直接起飞
1.什么是索引?
索引是帮助mysql高效获取数据的排好序的数据结构。
2.索引的数据结构?为什么选这种结构?
假设我们现在这里有一张表(以下情况都是innodb存储引擎):
| id | number |
| 1 | 33 |
| 2 | 18 |
| 3 | 14 |
| 4 | 22 |
| 5 | 57 |
| 6 | 8 |
| 7 | 20 |
| 8 | 72 |
| 9 | 51 |
如果mysql没有索引这种结构,那么我们如果查找number为51的这行记录,那么mysql就要从上往下扫描全表,找到number为51的这行记录需要9次;
二叉树?
如果mysql索引结构为二叉树呢?
我们要去查找51这个元素:
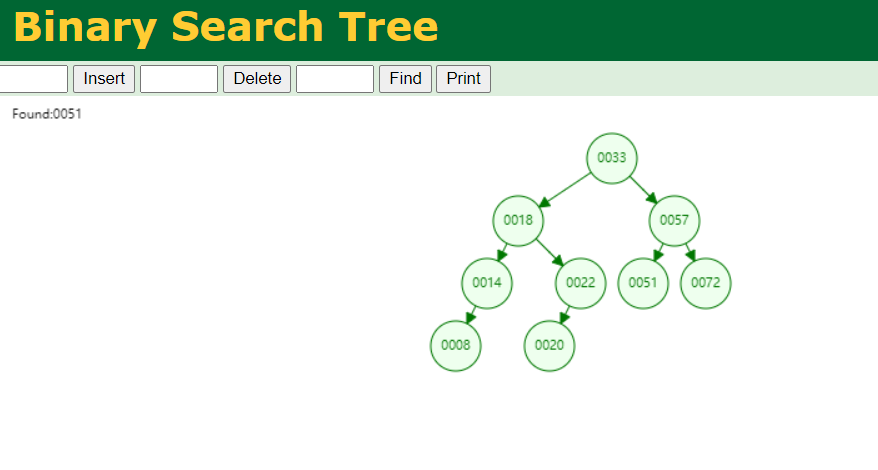
我们只需要查找3次就能找到51这个元素,时间复杂度为O(3);
那么我们mysql索引用的就是二叉树结构吗?
肯定不是的,如果是二叉树,那么我把id这一列作为索引会是怎么样的情况:
假设我们现在要查找id为7的这一列:

这个时候二叉树已经是链表化了,我们查找7这个元素就需要找7次,时间复杂度为O(7);
二叉树对于连续自增的数据会转为链表化,不适合做这种数据的查找。我们排除这种数据结构。
红黑树?
假设mysql索引为红黑树,这个时候我们还是先去查找number为51的这一行:
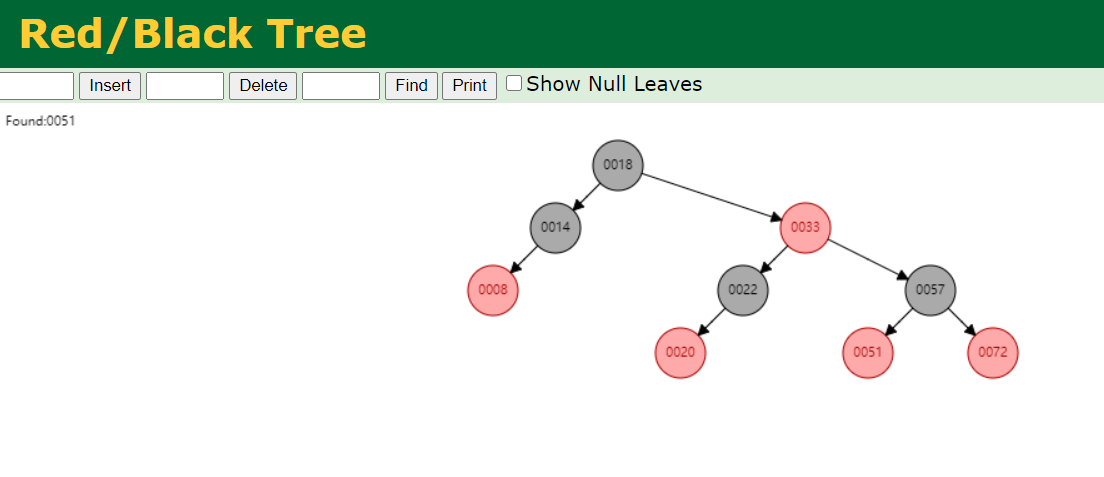
我们需要查找4次就能找到51这个元素,时间复杂度为O(4);
再看如果查找id为7的元素呢?
