1、Scrapy_redis的基础概念
2、Scrapy_redis的流程
3、复习redis的使用
4、Scrapy_redis的使用
1、 Scrapy_redis的基础概念
scrapy_redis:基于redis的组件的爬虫
github地址:https://github.com/rmax/scrapy-redis
scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:request去重(不仅仅是爬过的网页不再爬取,保存的数据也会去重),爬虫持久化,和轻松实现分布式
2、Scrapy_redis的流程

3、复习redis的使用
3.1 redis是什么
redis是一个开源的,内存数据库,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串、哈希、列表、集合、有序集合等。
3.2 常用命令
`/etc/init.d/redis-server stop ` redis停止
`/etc/init.d/redis-server start` 启动
`/etc/init.d/redis-server restart` 重启
3.3. 远程连接redis数据库
`redis-cli -h <hostname> -p <port>` 远程连接redis数据库
3.4 redis-cli中的命令
`select 1` 切换到db1,总数据库为16个,默认为在db0
`keys *` 查看所有的redis键
`type "键"` 查看键的数据类型
`flushdb` 清空当前db
`flushall` 清空所有db
3.5 其他命令
https://www.cnblogs.com/nuochengze/p/12835560.html
http://www.redis.cn/commands.html(官方文档)
4、Scrapy_redis的使用
(1)clone github scrapy-redis源码文件
`git clone https://github.com/rolando/scrapy-redis.git`
(2)项目自带了三个demo(dmoz.py、mycrawler_redis.py、myspider_redis.py)
`my scrapy-redis/example-project`
4.1 scrapy_redis使用
4.1.1 scrapy_redis之domz
from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class DmozSpider(CrawlSpider): """Follow categories and extract links.""" name = 'dmoz' # 爬虫的名字 allowed_domains = ['dmoz-odp.org'] # 允许的域名 start_urls = ['http://www.dmoz-odp.org/'] # 开始的url rules = [ Rule(LinkExtractor( # 定义了一个url的提取规则,满足的交给callback函数处理 restrict_css=('.top-cat', '.sub-cat', '.cat-item') ), callback='parse_directory', follow=True), ] def parse_directory(self, response): for div in response.css('.title-and-desc'): yield { # 将提取的数据yield给engine 'name': div.css('.site-title::text').extract_first(), 'description': div.css('.site-descr::text').extract_first().strip(), 'link': div.css('a::attr(href)').extract_first(), } # domz的部分与和我们自己写的crawlspider没有任何区别
4.1.2 scrapy_redis之settings
# Scrapy settings for example project # # For simplicity, this file contains only the most important settings by # default. All the other settings are documented here: # # http://doc.scrapy.org/topics/settings.html # SPIDER_MODULES = ['example.spiders'] NEWSPIDER_MODULE = 'example.spiders' USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)' DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 指定哪个去重方法给request对象去重 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定scheduler队列 SCHEDULER_PERSIST = True # 队列中的内容是否持久保存,为False的时候会在关闭redis的时候清空redis #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" ITEM_PIPELINES = { 'example.pipelines.ExamplePipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400, # scrapy_redis实现的items保存到redis的pipeline } LOG_LEVEL = 'DEBUG' # 设置log_level等级 # Introduce an artifical delay to make use of parallelism. to speed up the # crawl. DOWNLOAD_DELAY = 1 # 设置下载延迟时间 REDIS_URL = 'redis://127.0.0.1:6379' # 指定redis的地址 # redis的地址也可以写成如下形式 # REDIS_HOST = '127.0.0.1' # REDIS_PORT = 6379
总结:(1)在我们平常自己通过`scrapy startproject demo`和`scrapy genspider (-t crawl) demo demo.com`后,通过改写DomeSpider(类)中的继承类,以及
(2)在settings中添加如下内容:
```
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 指定去重方法
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定scheduler队列
SCHEDULER_PERSIST = True # 队列中内容是否持久保存,为False的时候会在关闭redis的时候清空redis
REDIS_URL = "redis://127.0.0.1:6379" # 指定redis的地址
```
(3)那么就能实现一个scrapy_reids爬虫。
4.1.3 执行domz后,redis中的内容
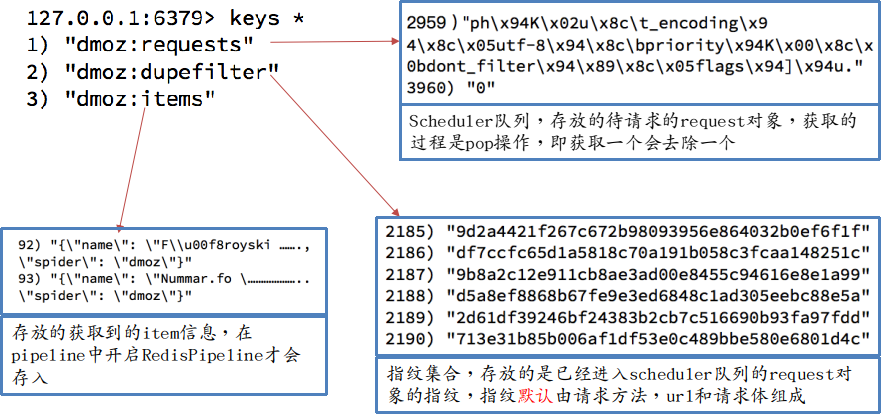
RedisPipeline中仅仅实现了item数据存储到redis的过程,可以通过自建一个pipeline让数据存储到任意地方。
4.2 分析scrapy_redis的dupefilter_class、scheduler等功能的实现
4.2.1 scrapy_redis中实现RedisPipeline
