1.swift 是什么?
OpenStackObject Storage (Swift) 是开源的,用来创建可扩展的、冗余的、对象存储(引擎)。 swift使用标准化的服务器存储 PB 级可用数据。但它并不是文件系统 (file system) ,实时的数据存储系统(real-timedata storage system) 。 swift 看起来更像是一个长期的存储系统 (long term storage system) ,为了获得、调用、更新一些静态的永久性的数据。比如说,适合存储一些类型的数据:虚拟机镜像,图片存储,邮件存储,文档的备份。没有“单点”或者主控结点 (master point of control) , swift看起来具有更强的扩展性、冗余和持久性。
2.swift 能做什么?
长于存储非结构化数据,大、小文件性能据说都很好(目前没有测试数据, adrian otto 说测试过10 亿个 1byte 数据)。
3.swift 不能做什么?
- Objects must be <5GB : swift 1.2 之后已经对 object 的大小不做限制
- Not a Filesystem :不是文件系统。 swift 使用 REST API ,而不是使用传统意义上的文件操作命令, open(), read(), write(), seek(), 和 close() 等。
- No File Locking :干脆不支持“文件锁”。其实在 swift 中,“锁”的概念是没有必要的。
- No Directory Hierarchies :没有文件目录结构。 swift 可以模拟目录结构,但没有必要
- Not a Database :不是数据库。 swift 使用 account-container-object 的概念存储 object ,可以列表出指定 container 中的 object ,不支持 server 端的查询和处理操作。
----------------------------------------------------------------------------------------------------------------------------------------------------
Account
出于访问安全性考虑,使用Swift系统,每个用户必须有一个账号(Account)。只有通过Swift验证的账号才能访问Swift系统中的数据。提供账号验证的节点被称为Account Server。Swift中由Swauth提供账号权限认证服务。用户通过账号验证后将获得一个验证字符串(authentication token.),后续的每次数据访问操作都需要传递这个字符串。
Container
Swift中的container可以类比Windows操作系统中的文件夹或者Unix类操作系统中的目录,用于组织管理数据,所不同的是container不能嵌套。数据都以Object的形式存放在container中
Swift有如下几个特性:
1、极高的数据持久性,上面已经提到了。
2、各个存储的节点完全对等,是对称的系统架构。
3、因为是对称的系统架构,扩容的时候只需简单的增加机器,扩展性很好。
4、不存在单节点故障,前面提到因为各个节点完全对等,没有所谓的“主从”结构。
存储在Swift里面的数据有好几个备份,而且各个节点之间是平等的关系,没有“主节点”这个概念,因此任意一个节点出现故障时,数据并不会丢失(注意,这里是任意一个节点出现故障)。而与它形成对比的是Hadoop的HDFS。
HDFS有一个元数据存储节点,保存在HDFS集群中的所有文件都会在元数据存储节点上保留一份元数据,元数据记录了每个文件的一些必要的信息,例如文件大小,属于哪个用户,更新的时间,存储在HDFS哪台数据服务器上等等,感觉这个元数据的概念有点类似Linux中文件的inode信息。HDFS的缺点是一旦元数据服务器挂掉,那么整个HDFS集群就玩完了。当然,这只是我对HDFS一点浅显的认识,真正的部署的时候肯定还有很多保护措施,HDFS的健壮性是很好的。
回到Swift上,Swift的元数据存储是完全均匀随机分布的,并且与对象文件存储一样,元数据也会存储多份。
无论是HDFS也好,Swift也好,必须面对的一个问题就是如何保持数据的一致性。 因为一个文件并不是只保存一份的,在Swift中默认要保存3个副本,当更新的时候这3个文件要同时更新,当其中一个文件损坏时必须能迅速的复制一份完整的文件来替换。
Swift有3个服务来解决这个问题:Auditor、Updater和Replicator。 Auditor运行在每个Swift服务器的后台持续地扫描磁盘来检测数据的完整性。如果发现数据损坏,Auditor就会将该文件移动到隔离区域,然后由Replicator负责用一个完好的拷贝来替代该数据。如果更新失败,该次更新在本地文件系统上会被加入队列,然后Updaters会继续处理这些失败了的更新工作。