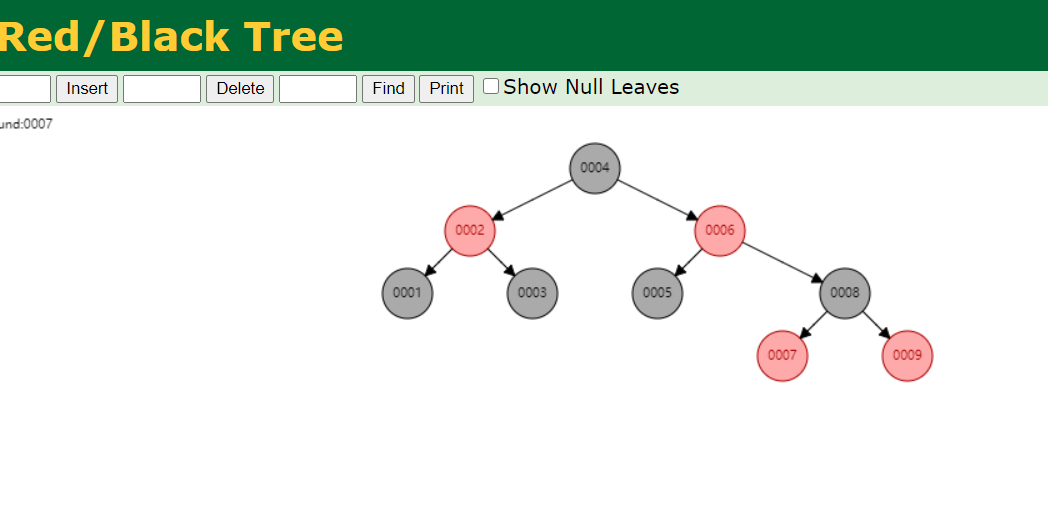
这次找id为7的元素,只找了4次,比二叉树次数少多了;
那么mysql用的是红黑树吗?我们来思考一个问题:
如果我数据库里面有几千万条数据,也就是说,id是自增的几千万个,那么这个红黑树高度是不是很高,查询元素时间复杂度为O(n);这显然是不符合我们mysql高数据量的时候查找;
hash表?
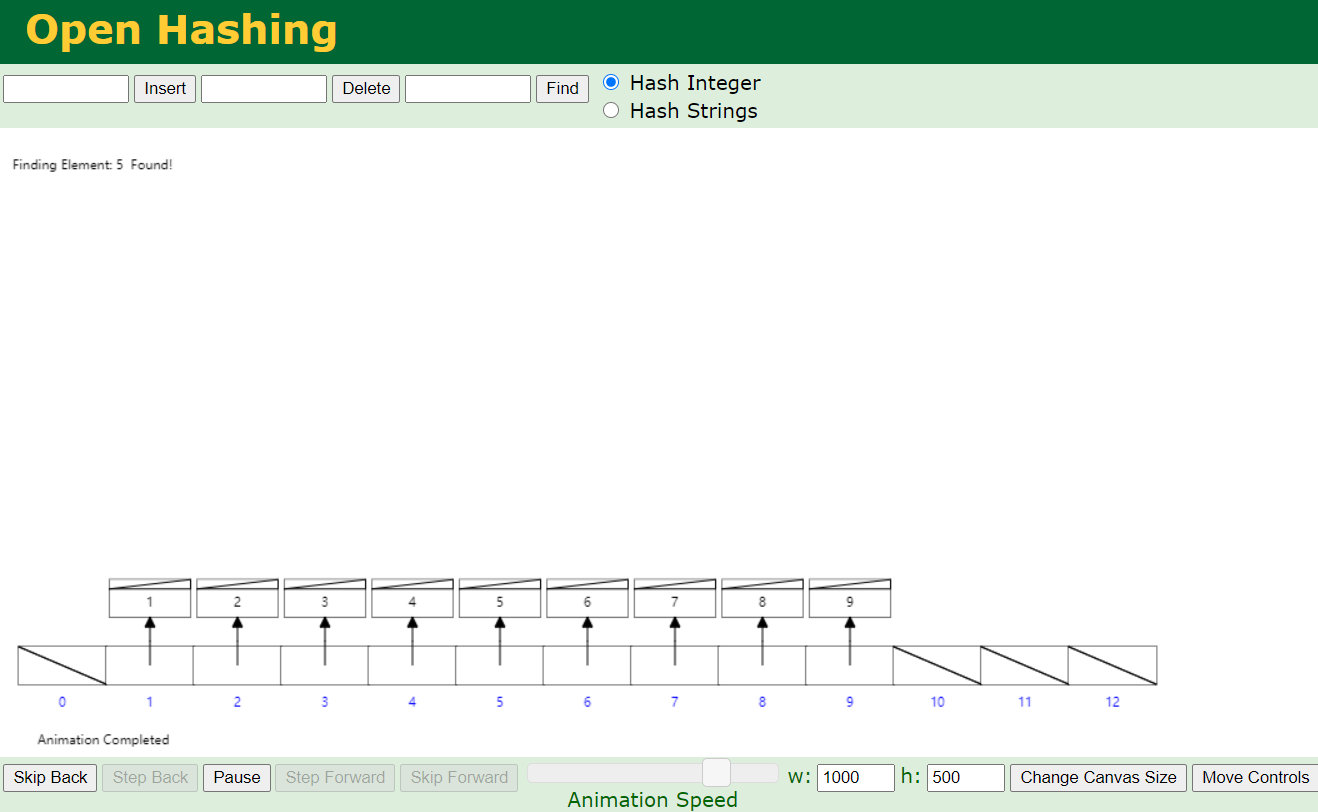
查找id为7,只需要一次,很快,很棒,这也是mysql索引的一种;
