搭建HDFS高可用
在搭建hdfs高可用过程中,以node1、node2和node3来搭建高可用环境,每个节点所分配的作用如表4.3所示。
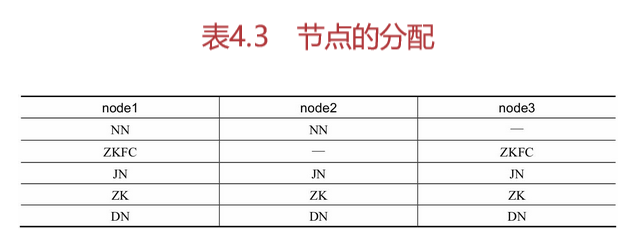
由表4.3中可以看出,NameNode(NN)分别配置在node1和node2上,ZKFC配置在node1和node3上,JournalNode(JN)配置在node1、node2和node3上,ZooKeeper(ZK)配置在node1、node2和node3上,DataNode(DN)配置在node1、node2和node3上。接下来开始高可用的搭建,首先来配置ZooKeeper。
配置ZooKeeper
首先从官网http://zookeeper.apache.org/下载ZooKeeper,这里以ZooKeeper-3.4.13为例,并上传到node1上。
解压缩ZooKeeper:
tar -zvxf ../appinstall/zookeeper-3.4.13.tar.gz
在ZooKeeper-3.4.13的conf文件夹下创建zoo.cfg文件并写入以下配置:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/opt/Zookeeper/data clientPort=2181 server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888
其中,dataDir代表存放ZooKeeper数据文件的目录,server.1、server.2和server.3中的1、2、3分别对应第1个节点、第2个节点和第3个节点,其中2888和3888代表接收和发送数据的端口。
创建myid,为了保障server.1、server.2和server.3,可以分别和第1个节点(node1)、第2个节点(node2)和第3个节点(node3)对应起来,还需要在dataDir所对应的文件夹中创建myid文件。具体操作如下。
在node1节点上创建/opt/ZooKeeper/data文件夹,并在其中创建myid文件。

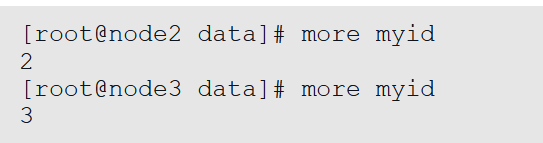
接着在myid文件中写入1,这样就和server.1对应起来了。通过more myid命令可以查看myid文件中的内容。

在node2和node3中的/opt/ZooKeeper/data下分别创建myid文件,并分别写入2和3,此处与node1操作类似,写入后分别通过more查看文件内容。
复制node1上的ZooKeeper到node2和node3节点上。

启动ZooKeeper。进入每个节点的ZooKeeper的bin目录并启动ZooKeeper,启动命令如下:
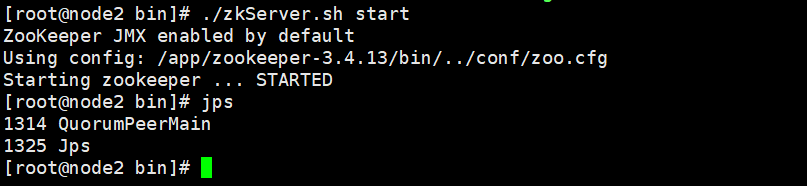
注意:每个节点都要单独启动
检查ZooKeeper是否配置成功,在每个节点输入jps命令查看进程,会发现有个QuorumPeerMain,这就是ZooKeeper的进程
这样就代表ZooKeeper集群已经配置成功。
配置Hadoop配置文件
Hadoop配置文件一共有4个,分别是:

hadoop-env.sh的配置,是关于Hadoop运行环境的配置,在配置高可用时,分别定义了JAVA_HOME及运行NameNode、DataNode、ZKFC和JournalNode进程的用户:
export JAVA_HOME=/app/jdk1.8.0_211
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
core-site.xml文件的配置如下:
<configuration> <!--默认文件系统名称--> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!--HDFS文件系统的元信息保存目录--> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoopdata</value> </property> <!--定义在网页界面访问数据时使用的用户名--> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!--故障转移需要的zookeeper集群--> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> </configuration>
其中,hadoop.http.staticuser.user是定义在网页界面访问数据时使用的用户名,ha.zookeeper.quorum是定义ZooKeeper集群(注意zookeeper要小写)。
hdfs-site.xml文件的配置如下:
<configuration> <!--完全分布式集群名称,和core-site集群名称必须一致--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--集群中NameNode节点都有哪些--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--nn1的RPC通信地址--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <!--nn2的RPC通信地址--> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> <!