注:原文代码链接http://scikit-learn.org/stable/auto_examples/text/mlcomp_sparse_document_classification.html
运行结果为:
Loading 20 newsgroups training set...
20 newsgroups dataset for document classification (http://people.csail.mit.edu/jrennie/20Newsgroups)
13180 documents
20 categories
Extracting features from the dataset using a sparse vectorizer
done in 139.231000s
n_samples: 13180, n_features: 130274
Loading 20 newsgroups test set...
done in 0.000000s
Predicting the labels of the test set...
5648 documents
20 categories
Extracting features from the dataset using the same vectorizer
done in 7.082000s
n_samples: 5648, n_features: 130274
Testbenching a linear classifier...
parameters: {'penalty': 'l2', 'loss': 'hinge', 'alpha': 1e-05, 'fit_intercept': True, 'n_iter': 50}
done in 22.012000s
Percentage of non zeros coef: 30.074190
Predicting the outcomes of the testing set
done in 0.172000s
Classification report on test set for classifier:
SGDClassifier(alpha=1e-05, average=False, class_weight=None, epsilon=0.1,
eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate='optimal', loss='hinge', n_iter=50, n_jobs=1,
penalty='l2', power_t=0.5, random_state=None, shuffle=True,
verbose=0, warm_start=False)
precision recall f1-score support
alt.atheism 0.95 0.93 0.94 245
comp.graphics 0.85 0.91 0.88 298
comp.os.ms-windows.misc 0.88 0.88 0.88 292
comp.sys.ibm.pc.hardware 0.82 0.80 0.81 301
comp.sys.mac.hardware 0.90 0.92 0.91 256
comp.windows.x 0.92 0.88 0.90 297
misc.forsale 0.87 0.89 0.88 290
rec.autos 0.93 0.94 0.94 324
rec.motorcycles 0.97 0.97 0.97 294
rec.sport.baseball 0.97 0.97 0.97 315
rec.sport.hockey 0.98 0.99 0.99 302
sci.crypt 0.97 0.96 0.96 297
sci.electronics 0.87 0.89 0.88 313
sci.med 0.97 0.97 0.97 277
sci.space 0.97 0.97 0.97 305
soc.religion.christian 0.95 0.96 0.95 293
talk.politics.guns 0.94 0.94 0.94 246
talk.politics.mideast 0.97 0.99 0.98 296
talk.politics.misc 0.96 0.92 0.94 236
talk.religion.misc 0.89 0.84 0.86 171
avg / total 0.93 0.93 0.93 5648
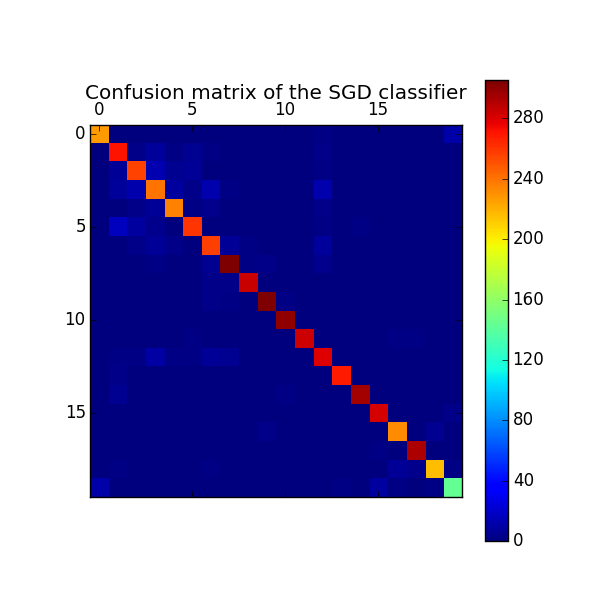
Confusion matrix:
[[227 0 0 0 0 0 0 0 0 0 0 1 2 1 1 1 0 1
0 11]
[ 0 271 3 8 2 5 2 0 0 1 0 0 3 1 1 0 0 1
0 0]
[ 0 7 256 14 5 6 1 0 0 0 0 0 2 0 1 0 0 0
0 0]
[ 1 8 12 240 9 3 12 2 0 0 0 1 12 0 0 1 0 0
0 0]
[ 0 1 3 6 235 2 4 0 0 0 0 1 3 0 1 0 0 0
0 0]
[ 0 17 9 4 0 260 0 0 1 1 0 0 2 0 2 0 1 0
0 0]
[ 0 1 3 7 3 0 257 7 2 0 0 1 8 0 1 0 0 0
0 0]
[ 0 0 0 2 1 0 5 305 2 3 0 0 4 1 0 0 1 0
0 0]
[ 0 0 0 0 1 0 3 3 285 0 0 0 1 0 0 1 0 0
0 0]
[ 0 0 0 0 0 0 3 2 0 305 2 1 1 0 0 0 0 0
1 0]
[ 0 0 0 0 0 0 1 0 1 0 300 0 0 0 0 0 0 0
0 0]
[ 0 0 1 1 0 2 0 1 0 0 0 284 0 1 1 0 2 2
1 1]
[ 0 2 2 10 2 2 6 5 1 0 1 1 279 1 1 0 0 0
0 0]
[ 0 3 0 0 1 1 1 0 0 0 0 0 0 269 0 1 1 0
0 0]
[ 0 5 0 0 1 0 0 0 0 0 2 0 1 0 295 0 0 0
1 0]
[ 1 1 1 0 0 1 0 1 0 0 0 0 0 1 1 282 1 0
0 3]
[ 0 0 1 0 0 0 0 0 1 3 0 0 1 0 0 1 232 1
5 1]
[ 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 2 0 293
0 0]
[ 0 2 0 0 0 0 2 0 0 1 0 1 0 1 0 0 7 4
216 2]
[ 11 0 0 0 0 0 0 0 0 0 0 1 0 2 0 9 2 1
2 143]]
Testbenching a MultinomialNB classifier...
