电商的定向广告和搜索广告的不同在于俩点:
1.用户没有明显的意图(主动Query查询)
2.用户来到淘宝之前,自己也没有特别明确的目标 (此时利用以往的历史行为进行item推荐)
因此定向广告需要考虑的样本特征更多的和历史有关。
如何划分样本:
一个正样本如下所示:
p(y=1|ad,context,user)
其中,ad代表广告候选集,user代表用户特征,年龄,性别,context表示上下文场景,设备,时间。
淘宝定向广告的演化:
第一阶段:
LR(线性模型)-》 MLR(非线性模型) -》DNN模型(深度学习)
LR时代,由于LR的局限性,不能处理非线性特征(如时间),所以需要特征工程加入非线性特征,因此有了MKR(Mixed Logistic Regression),采用分而治之的策略,利用分段线性+级联,拟合高维空间的非线性分类面,相比于人工来说提升了效率和精度。
在DNN阶段,可以处理复杂模型和大数据量,但是使用定长的embedding并不能表达用户多种多样的兴趣。
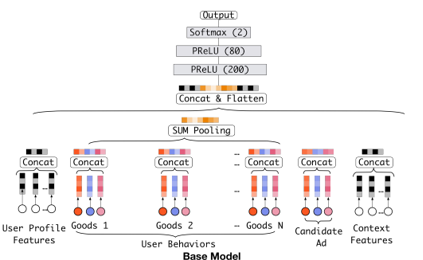
传统的DNN模型的 Base Model流程如下:
embedding+MLP
特征表示:user profile、user behavior、ad 以及 context
- Step1,将不同的特征转换为对应的embedding表示
- Step2,将所有特征的embedding做拼接
- Step3,输入到多层感知机MLP(DNN),计算结果
- 每个特征类别包括多个feature field
- feature field是单值特征 => one-hot编码
- feature field是多值特征 => multi-hot编码

- Embedding Layer,将高维稀疏向量转换为低维稠密向量
- Pooling Layer + Concat Layer,使用Pooling解决每个用户行为 的维度不同的问题,并与其他三个类别中的embedding结果进行拼接,作为MLP Layer的输入
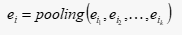
- MLP Layer,学习给到的拼接embedding,自动学习高阶特征之间的组合
- Loss,损失函数采用negative log-likelihood loss
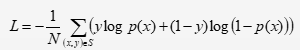
- S代表训练样本的个数,x是网络的输入,y是{0, 1}样本标签,
- p(x)代表输入x的预估点击概率
要使用用户历史的行为,需要考虑多个个因素:
1.多样性,一个用户在一段时间可以对多种类别的东西感兴趣,比如衣服类,食品类,家具类等。这意味着我的推荐不能把所有东西一起embeding。
2.局部激活,如果用户此时点击的是衣服,那么我的食品类和家具类的embeding对本次预测并没有帮助。
3.从时间顺序来看,商品感兴趣序列并没有规律,有可能这一段时间用户关注衣服多一些,接下来一段时间用户想买食品,搜食品又可能多一些,如果综合考虑,那么存在巨大噪音,但是具体到某一个兴趣,比如衣服,却可以看出随时间演化的趋势,比如衣服购买风格的变换。
4.但是这些感兴趣的类之间并非完全没有联系,比如我这段时间挑了衣服,可能还需要穿搭,还会挑选戒指,配饰等,如果将用户行为看成多个对话,会话之间也存在一定的联系。
DNN存在1,2问题,为了解决这些问题,阿里使用了深度兴趣网络DIN:
Deep Interest Network for Click-Through Rate Prediction,2018
https://arxiv.org/abs/1706.06978
- DIN是在DNN的基础上添加了Attention机制:
- 在对用户行为的embedding计算上引入了attention network (也称为Activation Unit)
- 把用户历史行为特征进行embedding操作,视为对用户兴趣的表示,之后通过Attention Unit,对每个兴趣表示赋予不同的权值
- Attention Weight是由用户历史行为和候选广告进行匹配计算得到的,对应着洞察(用户兴趣的Diversity,以及Local Activation)