--------------------------------------------------------------------------------------------------------------------------------------------------
刚才提到过,Swift没有元数据服务器,也就是说,不会特意为每一个文件生成一个类似inode的东西,并且保存在特定的一个服务器上,这一点与HDFS有很大的不同。那么剩下最后一个问题:Client要存储一个文件,用什么策略决定存在哪台Storage Node上呢?(为了更好的表示,我们可以看下图如下图所示,图1为Swift架构,图2为对象存储)
<ignore_js_op>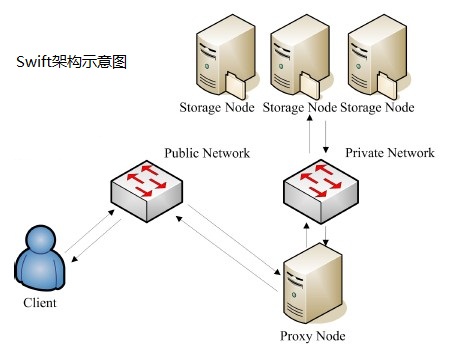
图1Swift部分架构
<ignore_js_op>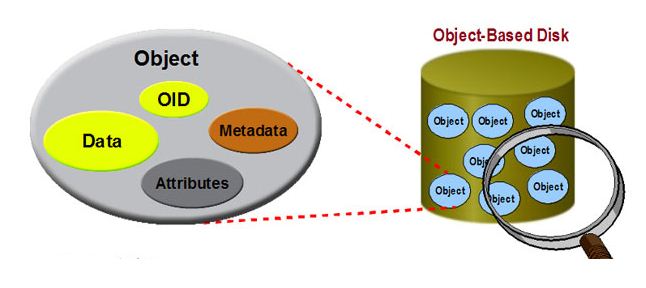
图2对象存储
可以看出,在对象存储中,存储的不仅是数据,还有与丰富的数据相关的属性信息。系统会给每一个对象分配一个唯一的ID。对象本身是平等的,所有的ID都属于一个平坦的地址空间,而并非文件系统那样的树状逻辑结构。
这种存储结构带来的好处是可以实现数据的智能化管理,因为对象本身包含了元数据信息,甚至更多的属性,我们可以根据这些信息对对象进行高效的管理。例如我们可以制定这样的存储策略,如果对象中包含priority:high,这样的属性,我们就对文件做比平常文件多的备份次数。
平坦地址空间的设计使得访问对象只通过一个唯一的ID标识即可,不需要复杂的路径结构。
因此,可以知道Swift中没有“路径”这个概念,所以也没有有所谓的“文件夹”这样的概念。
现在,我们有了对象的ID了,那么如何根据这个ID把对象存在合适的Storage Node呢?
在解决这个问题时,要注意几个约束条件:
1、能快速的做一个决策,到底存在哪个Node上。
解决这个问题,我们的第一反应应该是根据ID做一个Hash,不错,Swift确实是这么做的。
2、Swift里面存储着成千上万,甚至上亿个 Object,当我们往集群中增加Storage Node的时候,最好不影响已有的数据。
对于固定数量的Storage Node,使用普通的取模Hash法应该是又快又好的,当时当Node的数量会变动时,这种简单的Hash就不行了,因为这时所有对象的Hash值都会改变,这对于存储了上亿个对象的Swift来说是相当可怕的。
解决的方法是使用“一致性Hash法”。
一致性哈希算法的基本实现原理是将机器节点和key(在本文里就是对象的ID)值都按照一样的hash算法映射到一个0~2^32的圆环上。当有一个写入缓存的请求到来时,计算Key值k对应的哈希值Hash(k),如果该值正好对应之前某个机器节点的Hash值,则直接写入该机器节点,如果没有对应的机器节点,则顺时针查找下一个节点,进行写入,如果超过2^32还没找到对应节点,则从0开始查找(因为是环状结构)。
<ignore_js_op>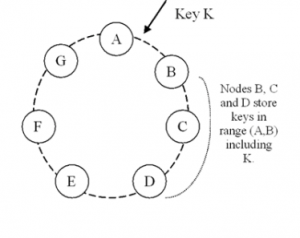
经过一致性哈希算法散列之后,当有新的机器加入时,将只影响一台机器的存储情况,例如新加入的节点H的散列在B与C之间,则原先由C处理的一些数据可能将移至H处理,而其他所有节点的处理情况都将保持不变,因此表现出很好的单调性。而如果删除一台机器,例如删除C节点,此时原来由C处理的数据将移至D节点,而其它节点的处理情况仍然不变。而由于在机器节点散列和缓冲内容散列时都采用了同一种散列算法,因此也很好得降低了分散性和负载。而通过引入虚拟节点的方式,也大大提高了平衡性。
上面提到了什么是结构化数据,什么是非结构化数据,这里补充一下:
结构化数据
简单来说就是数据库。结合到典型场景中更容易理解,比如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。这些应用需要哪些存储方案呢?基本包括高速存储应用需求、数据备份需求、数据共享需求以及数据容灾需求。
非结构化数据
包括视频、音频、图片、图像、文档、文本等形式。具体到典型案例中,像是医疗影像系统、教育视频点播、视频监控、国土GIS、设计院、文件服务器(PDM/FTP)、媒体资源管理等具体应用,这些行业对于存储需求包括数据存储、数据备份以及数据共享等。
半结构化数据
包括邮件、HTML、报表、资源库等等,典型场景如邮件系统、WEB集群、教学资源库、数据挖掘系统、档案系统等等。这些应用对于数据存储、数据备份、数据共享以及数据归档 等基本存储需求。