并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性
先区分一组概念,parallel和distributed的区别
总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不用考虑通信代价
distributed,要充分的考虑通信代价,failover的问题,更为复杂

Process Model
先解释一下概念,
process model,指数据库系统架构设计,用于支持多用户的并发请求
worker,用于执行客户端tasks的DBMS组件

通常的process model有3种,
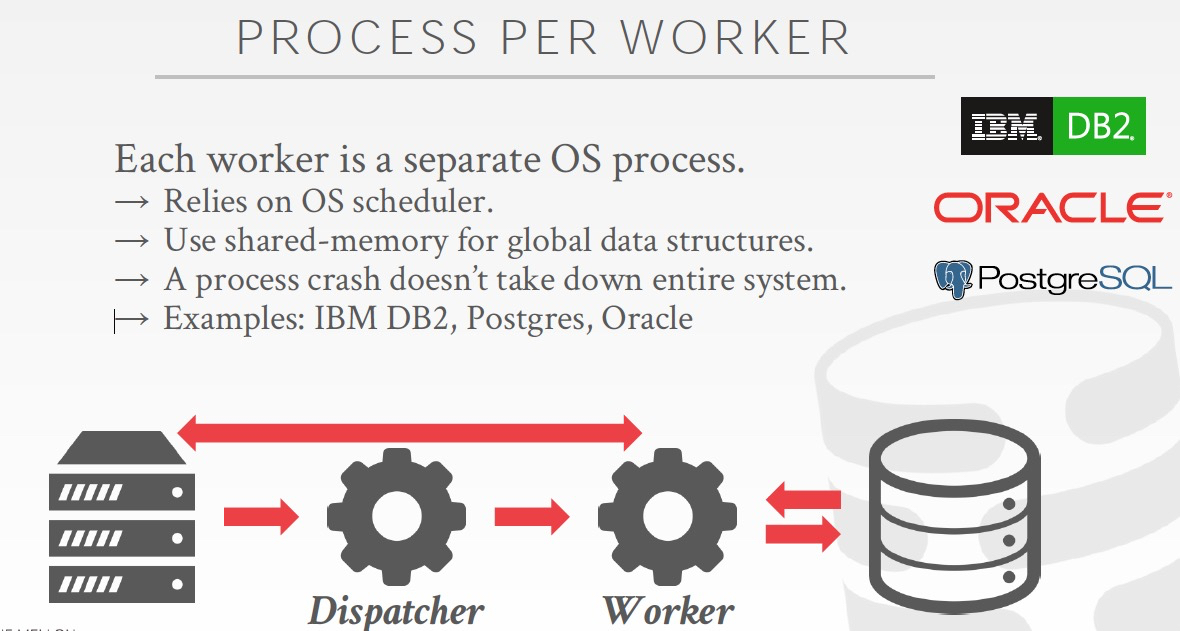
Process Per Worker,每个worker都是一个系统进程,
进程最大优点,隔离好,不会因为一个worker影响整个库,但问题肯定是太重,比较低效,支持不了高并发
