本节内容一览图

一、函数介绍
1、什么是函数

2、定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
3、函数语法:


二、函数参数与局部变量
一览表:

形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
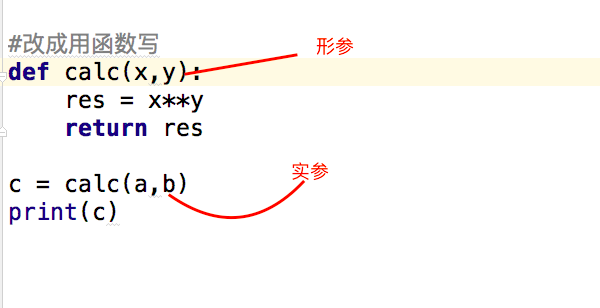
1、默认参数
函数的默认参数的作用是简化调用
由于函数的参数按从左到右的顺序匹配,所以默认参数只能定义在必需参数的后面:

默认参数,传入是就修改默认值,未传入时,就使用原来的值
看下面代码
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,country,course): print("----注册学生信息------") print("姓名:",name) print("age:",age) print("国籍:",country) print("课程:",course)stu_register("王山炮",22,"CN","python_devops")stu_register("张叫春",21,"CN","linux")stu_register("刘老根",25,"CN","linux") |
发现 country 这个参数 基本都 是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是 中国, 这就是通过默认参数实现的,把country变成默认参数非常简单
|
1
|
def stu_register(name,age,course,country="CN"): |
这样,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。
另外,你可能注意到了,在把country变成默认参数后,我同时把它的位置移到了最后面,为什么呢?
2、关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
|
1
|
stu_register(age=22,name='alex',course="python",) |
3、非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式 print(name,age,args)stu_register("Alex",22)#输出#Alex 22 () #后面这个()就是args,只是因为没传值,所以为空stu_register("Jack",32,"CN","Python")#输出# Jack 32 ('CN', 'Python') |
还可以有一个**kwargs
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs)stu_register("Alex",22)#输出#Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong")#输出# Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'} |
4、局部变量
|
1
2
3
4
5
6
7
8
9
10
11
|
name = "Alex Li"def change_name(name): print("before change:",name) name = "金角大王,一个有Tesla的男人" print("after change", name)change_name(name)print("在外面看看name改了么?",name) |
输出
|
1
2
3
|
before change: Alex Liafter change 金角大王,一个有Tesla的男人在外面看看name改了么? Alex Li |
5、全局与局部变量
三、函数基础类型
1、匿名函数
lambda表达式


# ###################### 普通函数 ###################### # 定义函数(普通方式) def func(arg): return arg + 1 # 执行函数 result = func(123) # ###################### lambda ###################### # 定义函数(lambda表达式) my_lambda = lambda arg : arg + 1 # 执行函数 result = my_lambda(123)
匿名函数就是不需要显式的指定函数
#这段代码 def calc(n): return n**n print(calc(10)) #换成匿名函数 calc = lambda n:n**n print(calc(10))
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果
#!/usr/bin/python3 # 可写函数说明 sum = lambda arg1, arg2: arg1 + arg2; # 调用sum函数 print ("相加后的值为 : ", sum( 10, 20 )) print ("相加后的值为 : ", sum( 20, 20 ))
小结
Python对匿名函数的支持有限,只有一些简单的情况下可以使用匿名函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
2、递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数
尾递归调用时,如果做了优化,栈不会增长,因此,无论多少次调用也不会导致栈溢出。
遗憾的是,大多数编程语言没有针对尾递归做优化,Python解释器也没有做优化,所以,即使把上面的fact(n)函数改成尾递归方式,也会导致栈溢出。
小结
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。
Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题。
趣解递归
http://codingpy.com/article/10-gifs-to-understand-some-programming-concepts/
3、装饰器
小结
在面向对象(OOP)的设计模式中,decorator被称为装饰模式。OOP的装饰模式需要通过继承和组合来实现,而Python除了能支持OOP的decorator外,直接从语法层次支持decorator。Python的decorator可以用函数实现,也可以用类实现。
decorator可以增强函数的功能,定义起来虽然有点复杂,但使用起来非常灵活和方便
Python自动化面试必备 之 你真明白装饰器么:http://blog.51cto.com/3060674/1736659
4、内置函数

