为什么要做 batch normalization
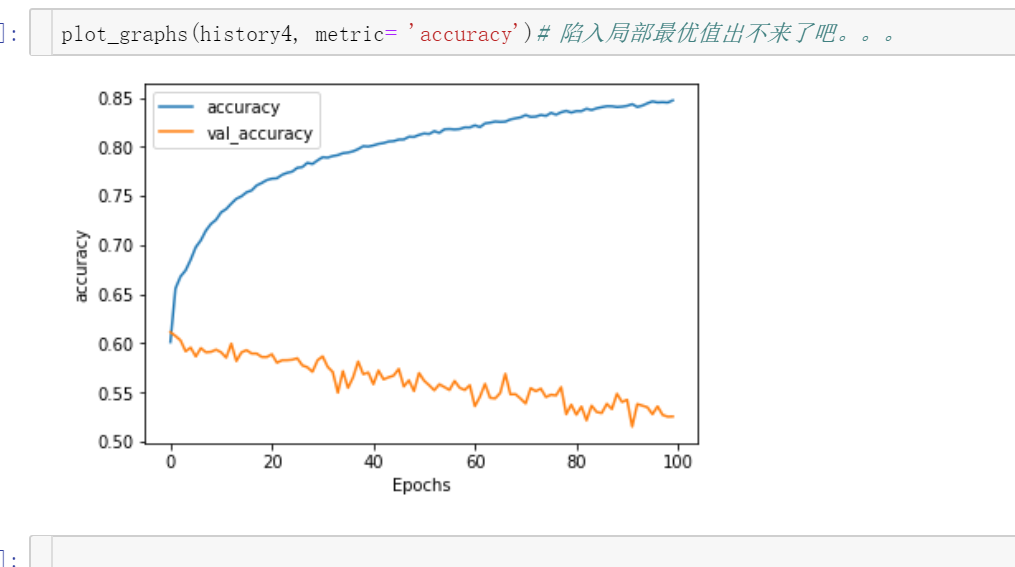
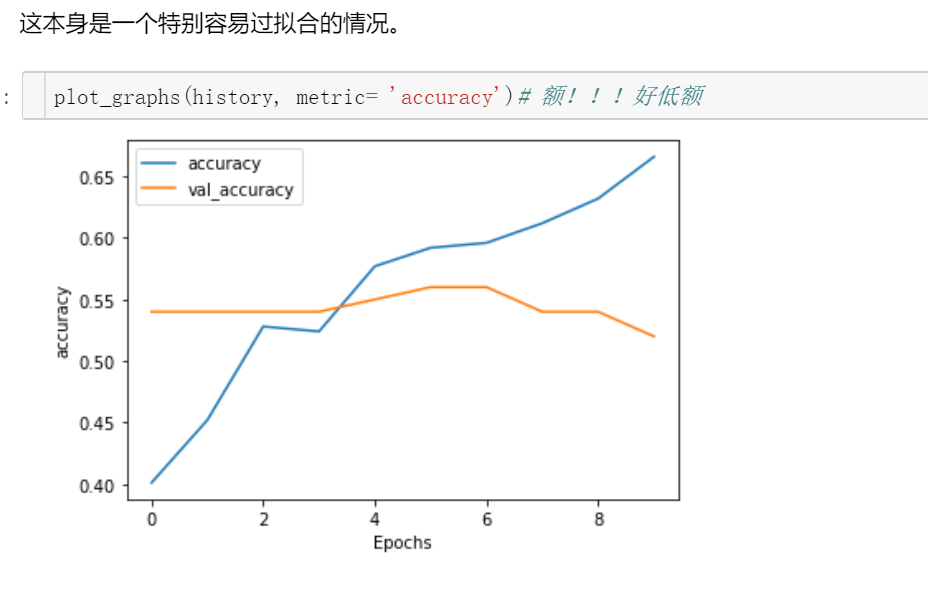
没有加batch normalization,过拟合,也就是训练集的效果还不错,但是测试集的效果真的差
网络一旦训练起来,参数就要发生更新,除了输入层的数据外(因为输入层数据已经被人为地进行归一化了),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练时前面层训练参数的更新将导致后面层输入数据分布的变化。举个例子,网络的第二层输入是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为“Internal Covariate Shift”。为了解决在训练过程中,中间层数据分布发生改变的情况,Batch Normalization诞生了。
BN层
就像激活层、卷积层、全连接层、池化层一样,BN层也属于网络的一层。在前面我们提到网络除了输出层外,其它层因为低层网络在训练的时候更新了参数,而引起后面层输入数据分布的变化。这个时候我们就会想,如果在每一层输入的时候,再加个预处理操作那该有多好啊,比如说归一化一下,这样我们就可以解决前面所提的“Internal Covariate Shift”的问题了。
而事实上,paper的算法本质原理就是这样:在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。不过这里的归一化层,可不像我们想象的那么简单,它是一个可学习、有参数的网络层。
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正太分布而不是萝莉分布(哦,是正态分布),其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。张俊林博客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
以一个图为例,epoch设置为100
这是tokenizer之后词条化的处理

很明显需要特征标准化处理,因为差别挺大的,某些数值较小的特征是不显著的。
用keras实现还是比较简单的,只要在dense层后面增加一个标准化层就好了
# import BatchNormalization
from keras.layers.normalization import BatchNormalization
# instantiate model
model = Sequential()
# we can think of this chunk as the input layer
model.add(Dense(64, input_dim=14, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('tanh'))
# we can think of this chunk as the hidden layer
model.add(Dense(64, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('tanh'))
# we can think of this chunk as the output layer
model.add(Dense(2, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('softmax'))
# setting up the optimization of our weights
sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd)
# running the fitting
model.fit(X_train, y_train, nb_epoch=20, batch_size=16, show_accuracy=True, validation_split=0.2, verbose = 2)
改完之后结果确实收敛了
bn+drop会产生1+1<1的效果
明确dropout和BN结合使用使模型性能下降的连接方式,用通俗的话讲,就是你先在网络的内部使用dropout,随后再跟上一个BN层,而且这个BN层还不止一个。那么问题出在哪呢?原因有二。首先,如上图所示,因为训练时采用了dropout,虽然通过除以(1-p)的方式来使得训练和测试时,每个神经元输入的期望大致相同,但是他们的方差却不一样。第二,BN是采用训练时得到的均值和方差对数据进行归一化的,现在dropout层的方差都不一样了,那还搞毛,一步错步步错,最终导致输出不准确,影响最后的性能。Thomas_He666