--nn1的http通信地址--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1:9870</value> </property> <!--nn2的http通信地址--> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2:9870</value> </property> <!--指定NameNode元数据在JournalNode上的存放位置--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/wen</value> </property> <!--客户端与活动状态的NameNode 进行交互的 Java 实现类--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置隔离机制,即同一时刻只能有一台服务器对外响应--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!--使用隔离机制时需要ssh无秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--声明journalnode服务器存储目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/journalnode/data</value> </property> <!--故障自动转移设置为true--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!--设置为false可以不用检查权限--> <property> <name>dfs.permission</name> <value>false</value> </property> </configuration>
其中,dfs.nameservices是配置HDFS集群ID,dfs.ha.namenodes.mycluster是配置NameNode的ID号,dfs.namenode.rpc-address.mycluster.nn1是定义NameNode的主机名和RPC协议的端口,dfs.namenode.http-address.mycluster.nn1是定义NameNode的主机名和HTTP协议的端口。
dfs.namenode.shared.edits.dir是定义共享edits的URL,dfs.client.failover.proxy.provider.mycluster是定义返回active namenode的类。
dfs.ha.fencing.methods是定义NameNode切换时的隔离方法,主要是为了防止“脑裂”问题,dfs.ha.fencing.ssh.private-key-files是定义隔离方法的密钥,dfs.journalnode.edits.dir是保存edits文件的目录,dfs.ha.automatic-failover.enabled用于定义开启自动切换。
