读取:
一、CSV格式:
csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据。
1.csv模块&reader方法读取:
import csv
with open('enrollments.csv', 'rb') as f:
reader = csv.reader(f)
print reader
out:<_csv.reader object at 0x00000000063DAF48>
reader函数,接收一个可迭代的对象(比如csv文件),能返回一个生成器,就可以从其中解析出csv的内容:
比如下面的代码可以读取csv的全部内容,以行为单位:import csv
import csv
with open('enrollments.csv', 'rb') as f:
reader = csv.reader(f)
enrollments = list(reader)

import csv with open('enrollments.csv', 'rb') as f: reader = csv.reader(f)
enrollments=[row for row in reader]
print enrollments
#返回的类型都是:list
out:
[['account_key', 'status', 'join_date', 'cancel_date', 'days_to_cancel', 'is_udacity', 'is_canceled'],
['448', 'canceled', '2014-11-10', '2015-01-14', '65', 'True', 'True'],
['448', 'canceled', '2014-11-05', '2014-11-10', '5', 'True', 'True'],
['448', 'canceled', '2015-01-27', '2015-01-27', '0', 'True', 'True'],
[……]]
如果要提取其中的某一行,可以用下面的代码:
import csv with open('enrollments.csv','rb')as csvenroll: reader=csv.reader(csvenroll) for col,rows in enumerate(reader): if col==2: #提取第二行 row=rows print(row)
#返回list类型
out:['448', 'canceled', '2014-11-05', '2014-11-10', '5', 'True', 'True']
如果要提取其中的某一列,可以用以下代码:
import csv with open('enrollments.csv','rb')as csvenroll: reader=csv.reader(csvenroll) column=[row[2] for row in reader] #读取第三列 print(column)
#返回list类型
out:['join_date', '2014-11-10', '2014-11-05', '2015-01-27', '2014-11-10', '2015-03-10', '2015-01-14', '2015-01-27',……]
这种方法是通用的方法,要事先知道行/列号。这时可以采用第二种方法:DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。
用下面的代码可以看到DictReader的结构:
2.csv模块&DictReader方法读取:
import csv
with open('enrollments.csv', 'rb') as f: reader = csv.DictReader(f)
print reader
out:<unicodecsv.py2.DictReader instance at 0x0000000009AA07C8>
打印所有行:
import csv with open('enrollments.csv', 'rb') as f: reader = csv.DictReader(f) enrollments = list(reader)
import csv with open('enrollments.csv', 'rb') as f: reader = csv.DictReader(f) enrollments=[row for row in reader]
#返回整个list,list里面是dict
out:[{u'account_key': u'448',
u'cancel_date': u'2015-01-14',
u'days_to_cancel': u'65',
u'is_canceled': u'True',
u'is_udacity': u'True',
u'join_date': u'2014-11-10',
u'status': u'canceled'},
{'account_key': '448',
'cancel_date': '2014-11-10',
'days_to_cancel': '5',
'is_canceled': 'True',
'is_udacity': 'True',
'join_date': '2014-11-05',
'status': 'canceled'}……]
import csv with open('enrollments.csv', 'rb') as f: reader = csv.DictReader(f) for line in reader: print line
#返回dict
out:
{'status': 'canceled', 'is_udacity': 'True', 'is_canceled': 'True', 'join_date': '2014-11-10', 'account_key': '448', 'cancel_date': '2015-01-14', 'days_to_cancel': '65'}
{'status': 'canceled', 'is_udacity': 'True', 'is_canceled': 'True', 'join_date': '2014-11-05', 'account_key': '448', 'cancel_date': '2014-11-10', 'days_to_cancel': '5'}
……
如果要提取其中的某一行
同reader方法,根据行号提取,但是提取的结果与reader方法不同,dictreader方法读取结果是一个键对应一个value
import csv
with open('enrollments.csv','rb')as csvenroll:
reader=csv.DictReader(csvenroll)
for col,rows in enumerate(reader):
if col==0: #提取第一行
row=rows
print(row)
#返回dict类型
out:{'account_key': '448',
'cancel_date': '2015-01-14',
'days_to_cancel': '65',
'is_canceled': 'True',
'is_udacity': 'True',
'join_date': '2014-11-10',
'status': 'canceled'}
如果我们想用DictReader读取csv的满足特定值条件的某些行,就可以用列的标题查询:
eg:查找所有cancel_date是2015-01-14的行
import csv import pprint with open('enrollments.csv','rb')as f: reader=csv.DictReader(f) for line in reader: if line['cancel_date']=='2015-01-14': pprint.pprint(line)
#返回的line是dict类型
{'account_key': '448',
'cancel_date': '2015-01-14',