但是,我们来想想这有什么缺陷:
1.hash冲突问题;
2.如果我想查找2<id<6的这些元素呢?hash还能找的到吗?
答案肯定是不行的,hash只适合做简单查询,但是它效率非常高,只需要去hash表中查找一次就能精确定位到数据,但是hash表只能做一次hash运算去查找元素,像前面的情况,就无法使用索引去查找元素了。
来验证一下,我们给test表加上hash索引:

查询一个money的区间:
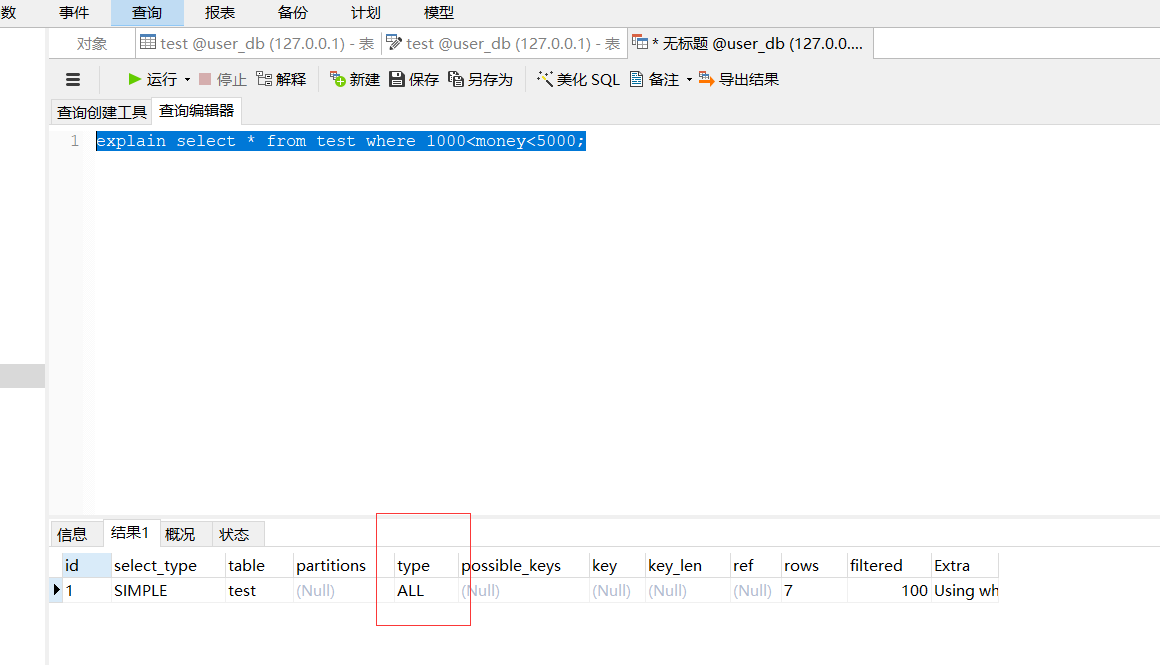
直接走的全表扫描,并没有走索引;
B-Tree?
