网上有很多网站会通过.md文档来做页面内容(比如,阮一峰老师的es6入门blog: http://es6.ruanyifeng.com/),很好奇,这是怎么做的?(至于.md是什么,或许(https://www.runoob.com/markdown/md-tutorial.html)这里会有答案)
出于好奇,建了一个test.md文件:
# Hello World! asdfa asd *斜体文本* **粗体文本** ***斜粗体文本*** 分隔线(如下) *** * * * **** - - - ----------- GOOGLE.COM ~~删除线~~ <u>下划线</u>
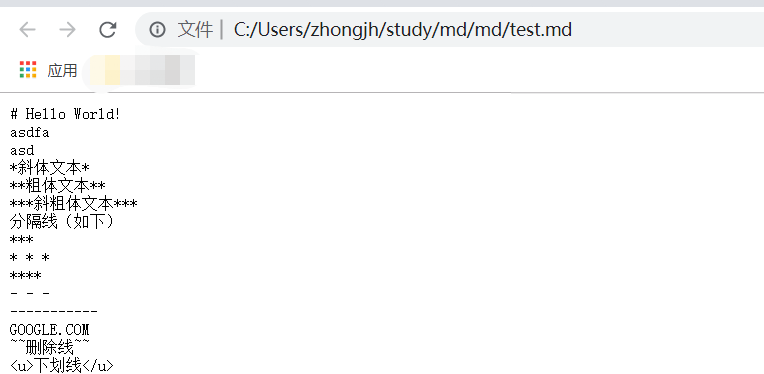
用浏览器打开之后,结果就被原封不动的输出来了,浏览器根本不会解析这玩意... 跟阮老师的blog相差好大啊~ 呵呵~ 还是太天真了!
然后,发现:
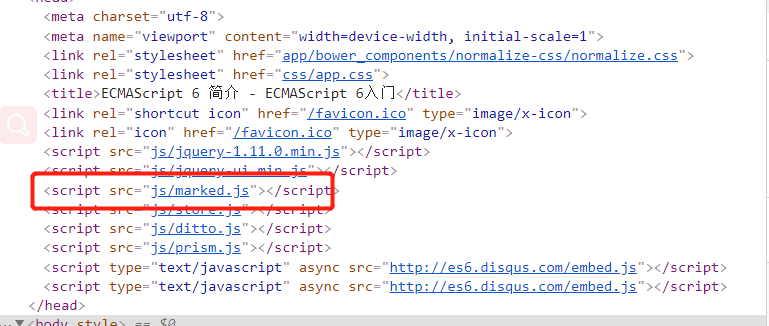
原来markdown文本还是需要用marked.js这么一个库来解析的!于是乎,依葫芦画个瓢
<!doctype html>
<html>
<head>
<meta charset="utf-8"/>
<title>md文档内容转成html显示</title>
</head>
<body>
<div id="content" style=" 500px;height: 500px;overflow: auto"></div>
<div style="margin-top: 30px">
<form name="form" action="" method="post">
<select name="q">
<option value="md/gs.md">公式</option>
<option value="md/test.md">第一个Markdown文档</option>
</select>
<input type="button" value="显示" onclick="showMarkdown()">
</form>
</div>
<script type="text/javascript" src='https://cdn.jsdelivr.net/npm/marked/marked.min.js'></script>
<script type="text/javascript">
function showMarkdown() {
var f = form;
var xmlhttp;
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject('Microsoft.XMLHttp');
}
xmlhttp.onreadystatechange = function() {
if(xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById('content').innerHTML = marked(xmlhttp.responseText);
}
}
// 向服务器发送请求
xmlhttp.open('GET', f.q.value, true);
xmlhttp.send();
}
</script>
</body>
</html>
于是就有了下面的样子:
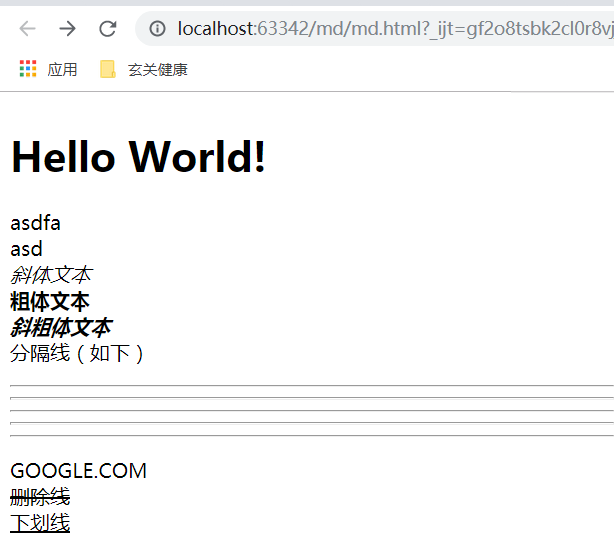
原理就是用ajax请求,取到 .md文件里的内容,再通过marked.js提供的marked()方法将markdown语法的文本转成html文档。