(三) Redis高级特性
前面我们介绍了Redis的五种基本的数据类型,灵活运用这五种数据类型是使用Redis的基础,除此之外,Redis还有一些特性,掌握这些特性能对Redis有进一步的了解,比如Redis事务、Redis分区、Redis的数据备份等等。
1、Redis HyperLogLog
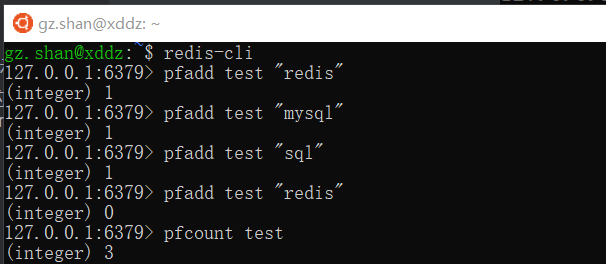
Redis从2.8.9版本开始加入了HyperLogLog,这听起来有点陌生,实际上它是一个用来做基数统计的算法(基数就是数据集中不重复的元素个数,比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数为5)。
Redis做基数统计有其特有的优势,在输入元素的数量或者体积非常非常大时,Redis计算基数所需的空间总是固定的、并且是很小的,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数,但是它只计算基数,并不储存输入元素本身。
2、Redis数据备份与恢复
Redis支持数据的备份,并可以从备份中恢复数据。这主要就是涉及到一个save命令。
当输入save命令时,将在redis安装目录穿件dump.rdb文件,此文件就是备份的数据。如果想恢复数据,只需要将dump.rdb移动到安装目录下,然后重新启动redis-server即可。因此,我们使用这样的数据备份和恢复可以很方便的对数据库进行迁移。
3、Redis安全和认证
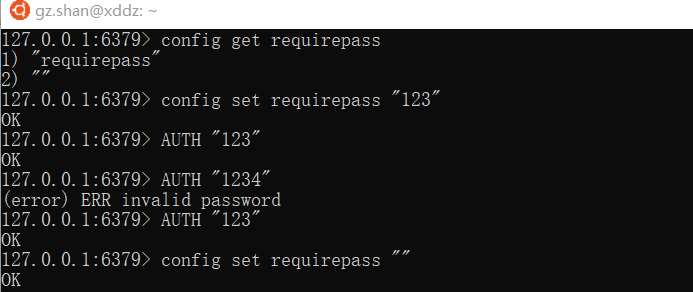
为了保证Redis服务的安全性,可以对redis添加密码,这样当客户端连接到redis服务时就需要输入密码进行验证,通过后才能连接。
Redis服务的密码是通过配置文件进行指定的,密码参数是配置文件中的requirepass,默认是空字符串,只需要更改此参数就可以设置密码,设置密码后需要进行auth认证才可以进行相应的操作。
4、Redis性能测试
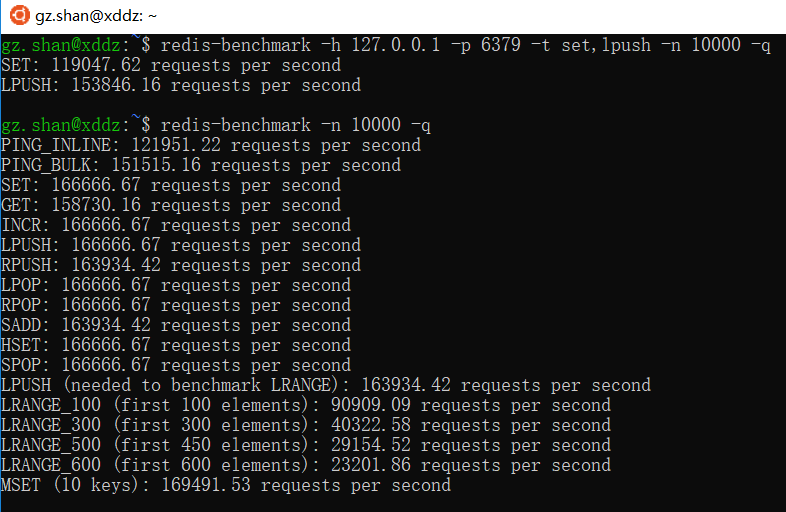
我们说Redis最大的一个特点是性能极高,读的速度是110000次/s,写的速度是81000次/s。Redis提供了一个性能测试工具redis-benchmark,通过同时执行多个命令来测试性能。这个测试工具有很多可选参数:-h(指定主机),-p(指定端口),-s(指定Socket),-c(指定并发连接数),-n(指定请求数),-d(指定set和get的值是多少个字节)等等。
5、Redis事务
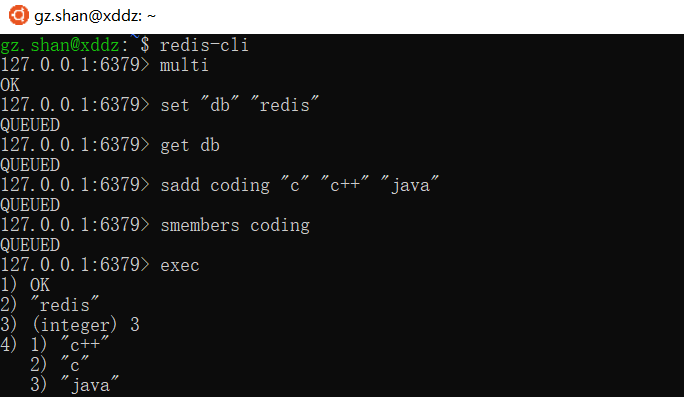
Redis事务允许客户端依次执行多个命令,并且符合以下规则:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:开始事务、命令入队、执行事务。具体地,先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令。
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
6、Redis发布和订阅
在另外一篇关于Kafka的博客:【Apache Kafka】 Kafka简介及其基本原理中,介绍了什么是消息队列,并对发布-订阅这种消息模式有相关的介绍,这里我们说Redis也可以用作简单的消息队列,发送者(pub)发送消息,订阅者(sub)接收消息。Redis 客户端可以订阅任意数量的频道,当有新消息发送到该频道时,客户端就可以收到消息。

