cinder和ceph层面对clone、flatten的实现
现在市面上很多讲ceph的书(大多数翻译自ceph中国社区之手),在RBD块存储章节都会对快照、克隆等操作花很多篇幅去描述,基本都是在rbd层通过命令一步步分解rbd clone过程来讲原理。
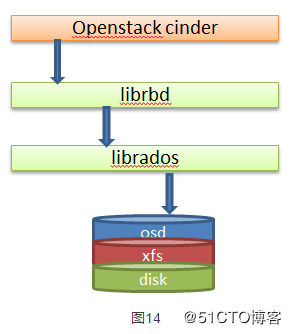
只是想大概的了解下对云硬盘执行操作在底层是如何实现的,还是由上文中提到的小处(bug)来入手,自顶向下先设计一个思考流程,带着目标按照这个从上到下的顺序去理解,如下图所示:
注:以下涉及的代码均来自GitHub开源,如有雷同,纯属巧合!
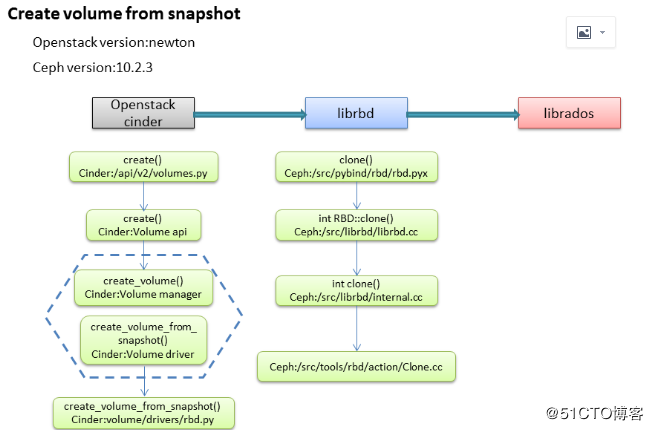
1、从快照克隆卷的流程
(1)openstack cinder
自顶向下,先从cinder层入手,通过代码可以看到从快照克隆出volume的思路,从本质上讲,快照克隆出新的卷,也是volume create的性质,所以先来了解下volume create过程
cinder:/cinder/volumes.py

volumes.py中def create方法我省略了很多,主要就是通过req、body的参数来获取创建volume所需要的参数,根据不同参数来发送具体的创建volume请求,因为我是从快照来创建,snapshot id自然必不可少,在 volumes.py最后实际调用new_volume = self.volume_api.create()去实现。
cinder:/cinder/volume/api.py
经过volume_api.create(),在/cinder/volume/api.py来处理前端发来的卷相关的所有请求,通过create_what{}表示volume的实现参数,然后分别就调用cinder.scheduler的scheduler_rpcapi,cinder.volume的volume_rpcapi建立创建volume的工作流:create_volume.get_flow

注:关于create volume flow的流程及具体实现,见/cinder/volume/rpcapi.py:def create_volume(),/cinder/volume/flows/api/create_volume.py,本篇省略过程
cinder:/cinder/volume/manager.py
对于api来讲,只是做到处理前端发来的卷相关的所有请求,具体实现交由manager下的去完成,rpcapi调用inder/volume/manager.py:def create_volume()去操作
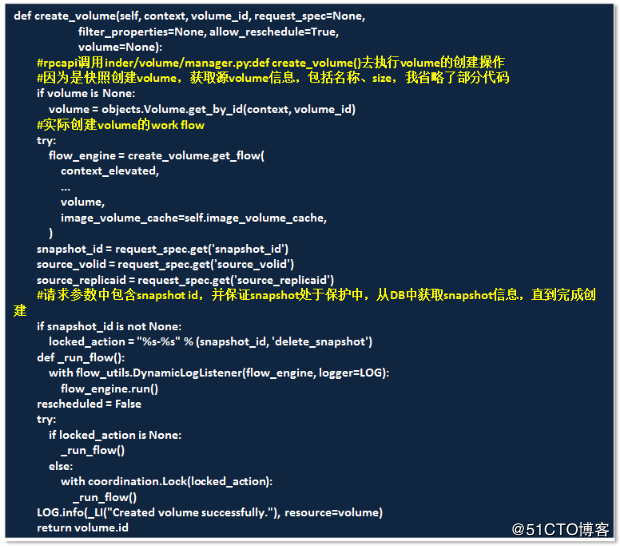
执行中发现crate voluem 有snapshot id,然后调用/cinder/volume/flows/manager/create_volume.py下的私有方法_create_volume_from_snapshot()

最后根据配置文件指定的RBD后端请求/cinder/volume/drivers/rbd.py的create_volume_from_snapshot()
cinder:/cinder/volume/drivers/rbd.py
众所周知,一般cinder使用RBD驱动来对接底层的后端存储(比如ceph、xsky),在openstack cinder层面最终交由create_volume_from_snapshot()实现,因为是通过快照来创建volume,还需要调用私有方法_clone(),满足条件的话,还要调用_flatten()和_resize()。

(2)librbd
经历多方接力才结束在cinder层面的流程,这还不算完,真正要实现create volume from snapshot的创建,核心在调用ceph执行。
ceph:/src/pybind/rbd/rbd.pyx
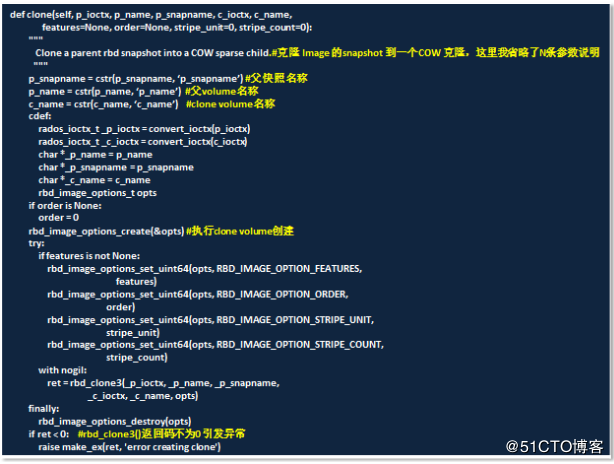
/ceph/blob/v10.2.3/src/librbd/http://librbd.cc

