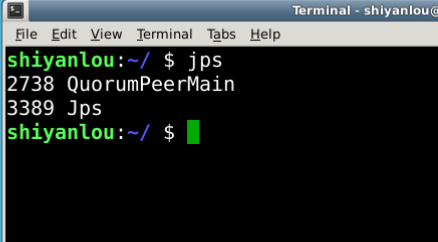
#查看当前运行的 java 进程,如果看到名称为 QuorumPeerMain 的进程,说明 Zookeeper 启动成功 jps
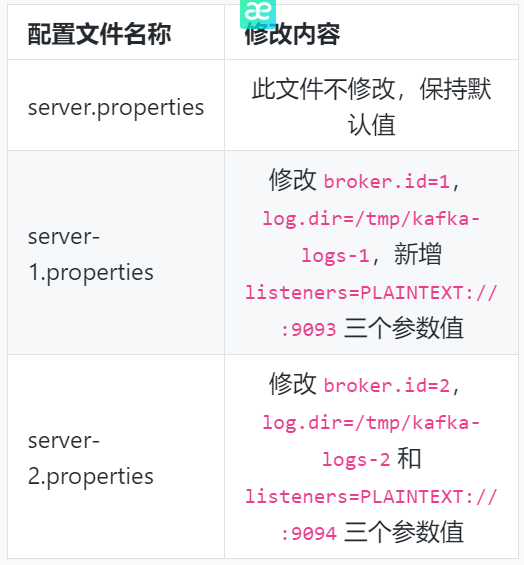
下面在新的命令行终端中编辑 Kafka 的三个配置文件(server.properties、 server-1.properties、server-2.properties),修改文件名和修改内容说明如下:
依次运行如下命令: #切换到配置文件所在目录 cd /opt/kafka/config
# 编辑server-1.properties vi server-1.properties
# 编辑server-2.properties vi server-2.properties
到这一步,参数修改完成,下一步,启动kafka集群,上面我们看到的Kafka配置文件,每个配置文件对应Kafka集群中的一个节点。(称为broker)
依次执行命令,启动Kafka集群 # 切换到kafka命令所在目录 cd /opt/kafka/bin # 使用配置文件启动第一个kafka broker,注意:命令最后的&表示以后台进程启动,启动完成后,按回车回到命令行。
./kafka-server-start.sh ../config/server.properties &
./kafka-server-start.sh ../config/server-1.properties &
./kafka-server-start.sh ../config/server-2.properties &
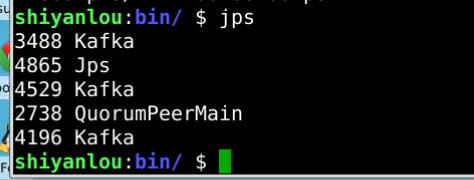
运行完成后,在命令行中输入jps,可以看到三个broker的kafka
到目前位置,单机版的三个Broker的kafka集群,已经安装成功。 现在我们知道,生产者生产消息,将消息发送到kafka服务器(实际存储到了kafka中topic里面),消费者消费消息,从kafka服务器读取消息。这里,kafka服务器相当于一个中间人,用于存储生产者和消费者交互的数据消息。
在kafka集群中创建topic 使用shell命令在kafka集群中创建一个Topic,名称为myFirstTopic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic myFirstTopic

在/opt/kafka/bin目录下运行命令,查看Topic 创建是否成功 ./kafka-topics.sh --zookeeper localhost:2181 --list