from scrapy.utils.misc import load_object from scrapy.utils.serialize import ScrapyJSONEncoder from twisted.internet.threads import deferToThread from . import connection, defaults default_serialize = ScrapyJSONEncoder().encode class RedisPipeline(object): """Pushes serialized item into a redis list/queue Settings -------- REDIS_ITEMS_KEY : str Redis key where to store items. REDIS_ITEMS_SERIALIZER : str Object path to serializer function. """ def __init__(self, server, key=defaults.PIPELINE_KEY, serialize_func=default_serialize): """Initialize pipeline. Parameters ---------- server : StrictRedis Redis client instance. key : str Redis key where to store items. serialize_func : callable Items serializer function. """ self.server = server self.key = key self.serialize = serialize_func @classmethod def from_settings(cls, settings): params = { 'server': connection.from_settings(settings), } if settings.get('REDIS_ITEMS_KEY'): params['key'] = settings['REDIS_ITEMS_KEY'] if settings.get('REDIS_ITEMS_SERIALIZER'): params['serialize_func'] = load_object( settings['REDIS_ITEMS_SERIALIZER'] ) return cls(**params) @classmethod def from_crawler(cls, crawler): return cls.from_settings(crawler.settings) def process_item(self, item, spider): # 使用了process_item方法,实现数据的保存 return deferToThread(self._process_item, item, spider) # 调用的一个异步线程去处理这个item def _process_item(self, item, spider): key = self.item_key(item, spider) data = self.serialize(item) self.server.rpush(key, data) # 向dmoz:items中添加item return item def item_key(self, item, spider): """Returns redis key based on given spider. Override this function to use a different key depending on the item and/or spider. """ return self.key % {'spider': spider.name}
4.2.2 scrapy_redis的RFPDupeFilter
def request_seen(self, request): # 判断request对象是否已经存在 """Returns True if request was already seen. Parameters ---------- request : scrapy.http.Request Returns ------- bool """ fp = self.request_fingerprint(request) # 通过request_fingerprint函数,取一个request # This returns the number of values added, zero if already exists. added = self.server.sadd(self.key, fp) # 添加到dupefilter中 """ 这是往一个集合添加经过request_fingerprint(即request指纹)后的request, 当集合中存在request,sadd添加不成功会返回一个0,当集合中不存在时,添加成功会返回一个1 """ return added == 0 # sadd返回0表示添加失败,即已经存在,return返回True,否则表示不存在,return返回False def request_fingerprint(self, request): """Returns a fingerprint for a given request. Parameters ---------- request : scrapy.http.Request Returns ------- str """ return request_fingerprint(request) """ self.request_fingerprint函数返回一个经过`from scrapy.utils.request import request_fingerprint`中 的request_fingerprint方法加密处理的request对象,形成唯一的指纹 """
def request_fingerprint(request, include_headers=None, keep_fragments=False): """ Return the request fingerprint. The request fingerprint is a hash that uniquely identifies the resource the request points to. For example, take the following two urls: http://www.example.com/query?id=111&cat=222 http://www.example.com/query?cat=222&id=111 Even though those are two different URLs both point to the same resource and are equivalent (i.e. they should return the same response). Another example are cookies used to store session ids. Suppose the following page is only accessible to authenticated users: http://www.example.com/members/offers.html Lot of sites use a cookie to store the session id, which adds a random component to the HTTP Request and thus should be ignored when calculating the fingerprint. For this reason, request headers are ignored by default when calculating the fingeprint. If you want to include specific headers use the include_headers argument, which is a