Druid一种实时数仓,针对的场景和目的,如下比较明确
Druid was originally designed to solve problems around ingesting and exploring large quantities of transactional events (log data).
Our goal is to rapidly compute drill-downs and aggregates(roll-ups) over this data.
这篇文章主要内容是描述Druid的架构,对实时数仓的设计是否有借鉴作用
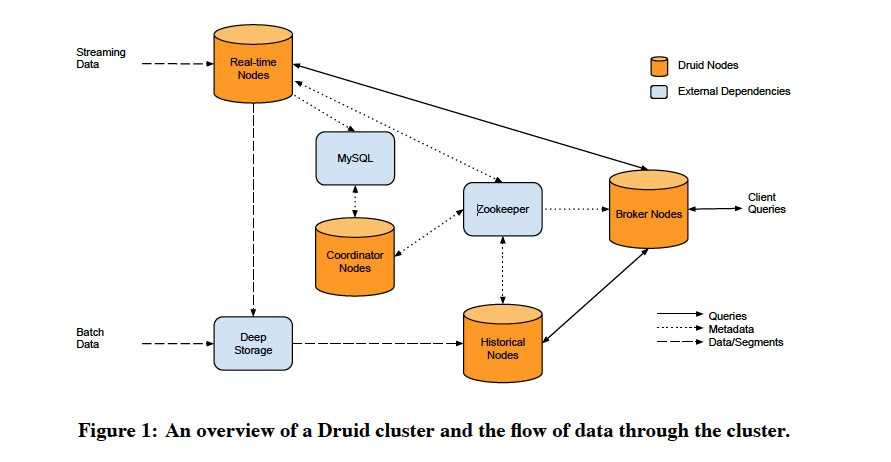
存储上,
Mysql用来存储元数据配置
Zookeeper用于分布式一致性,选主
Deep Stroage,比如S3,用来放历史数据
节点上,
Real-time Nodes
主要是用于消费和查询实时数据的,
数据会先在内存中建立index,避免oom,到达一定行数阈值,会presist到磁盘,presist的时候会由行存变换到列存格式
一个后台程序会不断的把磁盘上的indexes,进行merge,并且上传到deep storage

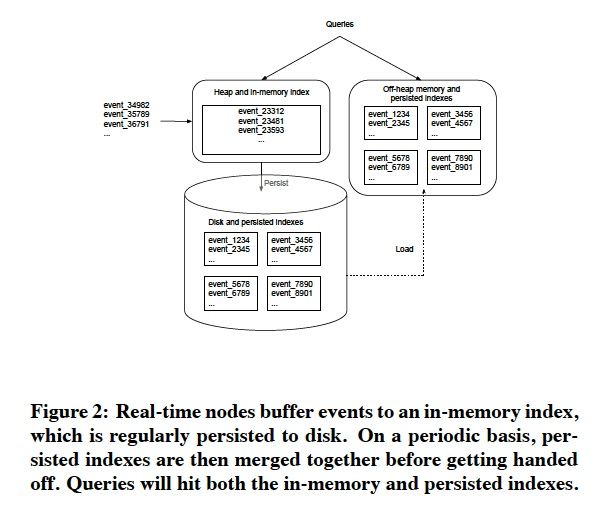
下面举了个例子,
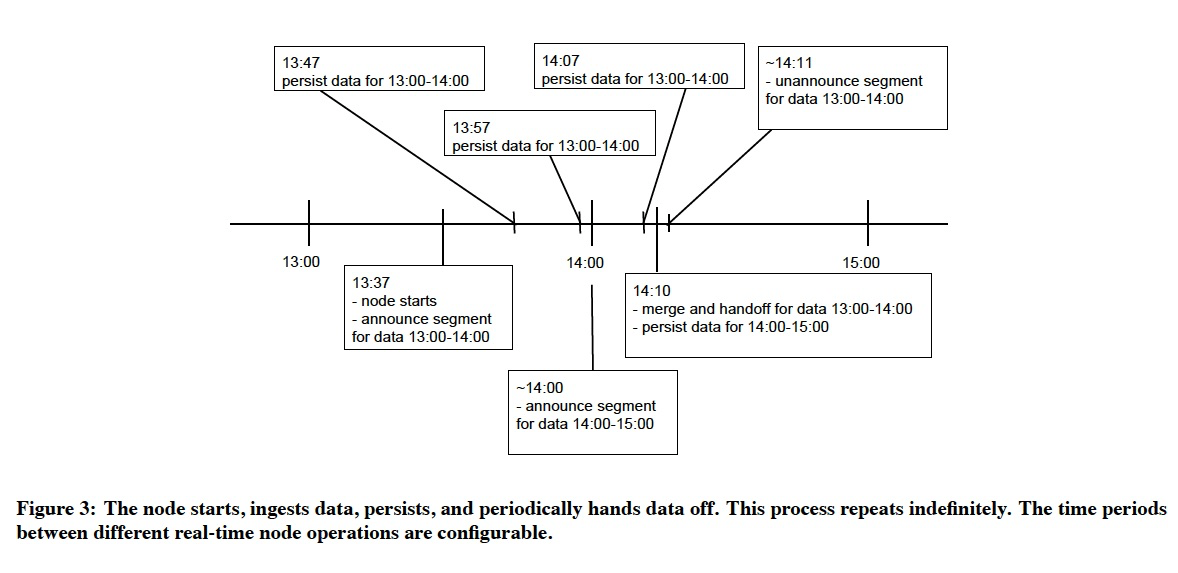
何时会flush,presist?何时会merge,上传?
这里还考虑了late data,但是一旦窗口结束,该时间段的数据完成merge和上传,实时节点会拒绝too late 数据


