进程的调度:
.dll 库 .lib 库文件 .bat批处理脚本文件 .out Linux系统中的执行文件 .exe 可执行文件,双击能运行的文件 .sh shell脚本文件
进程:是指正在执行的程序,是程序执行过程中的一次指令,也可以叫做程序一次执行过程.是一个动态的概念
进程由三大部分组成:代码段,数据段,PUB(进程控制块):进程管理控制
进程的特征:动态性,并发性,独立性,异步性
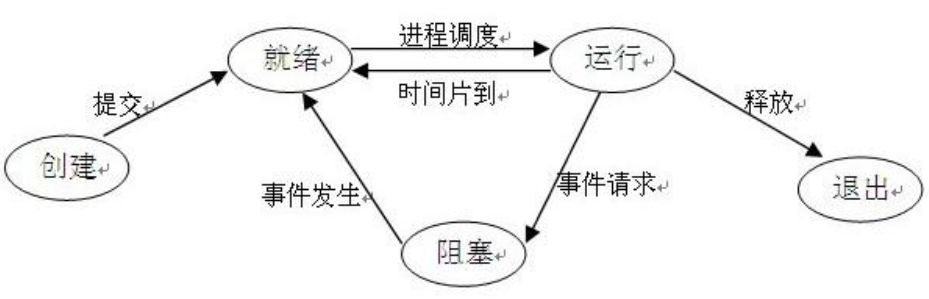
进程的三大基本状态:
就绪状态:已经获得运行需要的所有资源除了CPU
执行状态:已经获得所有资源包括CPU,处于正在运行
阻塞状态:因为各种原因进程放弃了cpu导致了进程无法继续执行此过程处于内存中,继续等待获得CPU
进程一个特殊状态(挂起状态):是指因为各种原因进程放弃了CPU导致进程无法继续执行,此时进程被踢出内存
multiprocessing模块:是python提供主要用于多进程编程
进程调度:先来先服务(FCFS),短作业优先调度算法(SJ/PF),时间片轮转法(Round Robin/RR),多级反馈队列
多进程语法:Process(target=函数名,args=(函数的参数,))
进程的并行和并发:
并行:是从微观上,也就是在一个精确的时间片刻有不同的程序在执行这就要求必须有多个处理器 一个时间点,多个程序在执行
并发:是从宏观上,在一个时间段上可以看出是同时执行,比如一个服务器同时处理多个session 一个时间段,只有一个程序在执行
注意:早期单核cpu的时候,对于进程也是 微观上,串行(站在cpu角度看);宏观上看,并行(站在人角度看)
进程的三大状态转换图:
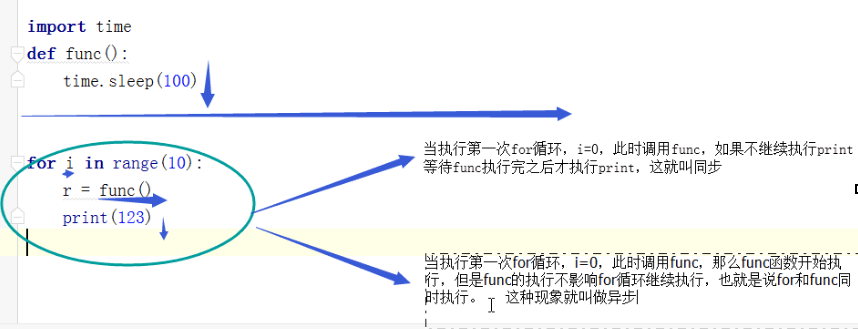
进程的同步和异步:
同步:就是一个任务需要依赖另一个任务时,只有等待被依赖的任务完成后,任务才算完成,这是一种可靠的任务序列。要么成功都成功,失败都失败,两个任务状态保持一致。
异步:不需要等待被依赖的任务完成,只是通知被依赖要完成的工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了,至于被依赖的任务最终是否真正完成,任务无法确定,所以它是不可靠的任务序列。
例:
多进程的开启:
1.直接开启进程
例:
from multiprocessing import Process
import time
import os
def func(n):
time.sleep(1)
print("进程的pid是%s,父进程的pid是%s" % (os.getpid(), os.getppid()))
if __name__ == "__main__":
for i in range(2):
p = Process(target = func,args = (i,))
p.start() #开启一个进程
print("进程的pid是%s,父进程的pid是%s" % (os.getpid(),os.getppid())) #os.getpid()获取进程的PID os.getppid()获取父进程的PID
结果:
进程的pid是9112,父进程的pid是11568
进程的pid是14924,父进程的pid是9112
进程的pid是16272,父进程的pid是9112
2.继承Process类开启进程
例:
from multiprocessing import Process
class Myprocess(Process):
def __init__(self):
super().__init__()
def run(self):
print("in son")