'days_to_cancel': '65',
'is_canceled': 'True',
'is_udacity': 'True',
'join_date': '2014-11-10',
'status': 'canceled'}
{'account_key': '60',
'cancel_date': '2015-01-14',
'days_to_cancel': '65',
'is_canceled': 'True',
'is_udacity': 'False',
'join_date': '2014-11-10',
'status': 'canceled'}{……}
读取某一列
import csv with open('enrollments.csv','rb')as f: reader=csv.DictReader(f) columns=[row['account_key'] for row in reader] #直接根据想要提取的列名称读取,不能根据列号读取 print(columns)
#返回list类型
out:['448', '448', '448', '448', '448', '448', '448', '448', '448', '700', '429', '429', '60', '60'……]
3.pandas模块读取
import pandas as pd data_df=pd.read_csv('enrollments.csv') print data_df
#返回dataframe类型
out: account_key status join_date cancel_date days_to_cancel 0 448 canceled 2014-11-10 2015-01-14 65.0 1 448 canceled 2014-11-05 2014-11-10 5.0 2 448 canceled 2015-01-27 2015-01-27 0.0 3 448 canceled 2014-11-10 2014-11-10 0.0 4 448 current 2015-03-10 NaN NaN 5 448 canceled 2015-01-14 2015-01-27 13.0 6 448 canceled 2015-01-27 2015-03-10 42.0 7 448 canceled 2015-01-27 2015-01-27 0.0 8 448 canceled 2015-01-27 2015-01-27 0.0 9 700 canceled 2014-11-10 2014-11-16 6.0
is_udacity is_canceled 0 True True 1 True True 2 True True 3 True True 4 True False 5 True True 6 True True 7 True True 8 True True 9 False True
读取某行:使用loc()方法
data_df.loc[1] #只要知道index即可,不一定非要知道行号
account_key 448 status canceled join_date 2014-11-05 cancel_date 2014-11-10 days_to_cancel 5 is_udacity True is_canceled True
读取某些行:
data_df.loc[:2]
读取某一列:
data_df['status'] #返回series类型
out:
0 canceled 1 canceled 2 canceled 3 canceled 4 current 5 canceled 6 canceled 7 canceled 8 canceled 9 canceled
读取某行某列的值:iloc()
data_df.iloc[0,2]
out:'2014-11-10'
二、excel格式
1.xlrd模块读取
import xlrd workbook=xlrd.open_workbook('enrollments.xls')
out:<xlrd.book.Book at 0xa8cbf98>
打印所有数据:
import xlrd import pprint #打开工作簿 workbook=xlrd.open_workbook('enrollments.xls') #选择工作表2(也就是工作簿中的第二个sheet) sheet=workbook.sheet_by_index(1) #遍历所有的列和行,并将所有的数据读取成python列表 data=[[sheet.cell_value(row,col) for col in range(sheet.ncols)] for row in range(sheet.nrows)] pprint.pprint(data)
#返回list类型
[[u'account_key',u'status',u'join_date',u'cancel_date',u'days_to_cancel',u'is_udacity',u'is_canceled'], [448.0, u'canceled', 41953.0, 42018.0, 65.0, 1, 1], [448.0, u'canceled', 41948.0, 41953.0, 5.0, 1, 1], [448.0, u'canceled', 42031.0, 42031.0, 0.0, 1, 1], [448.0, u'canceled', 41953.0, 41953.0, 0.0, 1, 1], [448.0, u'current', 42073.0, u'', u'', 1, 0], [448.0, u'canceled', 42018.0, 42031.0, 13.0, 1, 1], [448.0, u'canceled', 42031.0, 42073.0, 42.0, 1, 1], [448.0, u'canceled', 42031.0, 42031.0, 0.0, 1, 1], [448.0, u'canceled', 42031.0, 42031.0, 0.0, 1, 1], [700.0, u'canceled', 41953.0, 41959.0, 6.0, 0, 1], [429.0, u'canceled', 41953.0, 42073.0, 120.0, 0, 1]]
行/列的数量:
print sheet.nrows
print sheet.ncols
out:12
7
读取某行某列数据:
#打出刚刚生成列表中的第3行和第2列的值 data[3][2] #或者 sheet.cell_value(3,2)
读取某行的数据:
sheet.row_values(1,start_colx=0,end_colx=7) #读取第一行数据(不考虑表头),这里的start/end_colx可以更改,从而来获取某行从某列到某列的值
out:[448.0, u'canceled', 41953.0, 42018.0, 65.0, 1, 1]
读取某列数据:
print sheet.col_values(2,start_rowx=0,end_rowx=7) #读取第3列数据,1-6行
out:[u'join_date', 41953.0, 41948.0, 42031.0, 41953.0, 42073.0, 42018.0]
2.pandas模块读取
import pandas as pd workbook=pd.read_excel('enrollments.xls') #默认读取工作簿的sheet1 workbook
如果要读取第二个sheet:
import pandas as pd workbook=pd.read_excel('enrollments.xls',sheetname='Sheet2') workbook
读取行、列等方法同前。
三、xml格式
使用xml.etree.ElementTree模块
