哔哔一下
雪中悍刀行兄弟们都看过了吗?感觉看了个寂寞,但又感觉还行,原谅我没看过原著小说~
豆瓣评分5.8,说明我还是没说错它的。

当然,这并不妨碍它波播放量嘎嘎上涨,半个月25亿播放,平均一集一个亿,就是每天只有一集有点难受。
我们今天就来采集一下它的弹幕,实现数据可视化,看看弹幕文化都输出了什么~
我们将它的弹幕先采集下来,保存到Excel表格~
首先安装一下这两个模块
requests # 发送网络请求 pandas as pd # 保存数据
不会安装模块移步主页看我置顶文章,有专门详细讲解安装模块问题。
import requests # 发送网络请求 import pandas as pd # 保存数据 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36' } # 构建一个列表储存数据 data_list = [] for page in range(15, 1500, 30): try: url = f'https://mfm.video.qq.com/danmu?otype=json&target_id=7626435152%26vid%3Dp0041oidttf&session_key=0%2C174%2C1642248894×tamp={page}' # 1. 发送网络请求 response = requests.get(url=url, headers=headers) # 2. 获取数据 弹幕内容 <Response [200]>: 告诉我们响应成功 json_data = response.json() # print(json_data) # 3. 解析数据(筛选数据) 提取想要的一些内容 不想要的忽略掉 comments = json_data['comments'] for comment in comments: data_dict = {} data_dict['commentid'] = comment['commentid'] data_dict['content'] = comment['content'] data_dict['opername'] = comment['opername'] print(data_dict) data_list.append(data_dict) except: pass # 4. 保存数据 wps 默认以gbk的方式打开的 df = pd.DataFrame(data_list) # 乱码, 指定编码 为 utf-8 或者是 gbk 或者 utf-8-sig df.to_csv('data.csv', encoding='utf-8-sig', index=False)
#兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。 #那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码! #还会有大佬解答! #都在这个群里了 924040232 #欢迎加入,一起讨论 一起学习!

数据到手了,咱们就开始制作词云图分析了。
这两个模块需要安装一下
jieba
pyecharts
import jieba from pyecharts.charts import WordCloud import pandas as pd from pyecharts import options as opts wordlist = [] data = pd.read_csv('data.csv')['content'] data data_list = data.values.tolist() data_str = ' '.join(data_list) words = jieba.lcut(data_str) for word in words: if len(word) > 1: wordlist.append({'word':word, 'count':1}) df = pd.DataFrame(wordlist) dfword = df.groupby('word')['count'].sum() dfword2 = dfword.sort_values(ascending=False) dfword = df.groupby('word')['count'].sum() dfword2 = dfword.sort_values(ascending=False) dfword3['word'] = dfword3.index dfword3 word = dfword3['word'].tolist() count = dfword3['count'].tolist() a = [list(z) for z in zip(word, count)] c = ( WordCloud() .add('', a, word_size_range=[10, 50], shape='circle') .set_global_opts(title_opts=opts.TitleOpts(title="词云图")) ) c.render_notebook()
词云图效果