我们还是来查找money为51的这行数据:
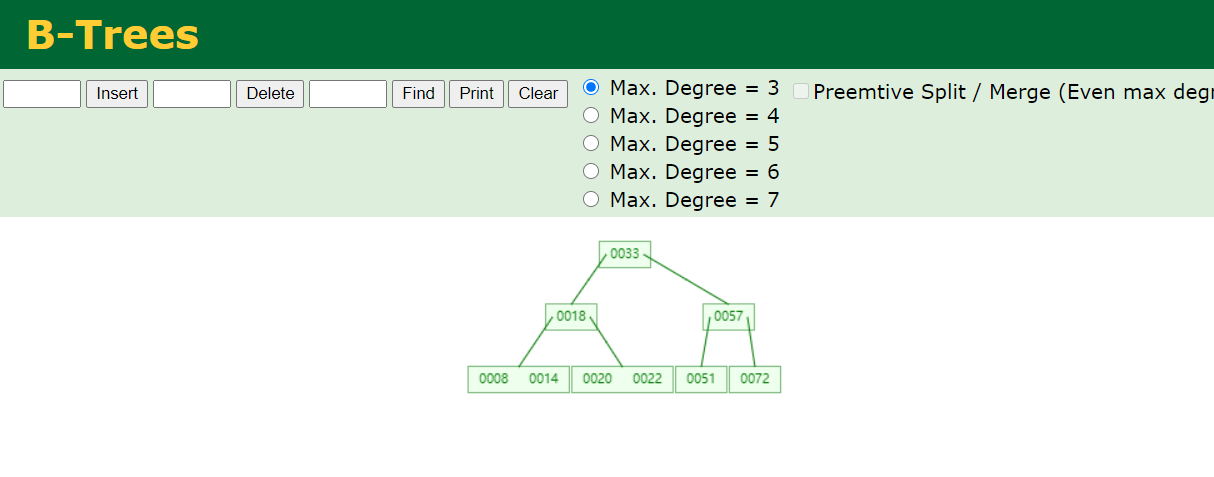
我们可以看到,一颗高度为3的b tree上,我们去查找元素时间复杂度最多为O(3);我们去查找51也是查找3次,很好的解决了元素查找问题;
再看这棵树上面,叶子节点都是排好序的,但是需要去查找的话,还是需要从根节点开始查找,并没有完美解决hash表不能做的范围查找;(范围查找时间复杂度高)
那么mysql用的是b tree吗?mysql用的不是b tree,我们下面来看b+tree;
B+Tree
mysql索引使用的就是b+tree;为什么mysql会选用b+tree呢?我们来看b+tree的结构:
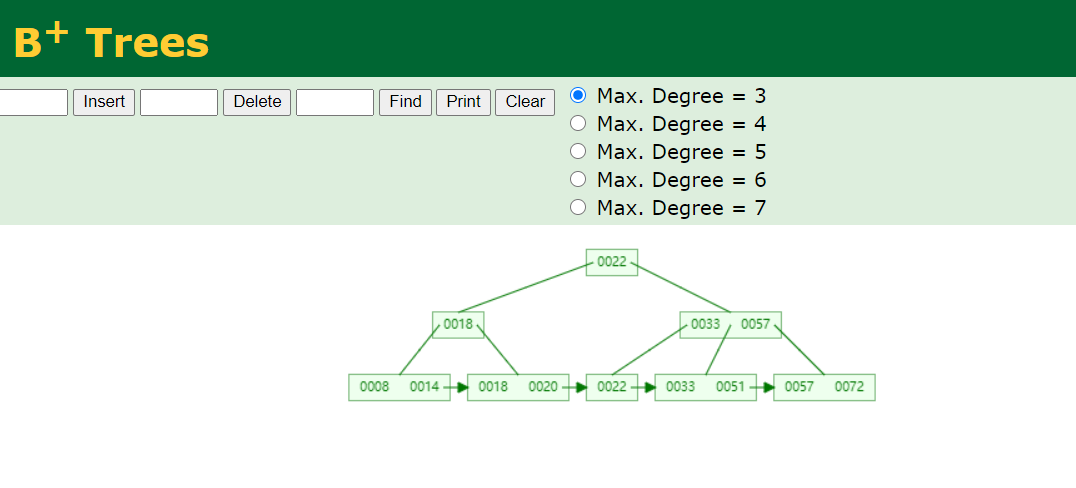
从结构上来看,b+tree多了冗余数据,叶子节点上面有指向下一个叶子节点的指针;
如果是范围查找,我查找到一个数据,那么根据叶子节点指针就能顺藤摸瓜找到这个范围能的数据,完美解决了hash表的范围查找;
b+tree跟b tree还有一个区别点是b+tree(数据库这行data)只放在了叶子节点;而b tree在第二行数据块上面也存有着 (数据库这行data),一个数据库只有16kb大小,容量有限,在有限容量下,b+tree的冗余设计要比b tree能存放更多的数据;
3.为什么选用InnoDb存储引擎
1.表数据文件本身就是按照b+tree组织的文件存储,主键索引上面包含了整行的全部数据,节省了磁盘空间;