if __name__ == "__main__":
for i in range(3):
p = Myprocess()
p.start() #是指解释器告诉操作系统,开启一个进程 ,底层相当于调用run()方法 <==> p.run() #告诉操作系统马上执行这个程序
结果:
in son
in son
in son
Process的常用方法:
start:开启一个进程
join:让父进程等待子进程执行完,必须放在start下面
is_alive:判断一个进程是否还活着
terminate:杀死一个进程
例:
from multiprocessing import Process
import time
import os
def func(i):
print("in son%s" % i,os.getpid(),os.getppid())
if __name__ == "__main__":
for i in range(5):
p = Process(target=func,args=(i,))
p.start() #开启一个进程
print(p.is_alive()) #判断进程是否还活着
time.sleep(0.1)
p.terminate() #杀死进程 让解释器告诉操作系统,请求杀死进程,但不是马上执行
print(p.is_alive())
p.join() # 是让主进程等待子进程执行完 现象:主进程执行到这句话主进程阻塞住,等待子进程执行完
Process常用属性:
name:进程名字
daemon:设置守护进程(True为守护进程,False为普通进程),跟随着主进程执行结束而结束,必须要在start之前设置,守护进程不允许再开启进程.
例: name
from multiprocessing import Process
import os
import sys
class Myprocess(Process):
def __init__(self):
super().__init__(name = str(i))
def run(self):
print("in son",self.name,os.getpid())
if __name__ == "__main__":
for i in range(3):
p = Myprocess()
p.start()
结果:
in son 0 15992
in son 1 12460
in son 2 15072
例:daemon 守护进程
from multiprocessing import Process
import time
def fn():
print(123)
def func():
p1 = Process(target=(fn))
p1.start()
print("in son")
if __name__ == "__main__":
p = Process(target=func)
p.daemon = True
p.start()
time.sleep(0.01)
print("in Dad")
当time.sleep(0.01)时结果: in Dad
当time.sleep(0.1)时报错
多进程中进程之间的内存是不能共享的
在windows操作系统中,当开启多进程时,是把当前文件全部copy了一份给子进程,但是子进程中的__name__=="__mp_main__",所以在windows操作系统中子进程除了不再执行__name__=="__main__"以内的代码,其他全部执行
在linux操作系统中,当开启多个进程时,是把当前文件中子进程要执行的任务copy出去给子进程,所以在linux操作系统中,子进程只执行自己的任务函数,py文件中的其他代码子进程一概不管.