import xml.etree.ElementTree as ET import pprint tree=ET.parse('exampleResearchArticle.xml') root=tree.getroot() print 'children of root' #子元素 for child in root: print child.tag #使用标签属性来打印每个子元素的标签名
out:
children of root ui ji fm bdy bm
获取根元素里面的内容:
print "Authors' email addresses are as below:" for a in root.findall('./fm/bibl/aug/au'): #findall 会返回匹配该xpath表达式的所有元素 email=a.find('email') #对于每个元素,我们要进行“查找”以便定位 if email is not None: print email.text
out:
Authors' email addresses are as below: omer@extremegate.com mcarmont@hotmail.com laver17@gmail.com nyska@internet-zahav.net kammarh@gmail.com gideon.mann.md@gmail.com barns.nz@gmail.com eukots@gmail.com
四、html格式
使用beautifulsoup模块
from bs4 import BeautifulSoup soup=BeautifulSoup(open('virgin_and_logan_airport.html')) data=[] carrierlist=soup.find(id='CarrierList') for i in carrierlist.find_all('option'): #这里与xml的findall不同,需要用find_all data.append(i['value']) print 'carrierlist:{}'.format(data)
out:
carrierlist:['All', 'AllUS', 'AllForeign', 'AS', 'G4', 'AA', '5Y', 'DL', 'MQ', 'EV', 'F9', 'HA', 'B6', 'OO', 'WN', 'NK', 'UA', 'VX']
写入:
1.pandas模块——csv
import csv import pandas as pd titanic_df=pd.read_csv('titanic_data.csv') titanic_new=titanic_df.dropna(subset=['Age']) titanic_new.to_csv('titanic_new.csv') #保存到当前目录 titanic_new.to_csv('C:/asavefile/titanic_new.csv') #保存到其他目录
2.pandas模块——excel
to_excel
3.用csv模块,一行一行写入
1)从list写入
前文发现通过reader方法读取文件,返回的是list类型
import csv # 文件头,一般就是数据名 fileHeader = ["name", "score"] # 假设我们要写入的是以下两行数据 d1 = ["Wang", "100"] d2 = ["Li", "80"] # 写入数据 csvFile = open("C:/asavefile/instance.csv", "w") writer = csv.writer(csvFile) # 写入的内容都是以列表的形式传入函数 # 一行一行的写入 writer.writerow(fileHeader) writer.writerow(d1) writer.writerow(d1) csvFile.close()
import csv with open('test_writer1.csv','wb') as f: writer=csv.writer(f) #先写入表头 writer.writerow(['index','name','age','city']) #然后写入每行的内容 writer.writerows([(0,'sandra',12,'shanghai'), #用()或者[]好像没什么影响,所以数组和list均可? [1,'cheam',13,'beijing'], [2,'tom',14,'tianjin'], [3,'tina',15,'chongqing']])
out:
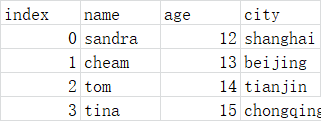
import csv csvfile = open('C:/asavefile/test_writer2.csv', 'wb') #打开方式还可以使用file对象 writer = csv.writer(csvfile) data = [['name', 'age', 'telephone'], ('Tom', '25', '1234567'), ('Sandra', '18', '789456')] #表头和内容一起写入 writer.writerows(data) csvfile.close()
明白了道理,用哪个都一样,用最后一种最简单
2)从dict写入
自己创建一张表:writer方法
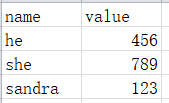
dic = {'sandra':123, 'he':456, 'she':789}
csvFile3 = open('C:/asavefile/csvFile3.csv','wb')
writer = csv.writer(csvFile3)
writer.writerow(['name','value'])
for key in dic:
writer.writerow([key, dic[key]])
csvFile3.close()
out:
完全复制一张表的内容:DictWriter方法
1 import csv
2 with open('C:/asavefile/enrollments.csv','rb') as f: #先打开需要复制的表格 3 reader=csv.DictReader(f) 4 line=[row for row in reader] 5 head=reader.fieldnames #reader方法没有fieldnames方法 6 csvFile = open("C:/asavefile/enrollments_copy.csv", "wb") 7 # 文件头以列表的形式传入函数,列表的每个元素表示每一列的标识 8 fileheader = head 9 dict_writer = csv.DictWriter(csvFile,fileheader) 10 # 但是如果此时直接写入内容,会导致没有数据名,所以,应先写数据名(也就是我们上面定义的文件头)。 11 # 写数据名,可以自己写如下代码完成: 12 dict_writer.writerow(dict(zip(fileheader,fileheader))) 13 # 之后,按照(属性:数据)的形式,将字典写入CSV文档即可 14 dict_writer.writerows(line) 15 csvFile.close()
将满足条件的值,写入到一张新表:
#将accountkey=448的挑选出来并保存到一个新的csv import csv with open('C:/asavefile/enrollments_accout.csv','wb') as outfile: with open('enrollments.csv', 'rb') as f: reader = csv.DictReader(f) #获取表头 head=reader.fieldnames writer=csv.DictWriter(outfile,head) #写入表头的名字 writer.writerow(dict(zip(head,head)))
#开始一行一行写入数据 for line in reader: if line['account_key']=='448': writer.writerow(line)