2.聚集索引(主键索引)的叶子节点包含了整行数据;MyISam引擎文件和数据是非聚集的(索引文件myi和数据文件myd并不是在一个文件,这一点innodb都是存放在ibd文件);
3.innodb支持事务;
4.各种索引
4.1主键索引(聚集索引)
以主键数据作为索引列,叶子节点上包含了行所有的数据:

4.2稀疏索引(辅助索引,非聚集索引)
以非主键列作为索引,叶子节点上面只有id,如果需要查询这行全部数据,需要去主键索引上面回表:

4.3覆盖索引
所谓覆盖索引,其实上就是非主键索引,但是被称做覆盖索引是因为sql的查询项中只包含了索引列和id,不需要去主键索引回表,这样的操作就称为覆盖索引查询。
4.4联合索引
所谓的联合索引,其实就是由多个字段组成的辅助索引;符合最左前缀匹配规则(结合索引的有序性,就能明白为什么是最左前缀匹配原则;后面sql优化中会讲到这些):
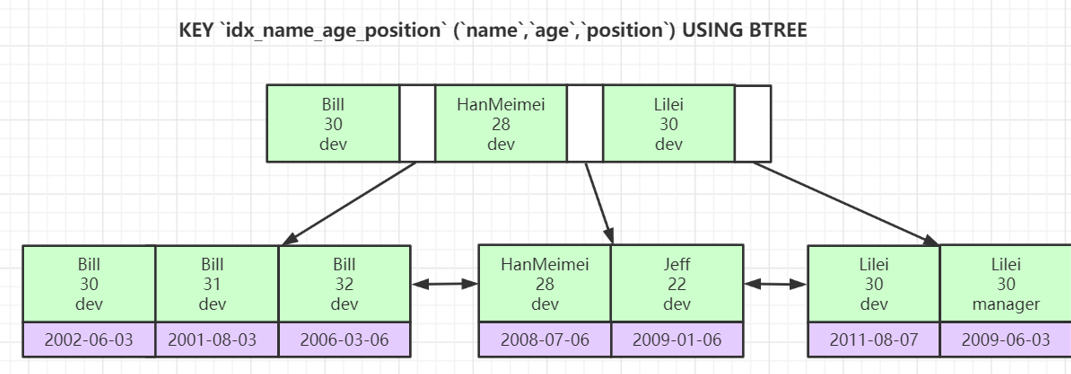
问题1:为什么非主键索引叶子节点存储的是主键?
可以节省磁盘存储空间,ibd文件会相对较小;
行数据做更改的时候并不影响辅助索引,只存储id的奥妙所在(更改不需要去维护索引);
问题2:为什么innodb存储引擎的表必须要建主键?并且推荐使用自增主键?
如果没有主键就无法维护ibd文件,innodb必须要有索引;如果建表的时候没有设置主键,innodb会维护一个隐藏列去作为主键索引;
自增索引插入的时候效率要比其他要高出很多;而且作为int或者long,比起uuid所占用字节是要少的多的,也就是说,上层荣誉节点可以放更多,下层叶子节点也可以放更多的数据。