workers文件的配置如下:
node1
node2
node3
workers主要配置DataNode节点,在workers配置文件中写入以上内容,代表node1、node2和node3是DataNode节点。
将配置文件复制到其他节点上
scp ./hadoop-env.sh root@node2:/app/hadoop-3.2.1/etc/hadoop/
scp ./hadoop-env.sh root@node3:/app/hadoop-3.2.1/etc/hadoop/
scp ./core-site.xml root@node3:/app/hadoop-3.2.1/etc/hadoop/
scp ./core-site.xml root@node2:/app/hadoop-3.2.1/etc/hadoop/
scp ./hdfs-site.xml root@node2:/app/hadoop-3.2.1/etc/hadoop/
scp ./hdfs-site.xml root@node3:/app/hadoop-3.2.1/etc/hadoop/
scp ./workers root@node2:/app/hadoop-3.2.1/etc/hadoop/
scp ./workers root@node3:/app/hadoop-3.2.1/etc/hadoop/
启动JN节点
启动JN节点,命令如下:
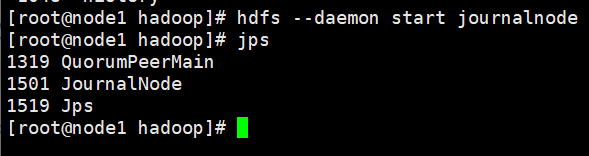
hdfs --daemon start journalnode
在node1、node2和node3上分别启动JournalNode,然后通过jps命令进行查看,这里以node1为例。代码如下:
格式化,在node1上执行格式化操作,执行命令如下:
hdfs namenode -format
复制元数据到node2节点上
由于我们需要把node1和node2设置为两个NameNode,所以搭建高可用时要求node1和node2上的元数据是一样的,因此需要将node1上的元数据复制到node2上。在这里需要注意的是,执行格式化命令后,会在/opt/hadoopdata目录下生成元数据,执行命令如下:
scp -r /opt/hadoopdata root@node2:/opt/
格式化ZKFC
ZKFC(ZooKeeper Failover Controller)是在HDFS高可用前提下,基于ZooKeeper的自动切换原理触发NameNode切换的一个进程。
在NameNode节点上启动的ZKFC进程内部,运行着如下3个对象服务。
