synchronized关键字的底层原理?
用于线程同步,加锁。
可用于类,对象,块。一般是对一个对象进行加锁。
// 线程1 synchronized(myObject) { -> 类的class对象来走的 // 一大堆的代码 synchronized(myObject) { // 一大堆的代码 } }
synchronize底层原理与JVM指令和monitor有关系。深入涉及CPU硬件原理,原则性、可见性、有序性、指令重排、偏向锁、JDK的对其进行的优化。
synchronized关键字,底层编译后的JVM指令中,使用monitorenter和monitorexit指令。
monitorenter:加锁
monitorexit:解锁
如果一个线程第一次synchronized那里,获取到了myObject对象的monitor的锁,计数器加1,然后第二次synchronized那里,会再次获取myObject对象的monitor的锁,这个就是重入加锁了,然后计数器会再次加1,变成2。
这个时候,其他的线程在第一次synchronized那里,会发现说myObject对象的monitor锁的计数器是大于0的,意味着被别人加锁了,然后此时线程就会进入block阻塞状态,什么都干不了,就是等着获取锁。
接着如果出了synchronized修饰的代码片段的范围,就会有一个monitorexit的指令,在底层。此时获取锁的线程就会对那个对象的monitor的计数器减1,如果有多次重入加锁就会对应多次减1,直到最后,计数器是0。
聊聊CAS的理解以及其底层实现原理?
CAS: Compare And Set
CAS在底层的硬件级别保证原子性,同一时间只有一个线程可以执行CAS,先比较再设置,其他线程的CAS同时执行此时会失败。

ConcurrentHashMap实现线程安全的底层原理是什么?
JDK1.8之前,多个数组,分段加锁,一个数组一个锁。
JDK1.8之后,优化细粒度,一个数组,每个元素进行CAS,如果失败,则有线程已经用synchronized对元素加锁。
链表+红黑树处理,对数组每个元素加锁。
多个线程要访问同一个数据,synchronized加锁,CAS去进行安全的累加,去实现多线程场景下的安全的更新一个数据的效果。
JDK1.8 [一个大的数组],数组里每个元素进行put操作,都是有一个不同的锁,刚开始进行put的时候,如果两个线程都是在数组[5]这个位置进行put,这个时候,对数组[5]这个位置进行put的时候,采取的是CAS的策略,同一个时间,只有一个线程能成功执行这个CAS,就是说他刚开始先获取一下数组[5]这个位置的值,是null,然后执行CAS,线程1,比较一下,put进去我的这条数据,同时间,其他的线程执行CAS,都会失败。
通过对数组每个元素执行CAS的策略,如果是很多线程对数组里不同的元素执行put,大家是没有关系的,可以并行。
如果其他线程失败了,其他线程此时会发现数组[5]这位置,已经给刚才有线程放进去值了,就需要在这个位置基于链表+红黑树来进行处理,synchronized(数组[5]),加锁,基于链表或者是红黑树在这个位置插进去自己的数据,如果你是对数组里同一个位置的元素进行操作,才会加锁串行化处理;如果是对数组不同位置的元素操作,此时大家可以并发执行的。
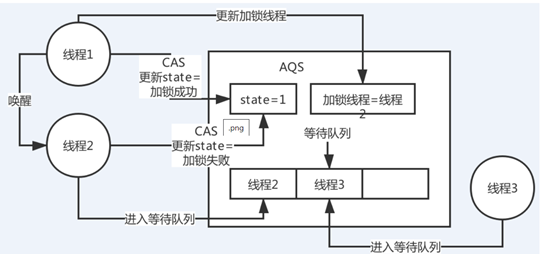
你对JDK中的AQS的理解?AQS的实现原理?
ReentrantLock
state变量 -> CAS -> 失败后进入队列等待 -> 释放锁之后唤醒
非公平锁 公平锁
AQS=Abstract Queue Synchronizer 抽象队列同步器
线程池连环炮:
说说线程池的底层工作原理?说说线程池核心配置参数?线程池队列满了之后会发生什么事情?
如果在线程中使用无界阻塞队列会发生什么问题?如果宕机,线程池的阻塞队列中的请求怎么办?
1. 线程池底层工作原理?
固定数量线程池:
ExecutorService threadPool = Executors.newFixedThreadPool(3) -> 3: corePoolSize threadPool.submit(new Callable() { public void run() {} });
提交任务,先看一下线程池里的线程数量是否小于corePoolSize,也就是3,如果小于,直接创建一个线程出来执行你的任务。
如果执行完你的任务之后,这个线程是不会死掉的,他会尝试从一个无界的LinkedBlockingQueue里获取新的任务,如果没有新的任务,此时就会阻塞住,等待新的任务到来。
你持续提交任务,上述流程反复执行,只要线程池的线程数量小于corePoolSize,都会直接创建新线程来执行这个任务,执行完了就尝试从无界队列里获取任务,直到线程池里有corePoolSize个线程。
接着再次提交任务,会发现线程数量已经跟corePoolSize一样大了,此时就直接把任务放入队列中就可以了,线程会争抢获取任务执行的,如果所有的线程此时都在执行任务,那么无界队列里的任务就可能会越来越多。
2. 说说线程池的核心配置参数都是干什么的?平时我们应该怎么用?
线程池类:ThreadPoolExecutor
创建一个线程池就是这样子的,corePoolSize,maximumPoolSize,keepAliveTime,queue,这几个东西,如果你不用fixed之类的线程池,自己完全可以通过这个构造函数就创建自己的线程池。
corePoolSize:3
maximumPoolSize:Integer.MAX_VALUE
keepAliveTime:60s
new ArrayBlockingQueue<Runnable>(200)
设你的maximumPoolSize是比corePoolSize大的,此时会继续创建额外的线程放入线程池里,来处理这些任务,然后超过corePoolSize数量的线程如果处理完了一个任务也会尝试从队列里去获取任务来执行。
如果额外线程都创建完了去处理任务,队列还是满的,此时还有新的任务来只能拒绝。有几种reject策略,可以传入RejectedExecutionHandler接口。可以自己实现这个接口,实现对这些超出数量的任务的处理
ThreadPoolExecutor已经实现4个拒绝策略:
(1)AbortPolicy:直接抛异常
(2)DiscardPolicy:当前任务会强制调用run先执行,任务将由调用者线程(可能是主线程)去执行。缺点可能会阻塞主线程。
(3)DiscardOldestPolicy:抛弃任务队列中最旧任务
(4)CallerRunsPolicy:抛弃当前将要加入队列的任务
(5)自定义
如果后续慢慢的队列里没任务了,线程空闲了,超过corePoolSize的线程会自动释放掉,在keepAliveTime之后就会释放。
如果线上机器突然宕机,线程池的阻塞队列中的请求怎么办?
必然导致线程池里积压的任务会丢失。
解决方案:
如果你要提交一个任务到线程池里,在插入之前,先在数据库里插入这个任务信息,增加状态:未提交、已提交、已完成等。
提交成功之后,更新他的状态是已提交状态。
系统重启后,后期去查询数据库里未提交和已提交的任务,把任务信息读取出来,重新提交到线程池,继续执行。
参考资料:
互联网Java工程师面试突击(第三季)-- 中华石杉