早期的数据库往往采用这个方案,是因为那个时候线程的方案还不成熟
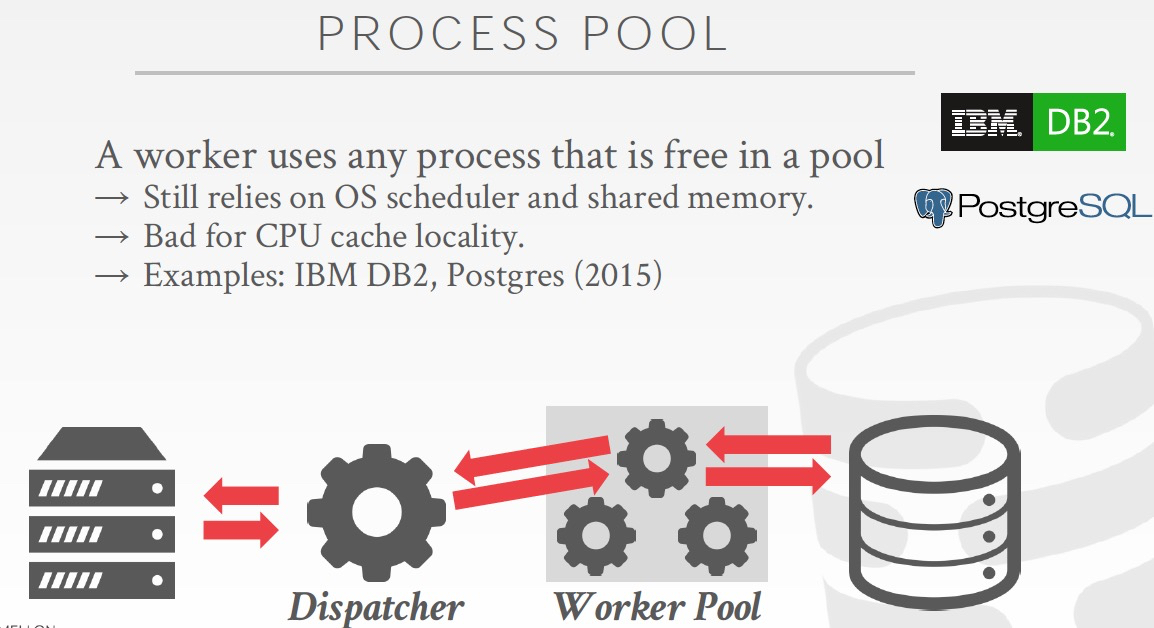
Process Pool,这个方案和上面的没有本质不同,只是worker从只用一个进程,到使用一个进程pool
Pool的好处,一个worker可以同时相应多个请求,而且一个进程hang住了,不会影响worker工作
坏处,一个client的连续的请求会分配到不同的进程,那么CPU cache locality上就不是很好
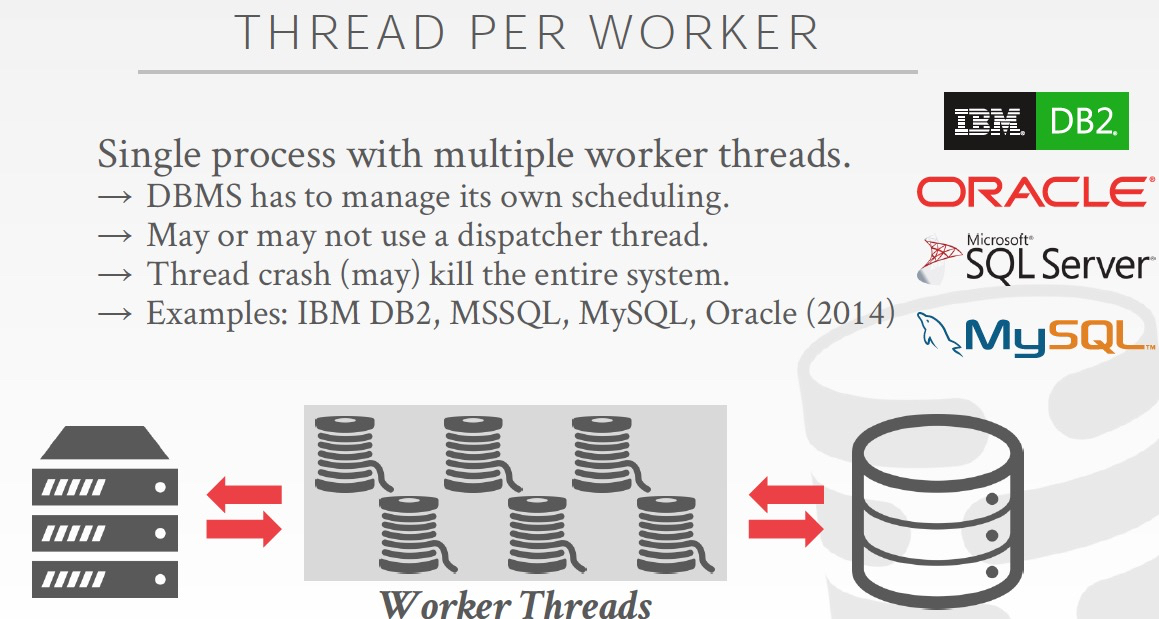
Thread Per Worker
这个是当前主流的process model,
一个数据库实例是一个进程,worker通过线程实现,这样由DBMS自己进行线程调度
线程模型明显更加轻量,更容易应对高并发的场景,而且线程间通信的成本很低
最大的问题是隔离性不好,一个线程可能把整个库搞挂