在librbd中对外提供api在class RBD中,从http://librbd.cc函数中看到有多个clone()、clone2()、clone3()函数,区别在于根据传入的不同参数来调用对应的函数,但这些函数都不像是具体的功能实现,只是一些相关参数传值。
再看看/ceph/blob/v10.2.3/src/librbd/http://internal.cc函数,同http://librbd.cc一样,对应的clone()也是3种,因为篇幅如下展示的是clone3()函数(实际命名并不如此,通过参数来区分得知是clone2):
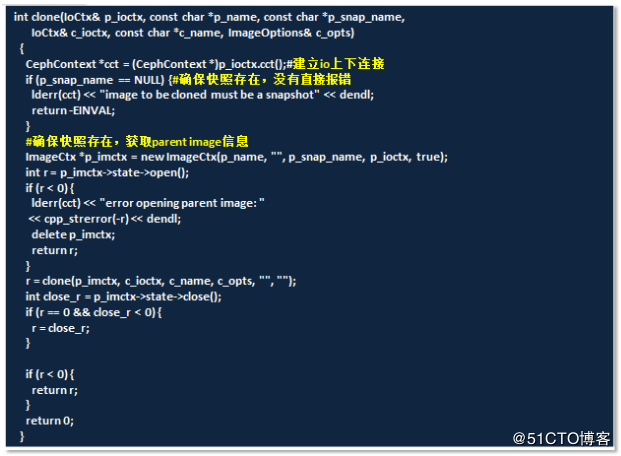
将http://librbd.cc、http://internal.cc两个函数联系起来看,http://librbd.cc只是定义了对外的各种函数接口,接口的具体实现,调用的还是http://internal.cc中定义的函数内容。
总结一下,根据自己的理解将整个流程绘成图,如下图所示中,需要一提的是,我没有涉及到librados的实现过程,因为clone等volume的操作,librbd可以说就是rbd的完整实现,rados只是作为后端的存储
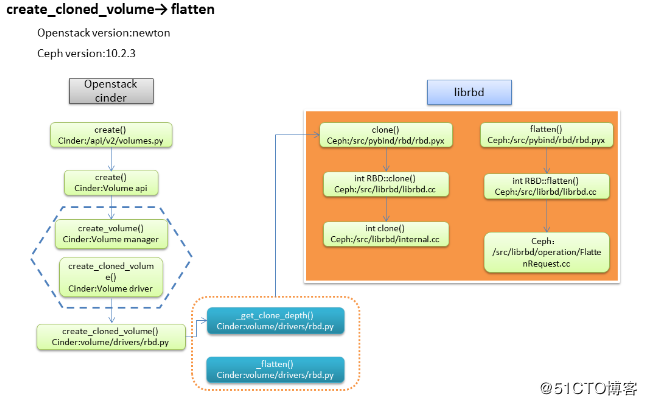
2、flatten的流程
在前文“ 利用rbd_max_clone_depth触发flatten”小节中,我们描述了一个volume clone的过程,通过cinder.conf的一个参数,当满足rbd_max_clone_depth最大层数后,触发flatten操作,下面我们通过代码去看一看具体实现的流程。
(1)openstack cinder
对于上层云平台而言,从云硬盘1克隆出云硬盘2,或者从快照创建云硬盘,一般是能够触发flatten操作的主要场景,其实两者实现原理基本一致。
因此,和之前的由snapshot来实现创建新的云硬盘一样,首要都是从create()开始,只是参数不同,克隆盘在create过程先要获取parent volume id

之后也是一样经历api→manager→driver的过程,这里省掉重复的过程,直接看cinder调用rbd驱动对克隆云硬盘的实现代码,如下图中/cinder/volume/drivers/rbd.py:
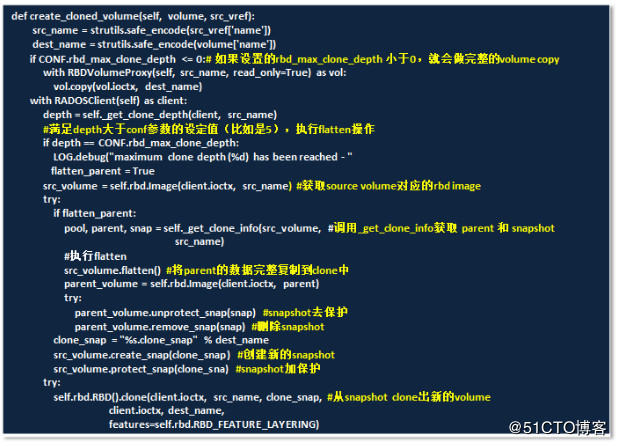
调用了私有方法_get_clone_depth()来判断depth,调用_flatten()来实现flatten操作,当然flatten过程经历一系列过程,在parent volume上创建snapshot,对snapshot加保护、再执行clone,然后flatten,这个过程一样可以通过rbd 命令来完成。
(2)librbd
创建RADOSClient,连接到ceph rados,这里也是先调用clone()去执行,再触发flatten()操作,和我预期不同,flatten的过程比想象中还要复杂,才疏学浅,对整个过程的了解还需要更多的时间,只能先用根据自己的理解画出一张流程图表示一下:
来源:51CTO 作者欧德孙