·HealthMonitor:定期检查NameNode是否不可用或是否进入了一个不健康的状态,并及时通知ZooKeeper Failover Controller。
·ActiveStandbyElector:控制和监控NameNode在ZooKeeper上的状态。
·ZKFailoverController:协调HealthMonitor和ActiveStandbyElector对象并处理它们通知的event变化事件,完成自动切换的过程。
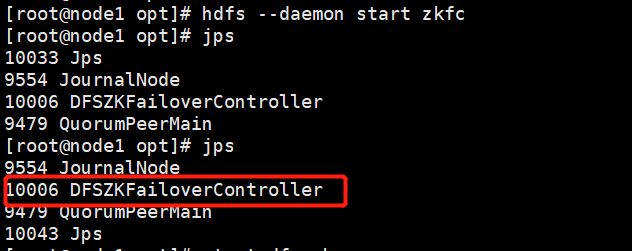
通 hdfs zkfc -formatZK 命令格式化ZKFC(ZooKeeper Failover Controller),执行命令如下:

启动ZKF,hdfs --daemon start zkfc ,启动后jps,DFSZKFailoverController进程启动表示成功,如下表示启动成功(若namenode2没有启动成功,可在namenode2手动启动zkfc)
启动集群
执行start-dfs.sh命令启动集群:
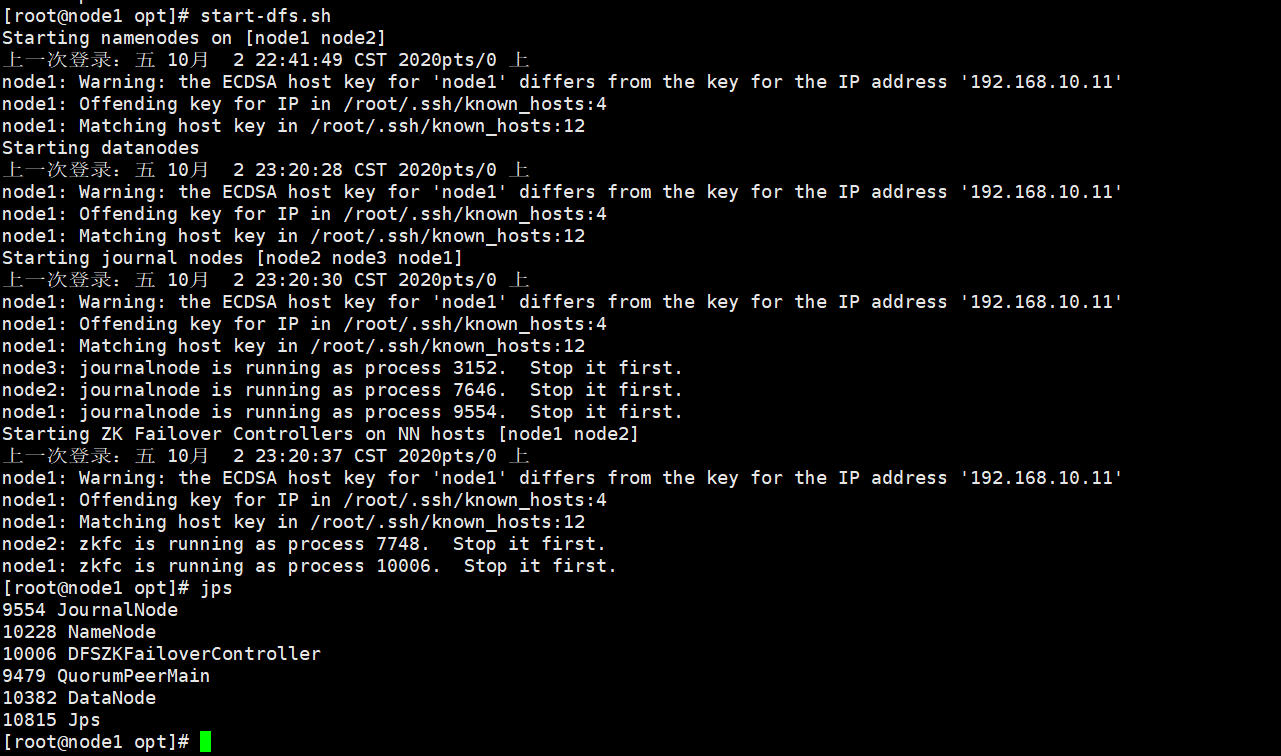
从上面的提示中可以看出node1和node2作为HDFS高可用的NameNode,node1、node2和node3作为用来保证NameNode间数据共享的JournalNode。
通过浏览器查看集群状态
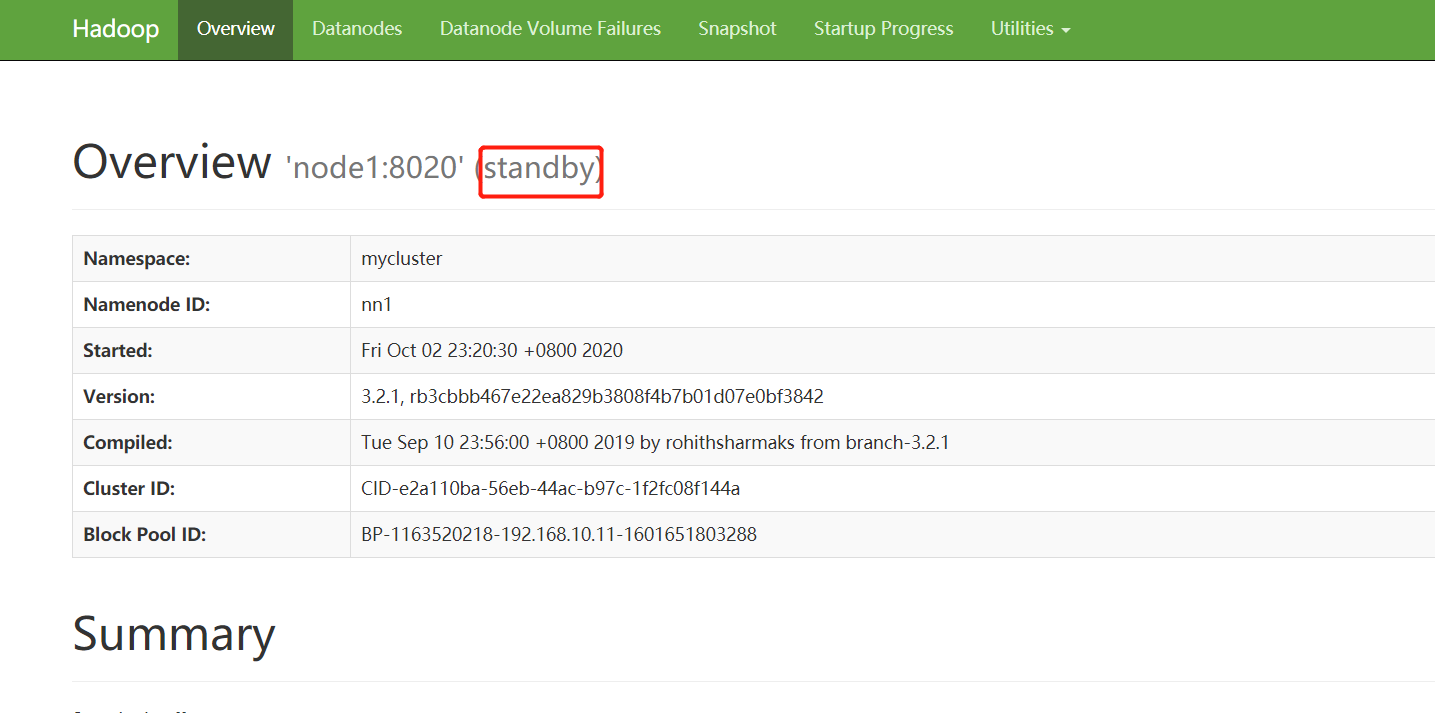
在浏览器中分别打开http://192.168.10.11:9870/和http://192.168.10.12:9870/,会看到下面两个界面,可以看出node2为active状态,node1是standby状态,如图所示。
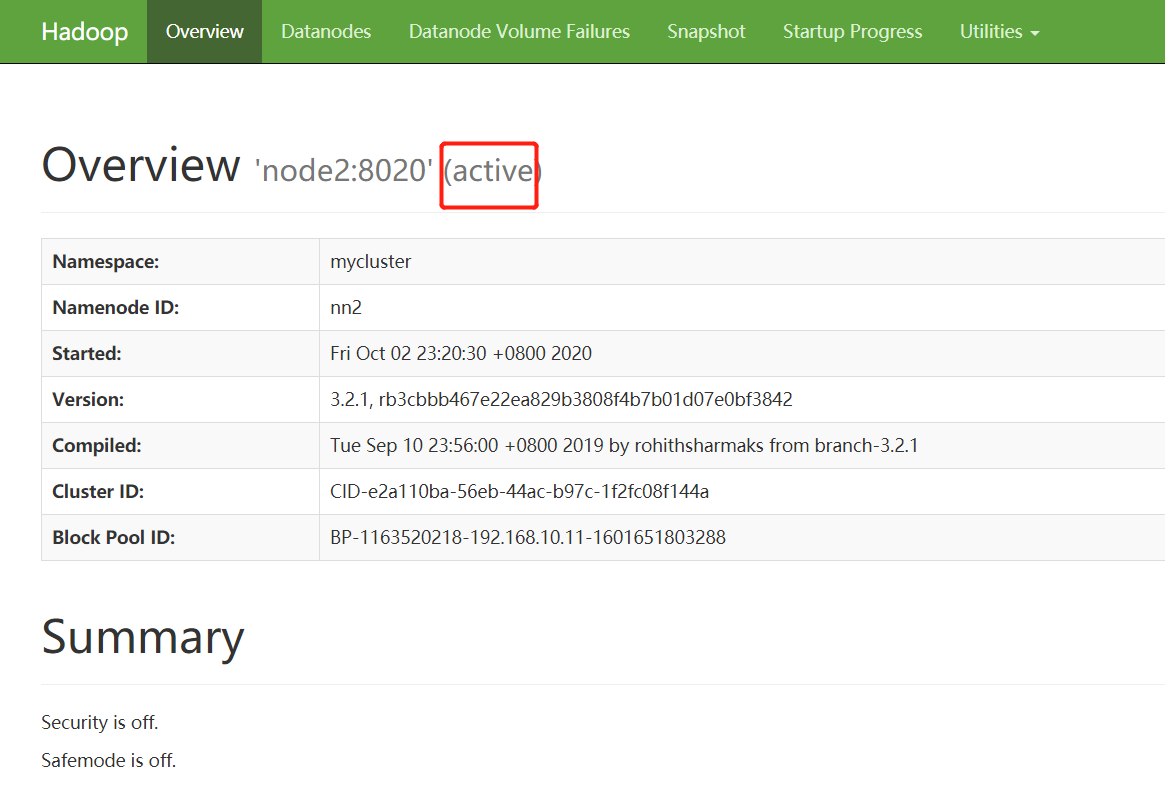
高可用测试
目前node1是standby(备用)状态,node2是active(活跃)状态,现在我们先查看NameNode进程的ID号,随后杀死在node2中处于active状态的NameNode进程,测试当此节点失效时,备用NameNode(即node1)能否接管已失效节点的任务并开始服务于来自客户端的请求,命令如下:
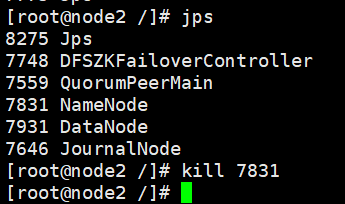
接着我们打开node1,发现node1的状态已经变成了active状态,如图4.12所示。这样,关于Hadoop 3的高可用就配置成功了。关于高可用的配置,读者可以参考官网http://hadoop.apache.org/docs/r3.1.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailability WithQJM.html。