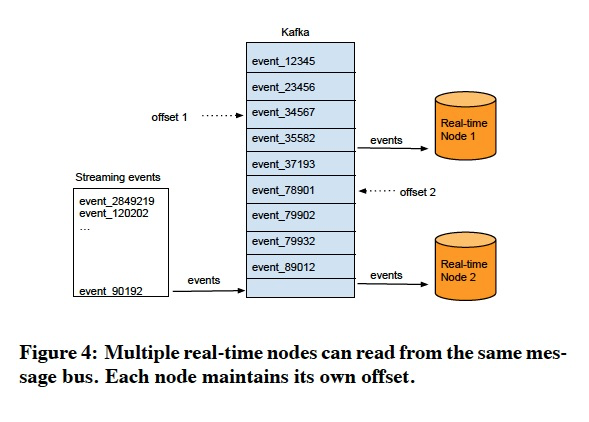
Druid实时节点的scalability和availability,都是依赖kafka来保障的,降低druid本身的设计成本


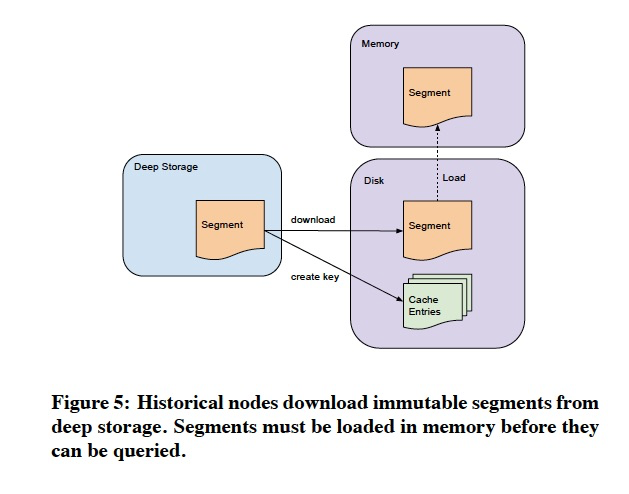
Historical Nodes
这个节点的设计比较简单了,不涉及写入
只是不变数据segments的加载和查询,为了加载效率,需要实现local cache

Brokers
routers,把查询分解,分别去查询real-time和historical节点
还需要在返回前,merge不同节点的数据,这里merge不是怎么简单的,论文并没有写详细的过程,比如top10,怎么merge
为了提升查询性能,
会增加查询cache,这里只会对historical node的查询结果进行cache,不会cache real-time节点的返回,因为变的太快


Coordinator Nodes
中控节点
管下面这些事,



综合一下,本论文,主要描述冷热数据分离,读写分离的一套实时数仓的架构