Lock 锁机制:
Lock()实例化对象
对象.acquire()锁门不允许其它进程进入
对象.release()开门允许其它进程进入
例:银行存钱取钱
from multiprocessing import Lock,Process,Value
import time
def put_money(num,l):
for i in range(100):
l.acquire() #锁门
num.value += 1
l.release() #开门
print(num.value)
time.sleep(0.1)
def get_money(num,l):
for i in range(100):
l.acquire() #锁门
num.value -= 1
l.release() #开门
print(num.value)
time.sleep(0.1)
if __name__ == "__main__":
num = Value("i",100) #Value将数据共享给所有进程,后面有两个参数第一个参数是第二参数的数据类型
l = Lock() #实例化一个锁对象
p = Process(target = put_money,args = (num,l)) #实例化一个存钱进程
p.start()
p1 = Process(target = get_money,args = (num , l)) #实例化一个取钱进程
p1.start()
p.join()
p1.join()
例:抢票
from multiprocessing import Process,Lock
import time
def chock(i):
with open("余票")as f:
print("第%s个查看还剩%s张票!" % (i,f.read()))
def buy_ticket(i,l):
l.acquire() #锁门
with open("余票")as f:
con = int(f.read())
time.sleep(0.1)
if con > 0:
print("�33[33m第%s个人抢到票!�33[0m" % i)
con -= 1
else:
print("�33[34m第%s个人没有抢到票!�33[0m" % i)
time.sleep(0.1)
with open("余票","w",encoding="utf-8")as f1:
f1.write(str(con)) #抢完车票后将剩余的车票数写入文件
l.release() #开门
if __name__ == "__main__":
l = Lock() #实例化一个锁对象
for i in range(10): #十个人去查看车票
p_ch = Process(target=chock,args=(i+1,))
p_ch.start()
for i in range(10): #十个人抢票
p_buy = Process(target=buy_ticket,args=(i+1,l,))
p_buy.start()
Semaphore 信号机制:
Semaphore(n)实例化n把锁
对象.acquire()锁门
对象.release()开门
信号机制比锁机制多了一个计数器,这个计数器是用来记录当前剩余的几把锁的,当计数器为0时,表示没有钥匙了,此时acquire()处于阻塞状态;对于计数器来说,每acquire()一次,计数器内部就减一,每次release()计数器内部就加一.
例:
from multiprocessing import Semaphore,Process
import time,random
def func(i,sem):
sem.acquire() #锁门
print("第%s个人进来了." % i)
time.sleep(random.randint(2,4))
print("第%s个人出去了." % i)
sem.release() #开门
if __name__ == "__main__":
sem = Semaphore(4) #实例化信号机制 Semaphore后面的参数就是有几把锁
for i in range(10):
p = Process(target = func,args = (i+1,sem))
p.start()
#最后结果第一次一定是4个人进去了等其中一个人出去了之后后面才会有人进去
Event事件机制:
事件机制是通过is_set()的bool值,去标识e.wait()的阻塞状态,
当is_set()的bool值是True时,e.wait()是非阻塞状态
当is_set()的bool值是False时,e.wait()是阻塞状态
当使用set()时,是把is_set()的bool值变为True
当使用clear()时,是把is_set()的bool值变为False
例:红绿灯
from multiprocessing import Process,Event
import time
def tra_light(e):
while 1:
if e.is_set(): #当e.is_set的结果是True,绿灯亮了
time.sleep(5) #绿灯亮了5秒,车走了
print("�33[36m 红灯亮了! �33[0m") #提示红灯亮了
e.clear() #e.is_set的结果变成False
else: #当e.is_set的结果是False时,红灯亮了
time.sleep(5) #红灯亮了5秒,车在等待
print("�33[33m 绿灯亮了! �33[0m") #提示绿灯亮了
e.set() #将e.is_set结果变成True
def car(i,e):
e.wait() #当e.is_set()的结果是True时向下运行;反之,阻塞.