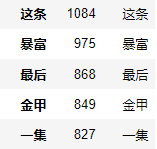
可以看到,这条、暴富和最后三个评论数据最多,咱们看看统计数据。
所有步骤都在视频有详细讲解
弹幕和词云图都有了,没有视频就说不过去,代码我整出来了,大家可以自己去试试,我就不展示了,展示了你们就看不到了。
import requests import re from tqdm import tqdm url = 'https://vd.l.qq.com/proxyhttp' data = { 'adparam': "pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fmzc0020036ro0ux%2Fc004159c18o.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fsearch%2F&ty=web&plugin=1.0.0&v=3.5.57&coverid=mzc0020036ro0ux&vid=c004159c18o&pt=&flowid=55e20b5f153b460e8de68e7a25ede1bc_10201&vptag=www_baidu_com%7Cx&pu=-1&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=58c04061fed6ba662bd7d4c4a7babf4f&req_type=1&from=0&appversion=1.0.171&uid=115600983&tkn=3ICG94Dn33DKf8LgTEl_Qw..<=qq&platform=10201&opid=03A0BB50713BC1C977C0F256056D2E36&atkn=75C3D1F2FFB4B3897DF78DB2CF27A207&appid=101483052&tpid=3&rfid=f4e2ed2359bc13aa3d87abb6912642cf_1642247026", 'buid': "vinfoad", 'vinfoparam': "spsrt=1&charge=1&defaultfmt=auto&otype=ojson&guid=58c04061fed6ba662bd7d4c4a7babf4f&flowid=55e20b5f153b460e8de68e7a25ede1bc_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fmzc0020036ro0ux%2Fc004159c18o.html&refer=v.qq.com&sphttps=1&tm=1642255530&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%2203A0BB50713BC1C977C0F256056D2E36%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2275C3D1F2FFB4B3897DF78DB2CF27A207%22%2C%22vuserid%22%3A%22115600983%22%2C%22vusession%22%3A%223ICG94Dn33DKf8LgTEl_Qw..%22%7D&vid=c004159c18o&defn=&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=1&encryptVer=9.1&cKey=1WuhcCc07Wp6JZEItZs_lpJX5WB4a2CdS8kEoQvxVaqtHEZQ1c_W6myJ8hQOnmDFHMUnGJTDNTvp2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2Op8F_DerfPItmE508flzsHwnEERQEN_AluNDEH6IC8EOljLQ2VfW2sTdospNPlD9535CNT9iSo3cLRH93ogtX_OJeYNVWrDYS8b5t1pjAAuGkoYGNScB_8lMah6WVCJtO-Ygxs9f-BtA8o_vOrSIjG_VH7z0wWI3--x_AUNIsHEG9zgzglpES47qAUrvH-0706f5Jz35DBkQKl4XAh32cbzm4aSDFig3gLiesH-TyztJ3B01YYG7cwclU8WtX7G2Y6UGD4Z1z5rYoM5NpAQ7Yr8GBgYGBgZKAPma&fp2p=1&spadseg=3" } headers = { 'cookie': 'pgv_pvid=7300130020; tvfe_boss_uuid=242c5295a1cb156d; appuser=BF299CB445E3A324; RK=6izJ0rkfNn; ptcz=622f5bd082de70e3e6e9a077923b48f72600cafd5e4b1e585e5f418570fa30fe; ptui_loginuin=1321228067; luin=o3452264669; lskey=000100003e4c51dfb8abf410ca319e572ee445f5a77020ba69d109f47c2ab3d67e58bd099a40c2294c41dbd6; o_cookie=3452264669; uid=169583373; fqm_pvqid=89ea2cc7-6806-4091-989f-5bc2f2cdea5c; fqm_sessionid=7fccc616-7386-4dd4-bba5-26396082df8d; pgv_info=ssid=s2517394073; _qpsvr_localtk=0.13663981383113954; login_type=2; vversion_name=8.2.95; video_omgid=d91995430fa12ed8; LCZCturn=798; lv_play_index=39; o_minduid=9ViQems9p2CBCM5AfqLWT4aEa-btvy40; LPSJturn=643; LVINturn=328; LPHLSturn=389; LZTturn=218; ufc=r24_7_1642333009_1642255508; LPPBturn=919; LPDFturn=470', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36' } response = requests.post(url=url, json=data, headers=headers) html_data = response.json()['vinfo'] print(html_data) m3u8_url = re.findall('url":"(.*?)",', html_data)[3] m3u8_data = requests.get(url=m3u8_url).text m3u8_data = re.sub('#E.*', '', m3u8_data).split() for ts in tqdm(m3u8_data): ts_1 = 'https://apd-327e87624fa9c6fc7e4593b5030502b1.v.smtcdns.com/vipts.tc.qq.com/AaFUPCn0gS17yiKCHnFtZa7vI5SOO0s7QXr0_3AkkLrQ/uwMROfz2r55goaQXGdGnC2de645-3UDsSmF-Av4cmvPV0YOx/svp_50112/vaemO__lrQCQrrgtQzL5v1kmLVKQZEaG2UBQO4eMRu4BAw6vBUoD1HAf7yUD8BtrL3NLr7bf9yrfSaqK5ufP8vmfEejwt0tuD8aNhyny1M-GJ8T1L1qi0R47t-v8KxV0ha-jJhALtc2N3tgRaTSfRwXwJ_vQObnhIdbyaVlJ2DzvMKoIlKYb_g/' ts_url = ts_1 + ts ts_content = requests.get(url=ts_url).content with open('斗破12.mp4', mode='ab') as f: f.write(ts_content) print('斗破下载完成')