这个星期通过学习mooc上的爬虫教程,初步学习掌握了一些关于爬虫的知识。于是我就想通过爬虫这个工具来爬取2019年hg的录取分数线。进而复习巩固这星期所学的知识。
关于爬虫的实现,我的思维步骤是分为三步:
1、首先我们要获取网页的html内容,这个过程通过我们的第三方库requests库(库中的get函数)便可以实现,我将其想象成获取“原材料”。
2、第二步就是我们要对html网页内容就行分析,分析之后要找到我们想要找到的信息以便后面我们的数据处理。那通过什么来分析html网页内容呢?就要通过bs4库(from bs4 import BeatifulSoup)这个重要工具对其中的内容进行分析,我将其想象成把原材料进行处理并做成汤的过程(soup = BeautifulSoup(demo,'html.parser'))这样想也十分形象。通过find_all(),<>.string等函数获取你想要的信息。
3、最后一步那就是对数据的处理了,可以根据你所想要的效果对数据进行处理,建议可以将数据放入列表中形成二维数据,这样也方便我们对处理的各种处理。我将其想象成对汤的再加工,最后通过自己的努力就可以得到一锅美味的汤了。
我首先找到了网站'http://www.gaokw.com/gk/gxfsx/189856.html',我通过直接查询网页的源代码大致了解了一下html的内容。我通过requests库顺利爬取到了网页的内容。之后在提取信息的过程中我需要了问题,就是我所想找的内容所对应的标签并不是唯一的,其他内容所对应的标签发生了重合。这对我专门提取信息造成了困难。图片如下:



那么这个问题该如何解决呢?通常可以先将标签所对应的所有内容都提取出来,放在列表中,然后找去信息之间的不同之处,剔除我们所不要的信息。再对留下的信息进行处理。这是常规的思路。但这次我所提取的内容不多,这次我提取我所想要的信息是直接通过列表的索引来实现的,来的也比较快。提取之后又出现了新的问题,图片如下

列表元素中有很多‘ ’,' ',' ’的部分,这时候我是通过strip()来处理,这个大家也很熟悉,这对字符串进行处理的常用函数。strip()若括号中不含参数,可以去初字符串开头和结尾的空格或者换行字符。这样就对数据进行了有效的处理,效果如下:

接下来就是将这些数据再放入一个列表中,形成一个二维数据。之后便可进行通过列表索引对数据进行处理了,最终效果如下(本人比较懒很多元素都没有打印出来):
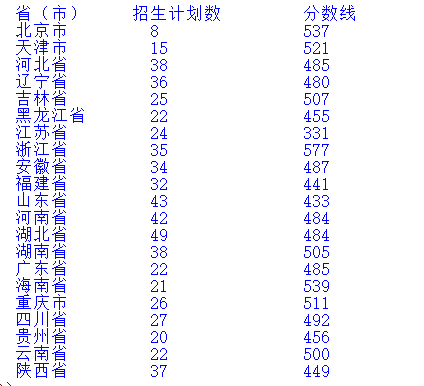
源代码如下:
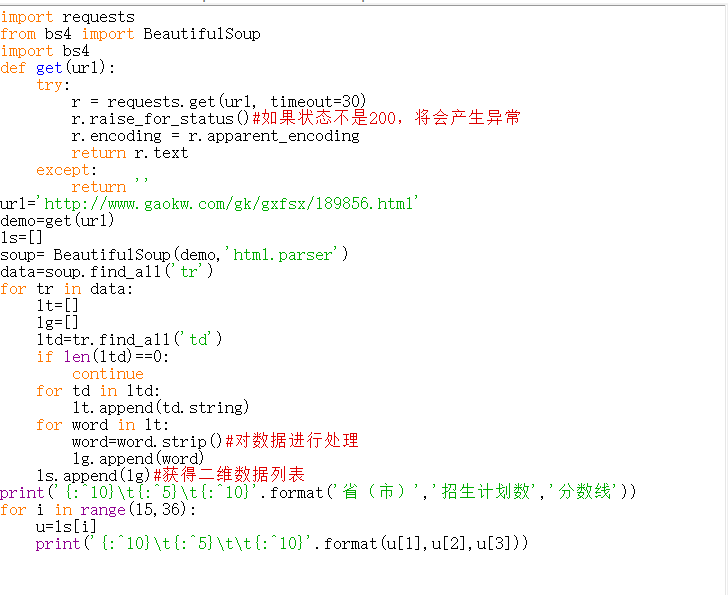
可以看出我的代码改进的地方还有很多,对于函数这方面的使用还是不太到位,以及对数据的处理最终产生的效果也比较一般,水平也比较有限。所以也希望同学们多多交流意见,多多批评指正。