print("第%s辆车过去了" % i)
if __name__ == "__main__":
e = Event() #实例化一个事件对象
t = Process(target=tra_light,args=(e,)) #实例化一个红绿灯的进程
t.start()
for i in range(50): #开启50个车的进程
c = Process(target=car,args=(i+1,e))
c.start()
c.join()
Queue 队列:
多进程之间通信,专门用于多进程之间的通信
队列:先进先出(First In First Out 简称:FIFO) 队列是安全的 底层实现有锁机制
栈:先进后出(First In Last Out 简称:FILO)
queue模块:不能进行多进程之前的数据传输
from multiprocessing import Queue
q = Queue(num) #num是队列的最大长度
multiprocessing模块中的Queue类中的方法:
q.get() #阻塞 等待获取数据:如果有数据直接获取;如果没有数据阻塞等待
q.put() #阻塞 如果可以继续往队列中放入数据,就直接放,不能放就阻塞等待
q.get_nowait() #不阻塞 等待获取数据:如果有数据直接获取;如果没有数据就报错
q.put_nowait() #不阻塞 如果可以继续往队列中放入数据,就直接放,不能放就报错
例:生产者消费者模型1
from multiprocessing import Process,Queue
def consumer(q):
while 1 :
info = q.get()
if info:
print(info)
else:
break
def producer(q):
for i in range(20):
info = str(i)
q.put(info)
q.put(None)
if __name__ == "__main__":
q = Queue()
p = Process(target = producer,args = (q,))
c = Process(target = consumer,args = (q,))
p.start()
c.start()
import os
print(os.cpu_count())
例:生产者消费者模型2
from multiprocessing import Queue,Process
def consumer(q,):
while 1 :
info = q.get()
if info:
print(info)
else:
break
def producer(q,):
for i in range(100):
info = str(i+1)
q.put(info)
# q.put(None)
if __name__ == '__main__':
q = Queue()
p = Process(target = producer , args = (q,))
c = Process(target = consumer , args = (q,))
p.start()
c.start()
p.join()
q.put(None)
JoinableQueue类继承了Queue类
JoinableQueue比Queue多了两个方法:
q.join()
q.task_done()
例:生产者消费者模型3
from multiprocessing import JoinableQueue,Process
def consumer(q,):
while 1:
info = q.get()
print(info)
q.task_done()
def producer(q,):
for i in range(100):
info = str(i+1)
q.put(info)
q.join() #生产者等待消费者消费完数据返回一个结果
if __name__ == '__main__':
q = JoinableQueue()
p = Process(target = producer , args = (q,))
c = Process(target = consumer , args = (q,))
c.daemon = True #设置守护进程随着主程序结束消费者程序也结束;否则消费者程序一直执行不会结束
c.start()
p.start()
p.join() #主程序等待生产者进程结束而结束
当程序执行到P.join()主程序会等待生产者进程结束而结束,而生产者进程执行到q.join()会等待消费者进程的q.task_done()返回一个标识,标识消费者消费完了所有数据,生产者进程才会结束.
把消费者进程设置为守护进程,当生产者进程结束,主进程结束,消费者也结束,
否则,消费者进程会在消费完所有数据后接着等待获取数据进程会阻塞在info = q.get()不会结束.
Pipe管道:
管道是不安全的,没有锁机制.队列 = 管道+锁 管道是全双工,tcp也是全双工,但udp不是
管道是用于多进程之间的一种通信方式.
如果在单进程中使用管道:那么就是con1接/收,con2收/接
如果在多线程中使用管道:主进程使用con1接/收,子进程就必须使用con2收/接
主进程使用con2接/收,子进程就必须使用con1收/接
在子进程中有一个著名的错误叫做EOFError,是指父进程中,如果关闭了发送端,子进程还继续接收数据,那么就会引发EOFError错误.
例:
from multiprocessing import Pipe,Process
def func(con):
con1,con2 = con
con1.close() #副进程使用管道con2接收数据就必须把管道con1关闭
while 1: #副进程要循环接收数据
try:
print(con2.recv()) #副进程使用管道con2接收数据
except EOFError: #如果主进程的con1发完数据并关闭管道con1,子进程的管道con2继续接收时就会报错,使用try方式获取错误
con2.close() #获取到错误,就是子进程已经把管道中所有数据都接收完了关闭管道
break
if __name__ == '__main__':
con1,con2 = Pipe()
p = Process(target = func , args = ((con1,con2),))
p.start()
con2.close() #主进程使用con1发送数据就必须把con2关闭
for i in range(10):
con1.send(i+1) #使用管道con1发送数据
con1.close() #发送数据后关闭管道
进程之间的内存共享(Manager,Value)
from multiprocessing import Manager
m = Manager()
num = m.dict({k:v})
num = m.list([1,2,3])
例:from multiprocessing import Manager,Process,Lock
def put_money(num,l):
l.acquire()
for i in range(100):
num[0] -= 1
print(num)
l.release()
def get_money(num,l):
l.acquire()
for i in range(100):
num[0] += 1
print(num)
l.release()
if __name__ == '__main__':
m = Manager()
num = m.list([100])
l = Lock()
p = Process(target = put_money, args = (num,l))
g = Process(target = get_money, args = (num,l))
p.start()
g.start()
p.join()
g.join()
print('主进程:',num)
进程池:
进程池的存在是因为在实际业务中任务量是有多有少,如果任务量特别多,不可能要开对应那么多的进程.开启那么多进程首先要消耗大量时间,让进程首先
先要消耗大量时间,让操作系统来为你管理它,其次它还需要消耗大量时间让CPU帮你调度它
开启的进程数最好比计算机的核数加1;线程就是核数乘于5
进程池还会帮程序员去管理池中的进程
进程池:一个池子里面有固定数量的进程,这些进程一直处于待命状态,一旦有任务就有进程去处理.