Parallel Execution
并行有两种,
不同的query,并行的执行
一条query中不同的operation并行的执行

Inter-query,很容易理解,要解决的也就是并发控制问题,这个后面会讲
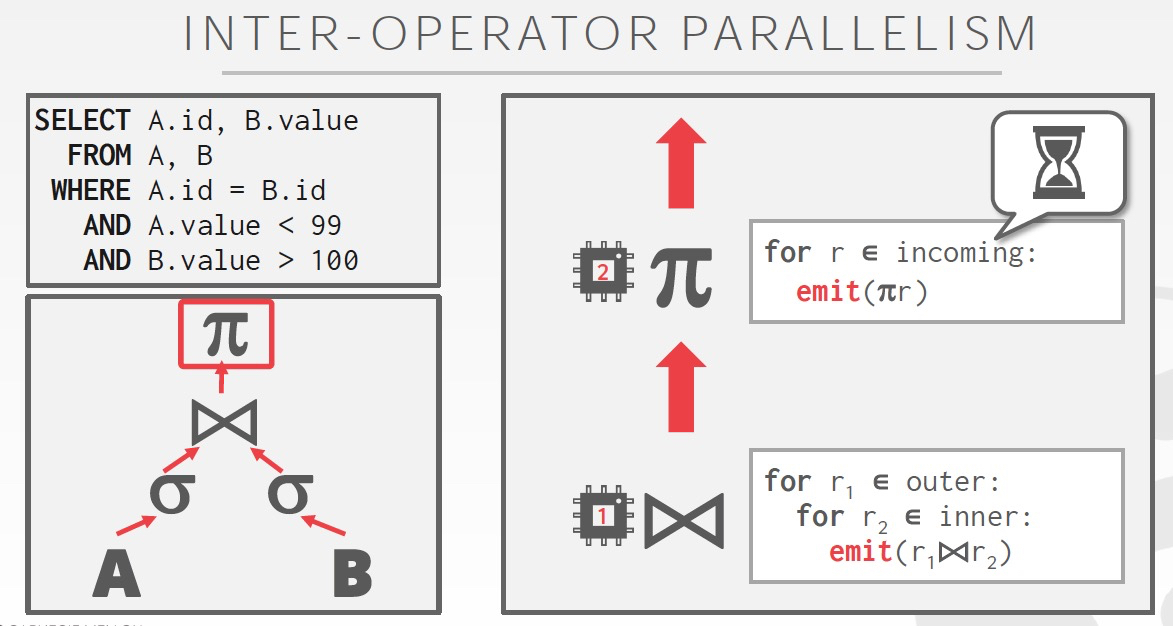
这里重点说下Intra-query,它也是包含两种类型,Intra-operator和Inter-operator
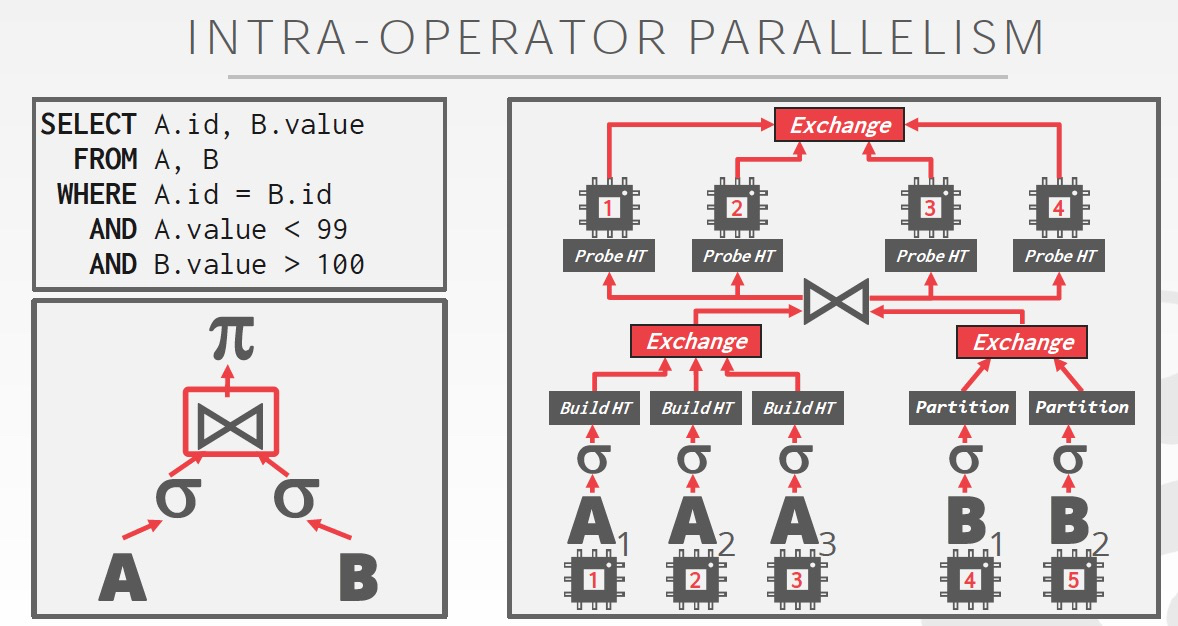
首先是Intra-operator,水平并行,MPP
把数据水平分成多份,分别执行,有个Exchange,类似latch,等待所有分片都执行完,做相应的merge然后再往上发送