list of Request headers to include. Also, servers usually ignore fragments in urls when handling requests, so they are also ignored by default when calculating the fingerprint. If you want to include them, set the keep_fragments argument to True (for instance when handling requests with a headless browser). """ if include_headers: include_headers = tuple(to_bytes(h.lower()) for h in sorted(include_headers)) cache = _fingerprint_cache.setdefault(request, {}) cache_key = (include_headers, keep_fragments) if cache_key not in cache: fp = hashlib.sha1() # sha1加密 fp.update(to_bytes(request.method)) # 添加请求方法 fp.update(to_bytes(canonicalize_url(request.url, keep_fragments=keep_fragments))) # 添加请求地址 fp.update(request.body or b'') # 添加请求体,post才会有request.body,get为None if include_headers: """ 添加请求头,默认不添加请求头(因为header的cookies中含有session id, 这在不同的网站中是随机的,会给sha1的计算结果带来误差) """ for hdr in include_headers: if hdr in request.headers: fp.update(hdr) for v in request.headers.getlist(hdr): fp.update(v) cache[cache_key] = fp.hexdigest() # 返回加密之后的16进制 return cache[cache_key]
4.2.3 scrapy_redis的scheduler
def close(self, reason): if not self.persist: # 如果在settings中设置为不持久,那么在退出的时候会清空 self.flush() def flush(self): self.df.clear() # 指的是存放dupefilter的redis self.queue.clear() # 指的是存放requests的redis def enqueue_request(self, request): if not request.dont_filter and self.df.request_seen(request): """ 不能加入待爬队列的条件 当前url需要(经过allow_domain)过滤并且request不存在dp的时候 但是,对于像百度贴吧这样的页面内容会更新的网址,可以设置dont_filter为True让其能够被反复抓取 """ self.df.log(request, self.spider) return False if self.stats: self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider) self.queue.push(request) return True
总结:domz相比较于之前的spider多了持久化和requests去重的功能,因此可以在以后的爬虫中,仿照domz的用法,使用scrapy_redis实现相同的功能。
settings中的配置都是可以自己设定的,因此我们可以去重写去重和调度器的方法,包括是否要把数据存储到redis(pipeline)。
4.3 scrapy_redis的RedisSpider
from scrapy_redis.spiders import RedisSpider class MySpider(RedisSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = 'myspider_redis' # 指定爬虫名 redis_key = 'myspider:start_urls' """ 指定redis中的start_urls的键,可以自行指定 启动的时候只需要往对应的键中存入url地址,不同的位置的爬虫就会来获取该url 启动爬虫的命令分为两个步骤: (1)scrapy crawl myspider_redis(或者scrapy runspider myspider_redis)让爬虫就绪 (2)在redis中输入lpush myspider:start_urls "https://www.baidu.com"让爬虫从这个url开始爬取 """ allowed_domains = ["baidu.com"] # 手动指定allowed_domains # def __init__(self, *args, **kwargs): # 动态的设置allowed_domains,一般不需要,直接手动指定即可 # # Dynamically define the allowed domains list. # domain = kwargs.pop('domain', '') # self.allowed_domains = filter(None, domain.split(',')) # super(MySpider, self).__init__(*args, **kwargs) def parse(self, response): return { 'name': response.css('title::text').extract_first(), 'url': response.url, }
4.4 scrapy_redis的RedisCrawlSpider
from scrapy.spiders import Rule from scrapy.linkextractors import LinkExtractor from scrapy_redis.spiders import RedisCrawlSpider class MyCrawler(RedisCrawlSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = 'mycrawler_redis' # 爬虫名字 redis_key = 'mycrawler:start_urls' # start_url的redis的键 allowed_domains = ['baidu.com'] # 手动定制alloed_domains rules = ( # 和crawl一样,指定url的过滤规则 # follow all links Rule(LinkExtractor(), callback='parse_page', follow=True), ) # def __init__(self, *args, **kwargs): # 动态生成all_domain,不是必须的 # # Dynamically define the allowed domains list. # domain = kwargs.pop('domain', '') # self.allowed_domains = filter(None, domain.split(',')) # super(MyCrawler, self).__init__(*args, **kwargs) def parse_page(self, response): return { 'name': response.css('title::text').extract_first(), 'url': response.url, }