环境配置需要安装的包
pip install pandas
pip install jieba
pip install sklearn
一、数据获取
利用python抓取美团的数据集,获取非空的数据,抓取的字段包括店名、评论、评论的打分
二、数据预处理
导入sklearn的包
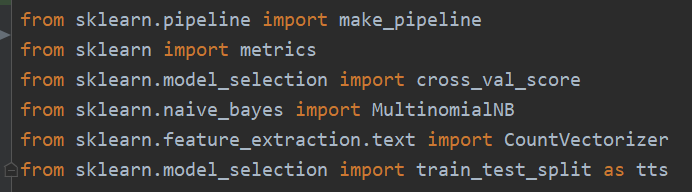
系统默认的包
1.数据洗涤
将爬取的数据进行数据洗涤,去除符号以及标点等,将结果按id和对应的评论重新组合在一起
形成一条数据一个评分
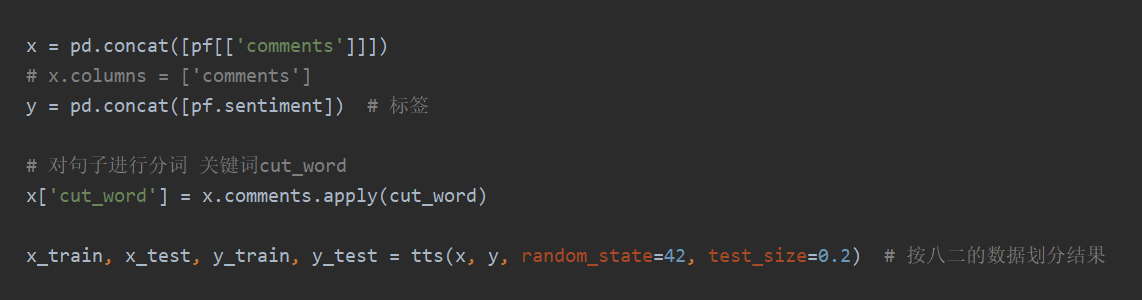
2.读取数据并做好标签

3.读取内容建立训练的字段
apply中的是分词函数,将每个句子化成词向量进行训练
tts分词的模型,test_size是测试集的大小
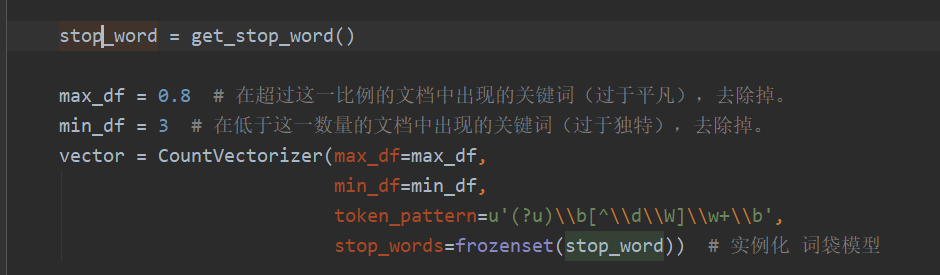
4.构建模型
其中stop_words是停用词
5.保存模型
将模型保存起来并在以后的使用中可以调用
1.导入joblib的包

2.用dump保存起来

三、模型建立
1.初始化使用的分类模型
初始化贝叶斯模型

2.训练模型建立管道保存
四、预测
1.模型预测
算出准确率
2.加载模型训练

3.结果

五、注意
在3.0.x的python版本中sklearn的导入模型有变化,参考我给出的模型包。参考链接很详细,但是导入模型有点旧,有些不能使用训练集的准确率那个包就是如此
六、参考
参考blog:http://blog.sciencenet.cn/blog-377709-1103593.html
最后根据店铺的评论数和评论关键字生成词云