然后是,Inter-operator,DAG方式,pipeline,streaming process

I/O PARALLELISM
前面光说了,平行处理,但是数据库的瓶颈大部分在磁盘IO
所以如果要并行计算,关键是数据要能划分开,并行的读取
一些比较简单的方法如下,
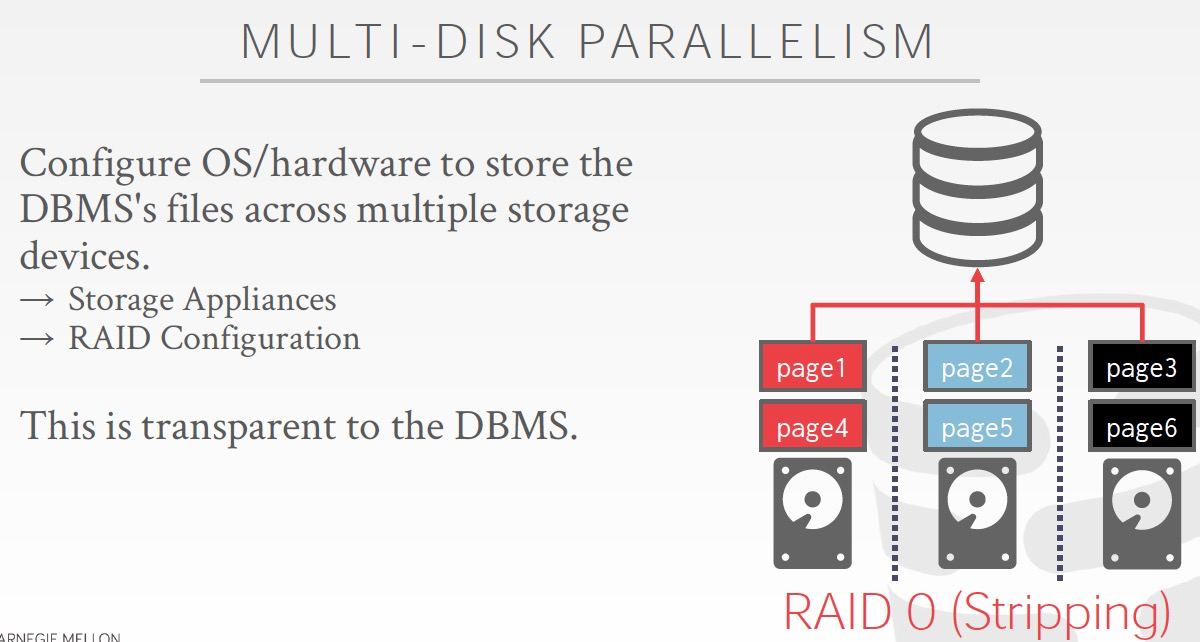
人为的分多块盘,或是用raid0,raid1

但是如果要在表级别做划分,就需要更为复杂的方法,对数据做partition

划分又分为两种,
垂直划分,列存
水平划分,sharding