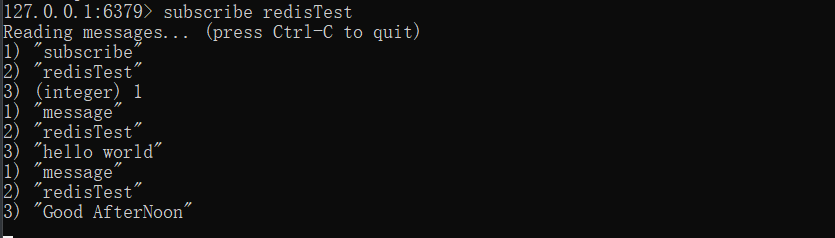

7、Redis管道技术
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 管道技术可以达到这样的效果:在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。

8、Redis分区
我们说Redis是一个分布式缓存、分布式数据库,那么到目前我们还没有看到其分布式体现在哪里,Redis数据保存在内存中,如果只有一台机器,很容易达到其存储上限。因此,Redis分区允许构建redis集群,将数据分别保存到多个Redis实例中去,每个实例保存key的一个子集,这样就可以利用更多的计算机来存储数据,从而构造更大的数据库。
除了数据量更大,Redis分区还可以带来更强大的计算能力和更高的网络带宽。
关于如何进行分区,Redis提供了两种类型。一种是范围分区,就是映射一定范围的对象到特定的Redis实例。比如,ID从0到10000的用户会保存到实例R0,ID从10001到 20000的用户会保存到R1,以此类推。还有一种方法是哈希分区,用一个hash函数将key转换为一个数字,对这个整数取模,转换到对应的Redis实例中的一个。
9、Redis持久化机制
Redis是一种内存数据库,为了保证数据不丢失,内存中的数据可以保存到磁盘中,重启的时候可以再次加载使用,这就是持久化。
Redis有两种持久化机制,默认使用的是RDB方式。
(1)RDB持久化(全量):通过快照的方式完成持久化,当符合一定条件时,Redis会自动将内存中的所有数据进行快照并保存到磁盘上去。这里的一定条件可以由用户来指定,由两个参数构成:时间和改动的键的个数,当在指定的时间内更改的键的个数大于指定的数值时就会进行快照。在配置文件中默认了三个条件(多个条件是或的关系):
save 900 1 # 意思是:在900秒(15分钟)内有至少一个键被更改则进行快照
save 300 10
save 60 10000
RDB实际操作过程是:fork 一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
RDB的优缺点:
RDB以快照的方式持久化,可以通过配置灵活设置备份频率和周期,非常适合冷备份和灾备,将快照复制到其他服务器就可以直接创建具有相同数据的服务器副本,性能好,恢复快。然而,其缺点是:系统一旦在持久化完成之前出现宕机,此前没有写到磁盘的数据都会丢失。
(2)AOF持久化(增量):AOF就是append only file,以日志文本的形式对每一个写、删除操作进行记录(查询无需记录)。但是这里也有一个优化,并不是每次就直接写磁盘,而是先进行缓存,由操作系统决定什么时候同步到磁盘去。所以有三种同步选项:
- always:每一次写都同步
- everysec:每秒同步一次
- no:操作系统来决定
AOF的优缺点:
AOF相比RDB可以带来更高的数据安全性,因为即使在未同步之前宕机也只是丢失一次或者一秒的数据。而且,append only的方式也避免了磁盘寻址,性能也比较高。其缺点在于:对相同的数据集来说,AOF文件通常会比较大,恢复速度要慢一些。