parameters: {'alpha': 0.01}
done in 0.608000s
Percentage of non zeros coef: 100.000000
Predicting the outcomes of the testing set
done in 0.203000s
Classification report on test set for classifier:
MultinomialNB(alpha=0.01, class_prior=None, fit_prior=True)
precision recall f1-score support
alt.atheism 0.90 0.92 0.91 245
comp.graphics 0.81 0.89 0.85 298
comp.os.ms-windows.misc 0.87 0.83 0.85 292
comp.sys.ibm.pc.hardware 0.82 0.83 0.83 301
comp.sys.mac.hardware 0.90 0.92 0.91 256
comp.windows.x 0.90 0.89 0.89 297
misc.forsale 0.90 0.84 0.87 290
rec.autos 0.93 0.94 0.93 324
rec.motorcycles 0.98 0.97 0.97 294
rec.sport.baseball 0.97 0.97 0.97 315
rec.sport.hockey 0.97 0.99 0.98 302
sci.crypt 0.95 0.95 0.95 297
sci.electronics 0.90 0.86 0.88 313
sci.med 0.97 0.96 0.97 277
sci.space 0.95 0.97 0.96 305
soc.religion.christian 0.91 0.97 0.94 293
talk.politics.guns 0.89 0.96 0.93 246
talk.politics.mideast 0.95 0.98 0.97 296
talk.politics.misc 0.93 0.87 0.90 236
talk.religion.misc 0.92 0.74 0.82 171
avg / total 0.92 0.92 0.92 5648
Confusion matrix:
[[226 0 0 0 0 0 0 0 0 1 0 0 0 0 2 7 0 0
0 9]
[ 1 266 7 4 1 6 2 2 0 0 0 3 4 1 1 0 0 0
0 0]
[ 0 11 243 22 4 7 1 0 0 0 0 1 2 0 0 0 0 0
1 0]
[ 0 7 12 250 8 4 9 0 0 1 1 0 9 0 0 0 0 0
0 0]
[ 0 3 3 5 235 2 3 1 0 0 0 2 1 0 1 0 0 0
0 0]
[ 0 19 5 3 2 263 0 0 0 0 0 1 0 1 1 0 2 0
0 0]
[ 0 1 4 9 3 1 243 9 2 3 1 0 8 0 0 0 2 2
2 0]
[ 0 0 0 1 1 0 5 304 1 2 0 0 3 2 3 1 1 0
0 0]
[ 0 0 0 0 0 2 2 3 285 0 0 0 1 0 0 0 0 0
0 1]
[ 0 1 0 0 0 1 1 3 0 304 5 0 0 0 0 0 0 0
0 0]
[ 0 0 0 0 0 0 0 0 1 2 299 0 0 0 0 0 0 0
0 0]
[ 0 2 2 1 0 1 2 0 0 0 0 283 1 0 0 0 2 1
2 0]
[ 0 11 1 9 3 1 3 5 1 0 1 4 270 1 3 0 0 0
0 0]
[ 0 2 0 1 1 1 0 0 0 0 0 1 0 266 2 1 0 0
2 0]
[ 0 2 0 0 1 0 0 0 0 0 0 2 1 1 296 0 1 1
0 0]
[ 3 1 0 0 0 0 0 0 0 0 1 0 0 2 0 283 0 1
2 0]
[ 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 237 1
3 1]
[ 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 3 0 291
0 0]
[ 1 1 0 0 1 1 0 1 0 0 0 0 0 0 1 1 17 6
206 0]
[ 18 1 0 0 0 0 0 0 0 1 0 0 0 0 0 14 4 2
4 127]]
步骤为:
一、preprocessing
1.加载训练集(training set)
2.训练集特征提取,用TfidfVectorizer,得到训练集上的x_train和y_train
3.加载测试集(test set)
4.测试集特征提取,用TfidfVectorizer,得到测试集上的x_train和y_train
二、定义Benchmark classifiers
5.训练,clf = clf_class(**params).fit(X_train, y_train)
6.测试,pred = clf.predict(X_test)
7.测试集上分类报告,print(classification_report(y_test, pred,target_names=news_test.target_names))
8.confusion matrix,cm = confusion_matrix(y_test, pred)
三、训练
9.调用两个分类器,SGDClassifier和MultinomialNB