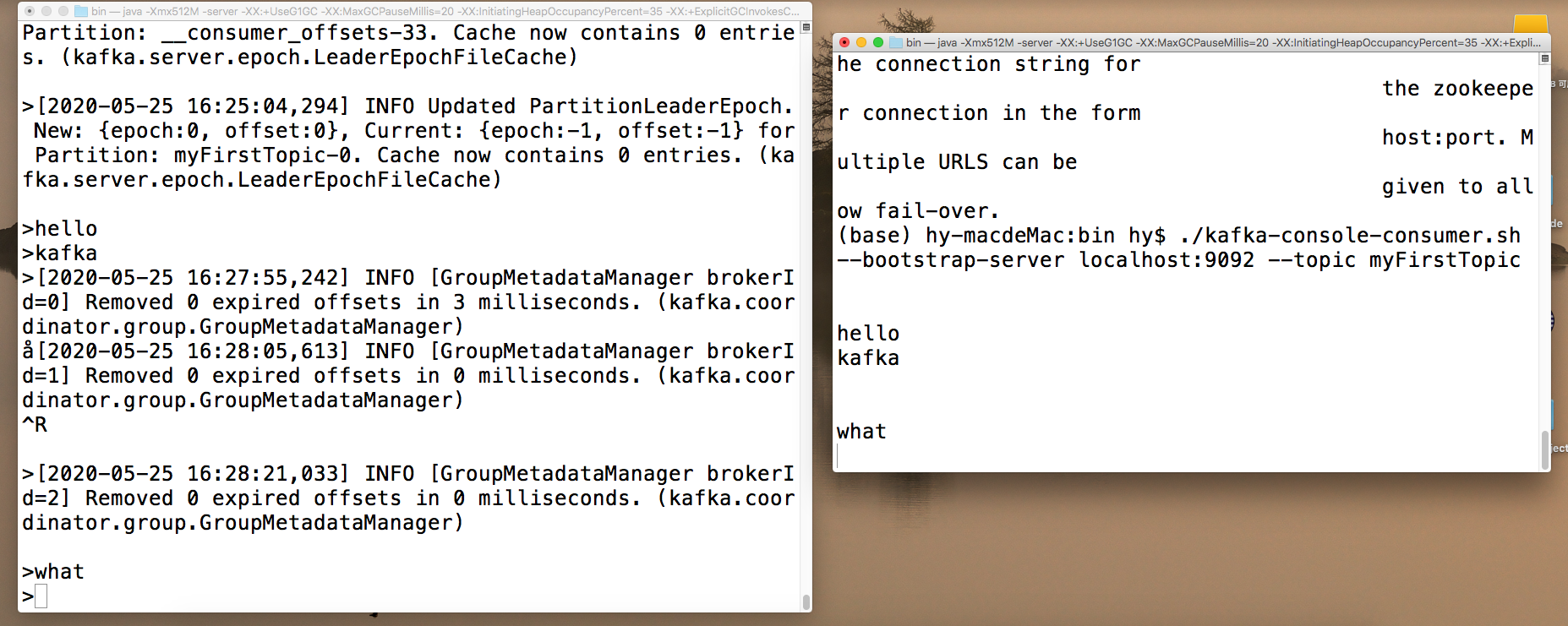
在/opt/kafka/bin目录下运行命令,启动消息生产者,用于向topic发送消息 ./kafka-console-producer.sh --broker-list localhost:9092 --topic myFirstTopic
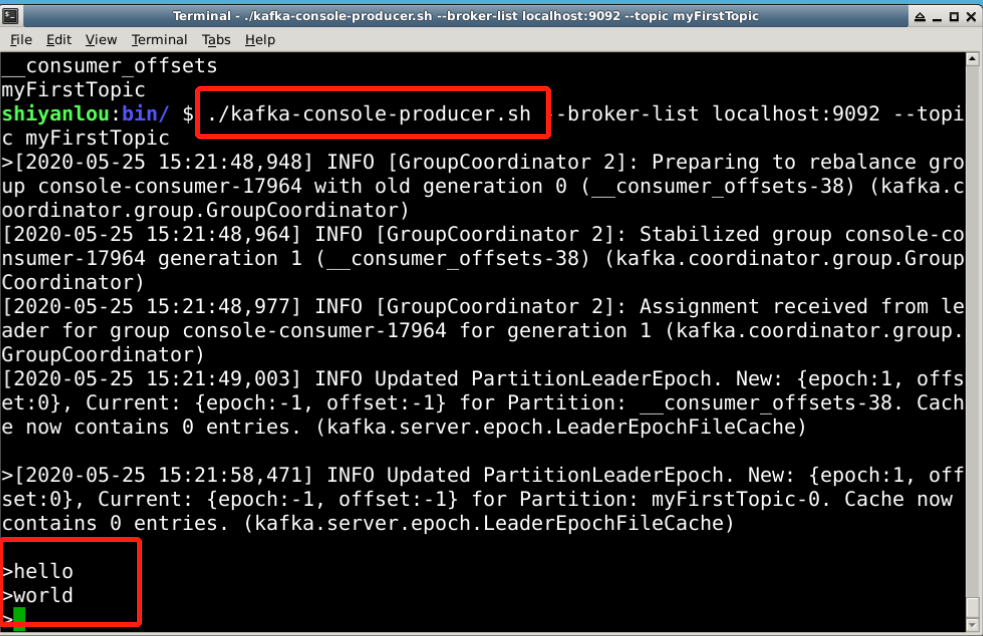
重新打开一个新的命令行终端,在/opt/kafka/bin目录下运行命令,启动消息消费者,用于向topic发送消息 ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic myFirstTopic

在mac中同样适用