进程池中的方法:
map:
语法:map(函数名,iterable)
例:from multiprocessing import Pool
import os
def func(num):
print(num + 1)
if __name__ == '__main__':
p = Pool(os.cpu_count() + 1)
p.map(func,[i for i in range(100)])
p.close() #关闭数据池 不能再向数据池中添加任务
p.join() #等待所有进程执行完毕
apply同步处理:
语法:apply(函数名,args(参数) = (,))
同步处理任务时,不需要close和join
同步处理任务时,进程池中的所有进程是普通进程(主进程需要等待其执行结束)
例:
from multiprocessing import Pool
import time
def func(num):
print(num + 1)
if __name__ == '__main__':
p = Pool(5)
for i in range(100):
time.sleep(0.5)
p.apply(func , args = (i,))
apply_async异步处理:异步的效率,也就是说池中的进程一次性都去执行任务
异步处理任务时,进程池中的所有进程是守护进程(主进程代码执行完毕守护进程结束)
异步处理任务时,必须要加上close和join
例:
from multiprocessing import Pool
import time
def func(num):
num += 1
return num
if __name__ == '__main__':
p = Pool(5)
p_l = []
start = time.time()
for i in range(100):
a = p.apply_async(func,args = (i,))
p_l.append(a)
p.close()
p.join()
[print(i.get()) for i in p_l]
print(time.time() - start)
异步处理的回调函数:
回调函数就是说每当进程池中有进程处理完任务,返回的结果可以交给回调函数由回调函数进行进一步处理,回调函数只有异步才有,同步是没有的.
回调函数的使用:进程的任务函数的返回值,被当成回调函数的形参接收到,来进行进一步的操作
回调函数是由主进程调用的,而不是子进程,子进程只负责把结果传递给回调函数
例:
from multiprocessing import Pool
import requests
def func(url):
res = requests.get(url) #获取网站原码
if res.status_code == 200:
return url,res.text #返回网站地址和原码
def call_back(con): #回调函数 接收网站地址和原码
url,text = con
with open("a.text","w",encoding="utf-8")as f: #将网站的原码写入文件
f.write(text)
print(url) #打印写入网站原码的顺序
if __name__ == "__main__":
p = Pool(5)
l = ["https://www.baidu.com",
"http://www.mi.com",
"http://www.jd.com",
"http://www.taobao.com",
"http://www.cnblogs.com",
"https://www.bilibili.com"]
for i in l :
p.apply_async(func,args = (i,),callback = call_back) #
p.close()
p.join()
同步和异步的效率对比:
例:
from multiprocessing import Pool
import time
import requests
def func(url):
res = requests.get(url)
if res.status_code == 200:
return "OK"
if __name__ == "__main__":
p = Pool(5)
l = ["https://www.baidu.com",
"http://www.mi.com",
"http://www.jd.com",
"http://www.taobao.com",
"http://www.cnblogs.com",
"https://www.bilibili.com"]
start = time.time()
for i in l:
p.apply(func,args = (i,))
apply_time = time.time() - start
y_start = time.time()
for i in l :
p.apply_async(func, args = (i,))
p.close()
p.join()
print("同步时间:",apply_time,"异步时间:",time.time()-y_start)
结果:同步时间: 3.7369115352630615 异步时间: 0.7648911476135254