注:查看详细猛击这里
四、高级特性:
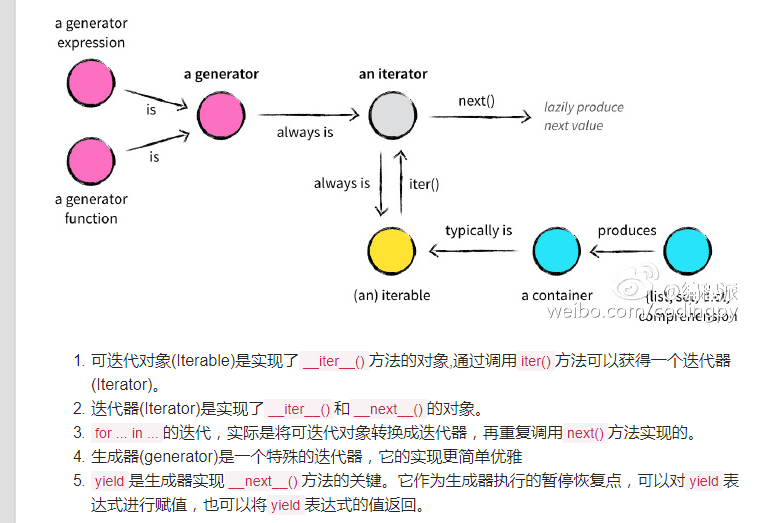
1、生成器generator
Python中,这种一边循环一边计算的机制,称为生成器:generator
定义:一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator),如果函数中包含yield语法,那这个函数就会变成生成器
第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
通过next()函数获得generator的下一个返回值
使用for循环,因为generator也是可迭代对象
第二种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
2、迭代
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)
在Python中,迭代是通过for ... in来完成的,而很多语言比如C或者Java,迭代list是通过下标完成的
任何可迭代对象都可以作用于for循环,包括我们自定义的数据类型,只要符合迭代条件,就可以使用for循环
3、迭代器Iterator

迭代器是访问集合元素的一种方式。
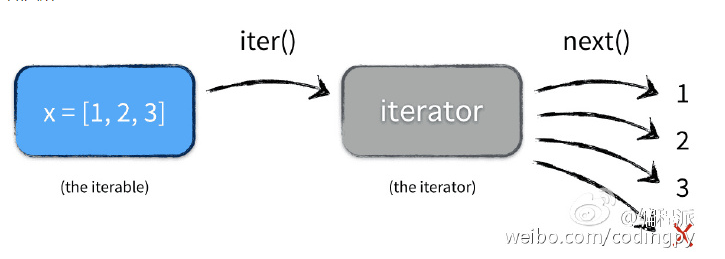
其实说白了,generator就是iterator的一种,以更优雅的方式实现的iterator
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的
切片:
L = range(1, 101)
print L[0:10]#从第1个数元素开始取,到第11元素结束
print L[2::3]#从第三元素开始取,每隔2个取一个元素
print L[4:50:5]#从第五个取,每隔4个取一个,‘开始元素’:‘最后元素’:‘取元素间隔’
l[x:y:z]函数指的是‘开始元素’:‘最后元素’:‘取元素间隔;
倒序切片:
print L[4::5][-10:] 先获得5的倍数,再取后10个 ###最后10个5的倍数。
声明:
本人在学习老男孩python自动化网络课程后,结合所学整理做次笔记,本文内容多出
Alex老师博客:http://www.cnblogs.com/alex3714/articles/5740985.html
武沛齐老师博客:http://www.cnblogs.com/wupeiqi/articles/5453708.html
感谢老男孩教育老师Alex,武沛齐老师,本文多从二位老师文章中结合整理
感谢麻瓜编程侯爵
http://www.runoob.com/python3/python3-basic-syntax.html
https://python.xiaoleilu.com/100/101.html
http://www.ituring.com.cn/book/1863
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014318435599930270c0381a3b44db991cd6d858064ac0000
生成器迭代器
http://codingpy.com/article/python-generator-notes-by-kissg/